Parcs informatiques (Partie 1 : LAN to LAN)
Salut à tous,
Voici la première partie du tutoriel en temps réel que je vous avais présenté. Ici, on commence à mettre les mains dans le cambouis pour corrompre fertiliser notre machine pour qu'elle puisse router les IP comme une déesse.
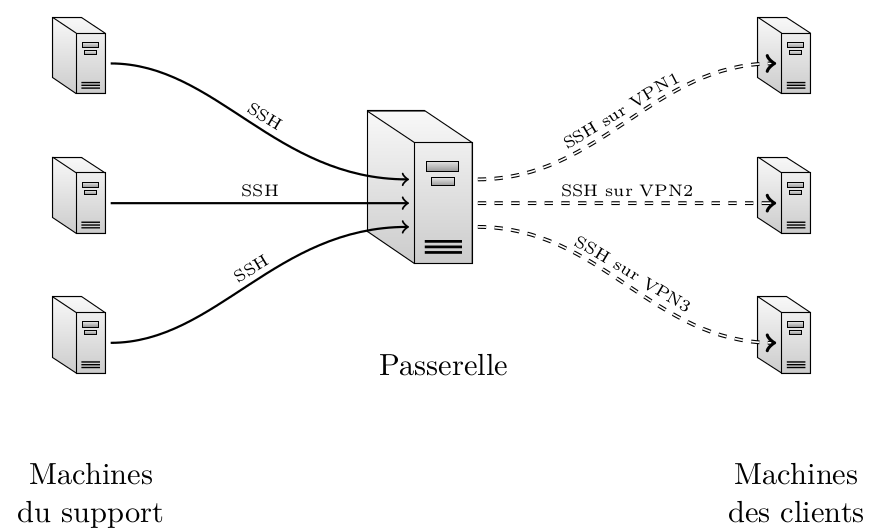
Schéma global de l'utilisation de notre passerelle
Je vous rappelle le problème. Afin que les clés SSH ne se baladent pas dans la nature, nous avons choisi d'utiliser un proxy SSH interne sur lequel se connecteront toutes les personnes qui on besoin de gérer une des machines distantes dont on a la charge. Ces machines distantes sont accessibles pour la plupart via un tunnel VPN. Et un VPN, par définition, est un moyen de créer un réseau (le N de VPN, pour network) privé (P pour private), c'est à dire inaccessible autrement sur les internets, et cela virtuellement (V pour virtual) car un "vrai" réseau se fait d'habitude physiquement, par le pouvoir et la sainte grâce du support physique brut, pur et candide (cuivre, fibre, onde électromagnétique, signaux de fumée, que sais-je encore) sans aucune intervention autre que celle d'équipements de niveau 2 dans le modèle OSI. Oui, le VPN ne sert pas qu'à télécharger illégalement des données de manière anonyme, chose qu'il fait d'ailleurs la plupart du temps très mal s'il n'est pas couplé avec d'autres techniques. Le tunnel VPN va alors se matérialiser sous la forme d'une interface spéciale sur la machine, de la forme tun ou tap, selon le protocole (pour les plus curieux, tap encapsule des frames Ethernet tandis que tun se limite à des frames IP, mais bon, on s'en tape).
Et comme les réseaux privés ne sont pas sensés être accessible de l'extérieur, les IP de ces réseaux n'obéissent à aucune pression extérieure, tels les joyeux hippies défoncés qui ont agrémenté les années 70. Ces adresses hippies sont généralement de la forme 192.168.X.X, 172.X.X.X, ou encore 10.0.X.X, ce qui fait que ces adresses hippies, même si elles s'affranchissent des ordres extérieurs, on tendance à se ressembler quand même un peu, c'est pourquoi ces tiennent également un peu du mouvement hipster.

Un exemple d'adresse IP de réseau privé.
On peut y voir tout ce que l'on veut, en bien ou en mal, mais une chose est sure, cette "hipsteritude" conduit souvent à des conflits lorsqu'il s'agit de s'y retrouver dans notre routage. En effet, imaginons, je veux envoyer un paquet à une certaine machine, je me débrouille donc pour obtenir son IP (disons l'adresse 192.168.0.2) et j'adresse ce paquet à cet IP. Seulement voilà, c'est tordant de rire, mais des IP comme ça, dans le monde, y en a des millions, et parmi mes connexions, comme j'ai pas mal de clients, il y a de fortes chances que ma machine incline là tête en arrière, me pointe du doigt et me raille méchamment. Ou alors il sera envoyé sur le premier chemin correspondant dans sa table de routage, ce qui n'est évidement pas la bonne solution. C'est ce qu'on appelle les conflits LAN to LAN.
Alors comment s'extirper de cette situation gênante ? La réponse est assez simple (en fait pas du tout) : faisons appel aux NetNS !
L'idée
Le raisonnement est le suivant : Puisqu'on ne dispose d'aucun moyen pour différencier nos IP en court-circuitant l'étape de la table de routage, eh bien utilisons plusieurs tables de routage ! C'est le rôle des NetNS (abréviation de network namespaces, ou "espaces de nommage réseau" en français). Créer un NetNS, c'est créer un nouvel ensemble de réglages réseaux, parmi lesquels des interfaces virtuelles et une table de routage toute belle toute neuve.
On peut donc ainsi cloisonner les différents réseaux virtuels qui peuvent mener des existences indépendantes, et tout ira bien dans le meilleur des mondes, pour peu que l'on exécute chaque processus dans le bon NetNS. Car oui, le beau côté de la chose, c'est que chaque processus est associé à un NetNS, par défaut au NetNS principal, c'est à dire celui qui contient les interfaces physiques.
En pratique
Les opérations suivantes s'effectuent en mode super-utilisateur ou avec la commande sudo. Soyez donc prudent, ne faites pas n'importe quoi, ne mangez pas vos enfants, la drogue c'est mal. Voilà.
On souhaite cloisonner un tunnel VPN. Pour cela on crée un NetNS que l'on nomme vpn0 par exemple. On va donc effectuer la commande :
ip netns add vpn0Ça y est, le NetNS est né ! Bon je vous avoue que tout nu comme ça, il ne va pas servir à grand chose, pour la simple et bonne raison qu'il ne contient encore aucune interface vers le monde extérieur (c'est embêtant quand on gère un réseau).
On va donc créer une interface de loopback lo (mandataire pour le bon fonctionnement de certains programmes, même si on ne s'en servira pas nous-même) et une interface main qui communiquera avec l'espace principal qui, je le rappelle, est le seul à contenir les interfaces physiques :
ip netns exec vpn0 ip link set dev lo up
ip link add nseth type veth peer netns vpn0 name mainExplications :
- La première ligne introduit la sous commande
exec: elle permet d'exécuter dans le NetNS dont le nom est fourni en premier argument une commande fournie à la suite. on exécute donc la commandeip link set dev lo updans le NetNSvpn0. - La deuxième ligne crée une paire d'interfaces : une dans l'espace principal (nommée
nseth) liée à une autre dans le NetNS nouvellement créé. Il s'agit d'un portail inter-NetNS.
On va maintenant assigner des adresse IP à ces interfaces. Eh oui, on fait comme si ces espaces étaient des machines séparées, du coup il faut mettre en place un routage IP...
Il s'agit de créer un petit réseau privé (à deux membres) avec une IP que j'ai choisie bizarre pour être sûr que personne ne l'utilise pour son adressage VPN. En théorie, un /30 suffirait, mais je vois large, et j'ai laissé un simple /24.
ip netns exec vpn0 ifconfig main 10.42.0.2/24
ifconfig nseth 10.42.0.1/24J'avoue qu'il s'agit là de la partie que je n'aime guère, le fait de créer des réseaux pour des interfaces virtuelles ne m'enchante pas vraiment. Mais je suis sur qu'il y a pire dans la vie, d'ailleurs j'ai déjà fait pire, et je referai sûrement pire (le tutoriel ne fait que commencer)...
Voilà, maintenant l'espace principal et le nouveau NetNS se connaissent mutuellement. Mais c'est pas fini. Parce que le nouveau NetNS, il ne sais pas qu'il faut passer par l'espace principal pour accéder à internet.
ip netns exec vpn0 route add default gw 10.42.0.1On ne fait qu'ajouter une entrée à la table de routage du nouveau NetNS pour lui dire "Quand tu ne sais pas ou tu vas, il faut y aller passe par l'espace principal".
En l'état, toutes les requêtes sortantes provenant du nouveau NetNS arrivent à l'espace principal, mais lui n'en a cure. Il faut alors activer la redirection IP dans l'espace principal :
sysctl -w net.ipv4.ip\_forward=1Et voilà vous pouvez taper sur n'importe quel serveur depuis votre nouveau NetNS !
Mais mais mais (parce qu'il y a un mais) ce n'est pas fini, et c'est ça, la valeur ajoutée Hashtagueule, car je n'ai trouvé aucune ressource sur le net évoquant le problème suivant : les requètes montent, pour ça, aucun problème. Mais jamais elle ne redescendrons, en tout cas pas en l'état. Vous pouvez vérifier par vous même avec la commande :
ip netns exec vpn0 ping 8.8.8.8Vous n'obtiendrez aucun écho ICMP. Pourquoi donc ?
Voyez-vous, L'IP-forwarding est bien pratique, mais il ne réfléchit pas plus que ça (et il a bien raison, car en tant normal on lui demande pas de réfléchir). Quand il reçoit un paquet qui ne lui est pas destiné, le serveur regarde dans sa table de routage vers quelle passerelle il enverrait lui-même ce paquet, et il retransmet le paquet intact. J'ai bien dit intact, c'est à dire sans modifier l'adresse source. Et l'adresse source, ben en l’occurrence c'est 10.42.0.2, une adresse bizarre que nous avons nous même attribué, une adresse interne, une adresse hippie, bref, aucune chance de routage retour.
Ce problème peut vous en rappeler un autre, enfin plus exactement le même problème mais dans un autre contexte. Si vous avez une box internet et plusieurs PC derrière, vous avez pu remarquer que vous n'avez qu'une seule IP publique, celle de votre box, et que vos PC ont chacun une IP interne. C'est exactement notre cas, sauf que nos PC ici sont virtuels (chaque NetNS auxilliaire représente l'équivalent d'un PC au point de vue réseau), et que les PC derrière une box arrivent à faire des ping à qui ça leur chante. Pourquoi ?
Eh bien, la box utilise un NAT, c'est à dire un bidule qui permet, entre autres, d'altérer des paquets sortant et de bien diriger les paquets entrants. Saux que votre box fait ça toute seule. Vu que nous on a un Linux (ouais, liberté, pouvoir au peuple, et tout et tout) on va devoir faire un NAT dans notre espace principal, qui correspond par analogie à la box. L'outil Linux pour faire un NAT s'appelle iptables, et c'est un outil assez immonde à apprendre à maitriser. Mais ne craignez rien, Hashtagueule est là pour vous tenir la main et vous écouter pleurer la nuit quand personne d'autre ne vous prête attention.
En fait, iptables est un parre-feu, c'est à dire qu'il va examiner tous les paquets venant de tous les côtés et va décider de leur sort : basiquement, les laisser passer ou les ignorer.
Pour faire du NATing, déjà, il faut activer le mode masquerade, c'est à dire la réécriture des ports entrants et sortants :
iptables --table nat --append POSTROUTING --out-interface eth0 -j MASQUERADE(en admettant que vous vous connectez à internat par l'interface eth0).
Vous pouvez définir des ensembles de règles (on les appelle des chaînes de règles), et il est recommandé de faire une chaîne spéciale pour vos NetNS, histoire de ne pas flinguer une configuration déjà existante, et dire à la chaîne principale dédiée à la redirection des paquets de prendre en considération cette nouvelle chaîne :
iptables -N netns
iptables -A FORWARD -j netnsPuis vous allez dire à votre NAT d'accepter tous les paquets impliquant l'interface virtuelle vers notre nouveau NetNS :
iptables -A netns -i nseth -j ACCEPTVoilà, vous êtes parés ! Maintenant votre NetNS peut pleinement communiquer avec Internet. Les paquets sortants seront modifiés afin de prendre l'IP publique, et les paquets entrants seront automatiquement restitués au bon NetNS.
Maintenant, pour ouvrir un VPN sans risquer de troubler votre routage (c'était le but à la base), par exemple avec OpenVPN, et ouvrir une connexion SSH sur un serveur membre de ce VPN, vous n'avez qu'à effectuer les commandes :
ip netns exec vpn0 openvpn fichier\_de\_conf.ovpn
ip netns exec vpn0 ssh mon\_serveur\_distantAstuce : pour ne pas être obligé de retaper ip netns exec vpn0 à chaque commande, vous pouvez lancer un nouveau shell dans le NetNS et bénéficier ainsi de l'hérédité de l'environnement de travail :
ip netns exec vpn0 bash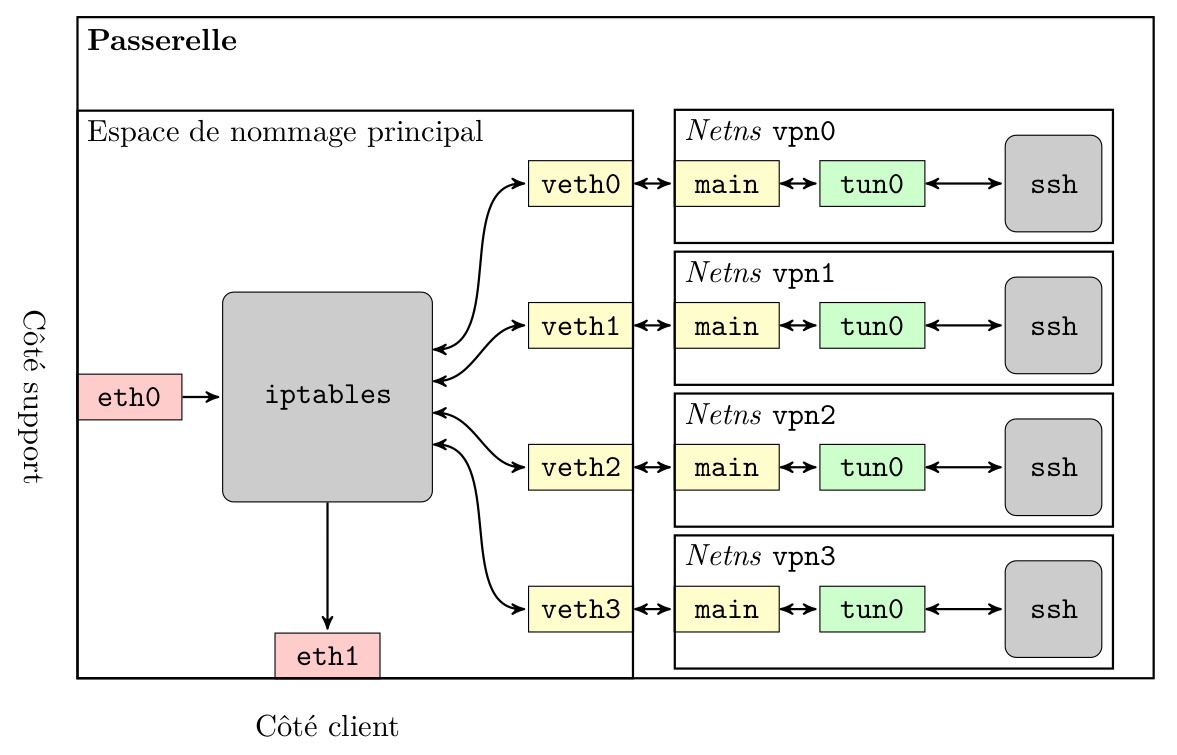
Récapitulatif du fonctionnement interne
Voilà, c'est pas beau tout ça ?
Eh bien non, ce n'est pas beau. Il y a plusieurs grands problèmes :
- Il est nécessaire de passer en super-utilisateur pour passer des commandes dans les NetNS qui nous intéresse et pour lancer des tunnels VPN.
- On ne veut pas être obligé de se rappeler d'utiliser tel ou tel protocole pour ouvrir un VPN. Il faut standardiser tout ça.
Nous verrons la solution de la standardisation des accès VPN dans la partie 2.
Restez connectés, à la prochaine.