Rappel
On part du besoin de pouvoir exécuter des machines virtuelles sur plusieurs hyperviseurs, et de pouvoir interchanger ces hyperviseurs comme bon nous semble, à chaud comme à froid, et de pouvoir parer rapidement à une défaillance de l'un d'eux.
En conséquence, d'un point de vue purement stockage, on a deux choses à gérer :
- Mise à disposition d'un point de stockage bloc unique à toutes les machines
- Partitionnement de ce stockage avec gestion de verrous
Pour le partitionnement, ma solution est de passer par un VG, ou volume group LVM, partagé à l'aide de sanlock. Cela consiste a disposer d'un petit LV (logical volume) appelé lvmlock dédié au sein de ce VG, dont le rôle est simplement de consigner qui utilise quoi afin que les hyperviseurs se se mettre à plusieurs pour modifier une partition et donc très probablement la corrompre. En effet les systèmes de fichiers traditionnels ne supportent pas les accès concurrentiels.
Au moment de l'activation d'un LV sur un hyperviseur, LVM va dire "Attends voir, je vais demander à mon démon (lvmlockd) si j'ai le droit d'utiliser ce LV". lvmlockd peut supporter plusieurs gestionnaires de verrous, dont sanlock, ce qui est notre cas. Il va donc lui demander "Hello, nous sommes l'hyperviseur numéro X, est-ce qu'on peut monter ce LV s'il te plaît ? J'en ai un besoin exclusif si possible", et donc le petit sanlock prend sa redingote, sa bougie et son lorgnon de clerc, et va consulter le registre des verrous maintenu dans le LV lvmlock. Ensuite, deux possibilités :
-
Le petit
sanlocktrouve un verrou actif sur le LV demandé, et il répond alors, l'air tout penaud : "Je suis vraiment navré, mais ce LV est déjà utilisé par une autre machine, je vous invite donc à réessayer plus tard.". Alorslvmlockdse voit contraint, non sans une certaine pointe de dépit, de devoir annuler l'activation du LV. Ce sont des choses qui arrivent. -
sanlockne trouve pas de verrou actif pour ce LV, et il répond tout guilleret : "C'est avec quand plaisir que je vous confirme que vous pouvez activer localement ce LV dès l'instant. Je vais vous inscrire au registre afin de signaler à mes confrères que cette ressources vous est exclusivement allouée jusqu'à nouvel ordre de votre part". Ce qu'il s'empresse de faire avec le très agréable sentiment de travail accompli, comme seuls les petits processus peuvent le faire.
Lorsque lvmlockd revient voir sanlock à la désactivation du LV, c'est avec le même entrain que sanlock marque le verrou comme relâché dans son grimoire.
Pour les migrations, au lieu d'un verrou exclusif, il est possible de solliciter un verrou partagé, qui a vocation bien sûr de ne pas durer.
La scène décrite a besoin d'un décor, c'est à dire ici d'un point de stockage bloc. Comme les verrous sont gérés au niveau du partitionnement, ce stockage ne s'encombre pas de contrôler qui peut accéder à quoi.
DRBD ou iSCSI ?
Les deux ont des avantages indéniables, ceux de DRBD étant de ne pas nécessiter un équipement tiers (donc moins cher) et de permettre la réplication des données sur les différents serveurs. Cependant un gros soucis de DRBD... c'est qu'il n'est pas fait pour faire du multi-master infini. La réplication devient vite très instable et j'ai eu plusieurs séances d'arrachage des derniers cheveux qu'il me reste à devoir réparer un split-brain, ce cas où la synchronisation est par terre et les serveurs se mettent à écrire sur le stockage indépendamment, et la réconciliation est très très compliquée. Personnellement je n'ai jamais eu la chance de pouvoir les réconcilier, j'ai du à chaque fois reconstruire la réplication en invalidant l'un de mes serveurs et en lui faisant recopier son copain.
J'en ai eu assez de gérer ça (et les accros de DRBD me diront qu'ils me l'avaient bien dit et que c'est bien fait pour ma tronche). J'ai donc songé à la possibilité de changer de camp et de disposer d'un SAN, et face au coup exorbitant de ces bestioles, m'en faire un moi-même avec les moyens du bord. J'avais en effet un NUC dans un coin et une baie Thunderbolt remplie de disques, le tout représentait mon ancien NAS, avant que j'achète un HP ProLient MicroServer d'occasion pour le remplacer.
Optimisation réseau
Mon principal frein était la vitesse du réseau. Pour doter mes VMs de disques acceptable, pensais-je, il me faut au moins une connexion 10 Gbps, sinon je me verrais contraint de limiter le nombre de VMs. Ça me rendait un peu triste, mais je gardais le projet dans un coin de ma tête.
Aggrégation de liens, une fausse bonne idée
Pendant une pause de midi, j'en ai parlé à un collègue de bureau qui a une longue expérience à la fois en stockage industriel et en auto-hébergement. Je lui ai fait part de mes craintes concernant le réseau, à quoi il m'a répondu ces paroles imbibées de sagesse :
Bah t'as qu'à faire de l'aggrégation de liens 1 Gbps, et même deux liens ça fera bien l'affaire.
J'ai trouvé l'idée très bonne et j'ai tenté le truc. Mon switch de coeur permet justement de faire de l'aggrégation. Mon NUC n'ayant qu'une seule carte réseau, j'ai résolu le problème en achetant deux simples adaptateurs USB-3 vers RJ45. Malheureusement j'ai appris que l'aggrégation de liens ne permet pas de multiplier le débit pour le genre de flux iSCSI. En effet, le principe de l'aggrégation est de répartir les paquets sur les différents liens selon plusieurs stratégies possibles (round-robin, équilibrage de charge, hashage...), mais une connexion TCP donnée sera toujours sur le même lien, et c'est précisément le cas d'iSCSI où il n'est question que d'une seule connexion TCP.
Cela dit, l'expérience n'était pas dénuée d'intérêt, et en cherchant j'ai trouvé une idée encore meilleure. Pour augmenter les performances d'un SAN, la meilleure stratégie n'est pas l'aggrégation de liens, mais la multiplication de réseaux de sockage, c'est ce qu'on appelle le multipath.
Le multipath
Faire du SAN multipath consiste à utiliser plusieurs chemins réseaux pour atteindre un point de stockage. Pour cela, le SAN doit disposer de plusieurs interfaces réseaux, chacune connectée à son propre réseau dédié. Dans l'idéal on disposerait de switchs séparés sur chacun desquels chaque hyperviseur aurait un lien. Cela permet à la fois la multiplication effective de la vitesse de tranfert et la résilience à une panne matérielle.
En pratique je n'ai pas de switch dédié. On se passera donc pour l'instant de la résilience matérielle. J'ai donc dédié deux VLANs dédiés auxquels j'ai assigné des ports de mon switch (en mode access) ce qui correspond à deux petits switchs isolés logiquement.
Du côté du NUC, j'ai trois interface, celle d'administration eth0 intégrée au NUC et mes deux adaptateurs USB eth1 et eth2 qui seront utilisés pour les deux réseaux de stockage. J'assigne l'adresse 10.20.5.254/24 à eth1 et 10.20.6.254/24 à eth2. Maintenant il me faut exposer le stockage sur ces deux interfaces. Le noyau Linux dispode d'un module de partage de targets SCSI contrôllable avec un outil de l'espace utilisateur appelé targetcli. Le wiki Alpine Linux dispose d'un très bon guide pour sa mise en place. Dans mon cas, j'ai créé mon backstore sur un montage RAID5 (explications dans un de mes précédents articles) avec la commande suivante :
/backstores/blockio> create block0 /dev/md0J'ai également créé non pas un portal mais deux, avec les commandes suivantes :
/iscsi/iqn.20.../tpg1/portals> create 10.20.5.254 3260
/iscsi/iqn.20.../tpg1/portals> create 10.20.6.254 3260Ce qui me donne au final un truc comme ça :
/> ls
o- / ......................................................................................................................... [...]
o- backstores .............................................................................................................. [...]
| o- block .................................................................................................. [Storage Objects: 1]
| | o- block0 ........................................................................... [/dev/md0 (8.2TiB) write-thru activated]
| | o- alua ................................................................................................... [ALUA Groups: 1]
| | o- default_tg_pt_gp ....................................................................... [ALUA state: Active/optimized]
| o- fileio ................................................................................................. [Storage Objects: 0]
| o- pscsi .................................................................................................. [Storage Objects: 0]
| o- ramdisk ................................................................................................ [Storage Objects: 0]
o- iscsi ............................................................................................................ [Targets: 1]
| o- iqn.2003-01.org.linux-iscsi.nuc.x8664:sn.a8ff70fddc94 ............................................................. [TPGs: 1]
| o- tpg1 .................................................................................................. [gen-acls, no-auth]
| o- acls .......................................................................................................... [ACLs: 0]
| o- luns .......................................................................................................... [LUNs: 1]
| | o- lun0 ..................................................................... [block/block0 (/dev/md0) (default_tg_pt_gp)]
| o- portals .................................................................................................... [Portals: 2]
| o- 10.20.5.254:3260 ................................................................................................. [OK]
| o- 10.20.6.254:3260 ................................................................................................. [OK]
o- loopback ......................................................................................................... [Targets: 0]
o- vhost ............................................................................................................ [Targets: 0]
o- xen-pvscsi ....................................................................................................... [Targets: 0]Du côté des hyperviseurs, j'ai déjà assez d'interfaces réseau, pas besoin d'adaptateurs.
eth1 |
eth2 |
|
|---|---|---|
| serveur-1 | 10.20.5.1/24 | 10.20.6.1/24 |
| serveur-2 | 10.20.5.2/24 | 10.20.6.2/24 |
Connectons nous maintenant à chacune des cibles exposées :
~# iscsiadm -m discovery -t st -p 10.20.5.254
10.20.5.254:3260,1 iqn.2003-01.org.linux-iscsi.nuc.x8664:sn.a8ff70fddc94
10.20.6.254:3260,1 iqn.2003-01.org.linux-iscsi.nuc.x8664:sn.a8ff70fddc94
~# iscsiadm -m node --targetname "iqn.2003-01.org.linux-iscsi.nuc.x8664:sn.a8ff70fddc94" --portal "10.20.5.254:3260" --login
~# iscsiadm -m node --targetname "iqn.2003-01.org.linux-iscsi.nuc.x8664:sn.a8ff70fddc94" --portal "10.20.6.254:3260" --loginUn petit lsblk confirme que deux volumes ont été ajoutés.
Maintenant il s'agit de dire à l'OS que ces deux disques sont en fait deux points d'accès au même stockage. Pour cela il faut installer le démon multipath. J'ai suivi cette doc qui explique coment l'utiliser sous debian, mais ça doit être valable partout.
Je me retrouve avec ce résultat :
~# multipath -l
mpatha (360014053221815080c24cdc938f1f56a) dm-25 LIO-ORG,block0
size=8.2T features='0' hwhandler='1 alua' wp=rw
`-+- policy='round-robin 0' prio=0 status=active
|- 6:0:0:0 sde 8:64 active undef running
`- 7:0:0:0 sdf 8:80 active undef running
~# lsblk
sde 8:64 0 8,2T 0 disk
└─mpatha 253:25 0 8,2T 0 mpath
sdf 8:80 0 8,2T 0 disk
└─mpatha 253:25 0 8,2T 0 mpath Mon volume est alors présenté sur /dev/mpatha, libre à moi maintenant d'en faire un support pour LVM. Et la procédure reprend son cours.
Conclusion
Il n'y a pas besoin d'un réseau de fou pour faire du SAN avec des VMs aux IOs raisonnables. De plus, après quelques tests à base de dd, je me suis rendu compte que les performances étaient meilleures sur mon SAN maison que sur ma partition de disque locale en cluster DRBD. En fait, ce n'est ici clairement pas le réseau qui limite, mais la vitesse de mes disques durs mécaniques.
J'ai mis en place un compte sur le Fediverse pour Hashtagueule, n'hésitez pas à suivre et à commenter là-bas ainsi que sur notre salon Matrix.
]]>Je tenais à partager une aventure amusante. Cette aventure concerne un serveur Proliant MicroServer N40L, un matériel vénérable d'une autre décennie, ressemblant un peu à une mini chaîne hifi des années 90, contenant une baie de 4 disques SATA 3,5 pouces, qui m'a été vendu par un collègue avec les 4 disques de 4 To. Les disques ont pas mal de bouteille mais les chiffres donnés par l'inspection SMART sont excellents. Du matériel idéal pour un NAS de secours.
Mon premier travail est d'ajouter un petit disque dur supplémentaire à l'emplacement prévu pour le lecteur CD/DVD afin d'y installer le système d'exploitation que je souhaite indépendant du support des données. Il existe pour ça des adaptateurs pour installer votre disque dur de façon stable.
Cela fait je souhaite m'occuper des disques destinés au RAID5 et je décide pour ça de partir sur un partitionnement GPT contenant une unique partition. Je lance donc fdisk et je constate qu'il existe déjà un paritionnement GPT, sans aucune partition cependant. Tiens, c'est marrant. Mais je ne pose pas plus de question à ce moment et je crée une première partition. Et là, fdisk m'alerte :
Partition #1 contains an ext4 signature.
Do you want to remove the signature? [Y]es/[N]o:Tiens tiens tiens, une partition cachée. Je répond donc N et par curiosité je monte la partition sans aucune difficulté. Là je trouve des noyaux Linux et des initramfs, j'ai donc affaire ici à une partition de boot.
Puis je me pose la question : Vais-je trouver les autres partitions qui se cachent sur ces disque ? Vais-je réussir à remonter le RAID qui dort ?
Je me tourne donc vers l'outil testdisk précisément conçu pour ce genre de travail. L'analyse de chaque disque révèle les partitions oubliées. Mon attention se porte particulièrement sur les partitions de type "RAID". Sur chacun des disques je sélectionne la partition en question et testdisk me propose de les inscrire dans le GPT. Je suis allé trop loin pour refuser une telle proposition. Je me retrouve donc avec 4 disques contenant chacun une partition RAID, parfaitement lisible.
Ma curiosité tourne désormais à l'excitation et j'essaye de monter le RAID à l'aide de mdadm.
mdadm --assemble --scanPremier essai infructueux, message obscur. Je regarde la sortie de dmesg et constate ceci :
md: sdc1 does not have a valid v1.2 superblock, not importing!
md: md_import_device returned -22
md: sdd1 does not have a valid v1.2 superblock, not importing!
md: md_import_device returned -22
md: sde1 does not have a valid v1.2 superblock, not importing!
md: md_import_device returned -22
md: sdb1 does not have a valid v1.2 superblock, not importing!
md: md_import_device returned -22Après un peu de recherche, je comprend que quelques métadonnées sont inexploitables (j'ignore la raison) mais peuvent être réparées sans problème, j'exécute donc :
mdadm --assemble /dev/md/debian:1 /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1 --force --update=devicesizeEt bim ! Le RAID est ressuscité et j'accède à toutes les données. Je dis bien toutes : photos personnelles, informations bancaires, résultats médicaux entre autres. Et tout ça sans grande expertise en stockage !
Je n'ai bien entendu pas exploité ces données. J'ai juste prévenu le collègue qu'à l'avenir il ferait mieux de prendre le temps d'effacer ses données plus consciencieusement.
Que faut-il en retenir ? Avec l'inflation et l'augmentation des prix, le marché de l'occasion a tendance à fleurir et c'est une bonne chose ; cependant ce genre de situation est appelé à se reproduire. Il est important que chaque personne cédant du matériel stockant de l'information prenne conscience du risque de fuite de données personnelles, et donc prenne le temps d'apprendre à les effacer efficacement avant de se séparer de ce matériel.
]]>En programmation, on est souvent amené à produire un résultat ayant une forme prédéfinie, mais du contenu variable. C'est particulièrement vrai pour les sites web et blogs, dont les pages et les articles doivent respecter une mise en page uniforme et des éléments en commun, comme le menu de navigation, la charte graphique, les pieds de pages... C'est aussi vrai pour générer des fichiers de configuration, par exemple grâce à Ansible, dont on est sûr qu'ils respectent tous la même syntaxe, ce qui permet de mettre de côté le facteur humain, connu pour sa nature erratique.
La forme prédéfinie utilisée par ces techniques est appelée un template (ou modèle en français). On utilise alors un moteur de templating à qui on fournit du contenu d'un côté, un template de l'autre, et en sortie on trouvera le résultat mis en forme, notre fameuse page HTML ou fichier de configuration par exemple. On dit alors qu'on fait un rendu d'un template.
Les pythonistes utilisent principalement le moteur Jinja2 (c'est le cas pour Ansible et le moteur par défaut de Django), les PHPistes se tournent plutôt vers twig, qui a commencé en s'inspirant de Jinja2. Tous les deux ont beaucoup de fonctionnalités et disposent d'un méta-langage rappelant les langages de programmation : boucles, conditions, fonctions...
Utilisation basique
Des fonctionnalités qui sont inutiles dans certains cas d'usages. Parfois, on a uniquement envie de placer le contenu de variables à des endroits donnés, et basta. On a pas besoin de boucler dans des structures complexes ou d'utiliser des conditions. Pour ces usages basiques, vous avez probablement déjà l'outil installé sur votre distribution, il s'agit de l'outil GNU envsubst, présent dans les outils gettext (paquet gettext-base sous Debian).
J'ai utilisé envsubst lorsque j'ai développé pour mon entreprise un ensemble de scripts permettant de gérer des accès au VPN Wireguard permettant d'accéder à distance aux ressources nécessaires pour travailler. Ces scripts permettent de mettre à disposition des utilisateurs des fichiers de configuration qu'ils doivent fournir à leur client.
Je ne m'étendrai pas sur le fonctionnement de ces scripts (ni sur les considérations de sécurité nécessaires), ce sera peut-être l'objet d'un autre article. Je parlerai uniquement du templating qui y est opéré pour permettre à l'utilisateur de récupérer sa configuration, lorque la paire de clefs a été générée et l'IP interne attribuée.
À ce stade j'ai besoin de quelques variables :
$client_privkeycontenant la clef privée de l'utilisateur.$client_ipcontenant son adresse IP.$server_pubkeycontenant la clef publique du serveur.$server_endpointcontenant la clef publique du serveur.$allowed_ipscontenant les intervalles d'IP prises en charge par le tunnel.$dnscontenant l'IP du serveur DNS interne.
Mon template envsubst est le suivant (fichier userconf.tpl) :
[Interface]
PrivateKey = ${client_privkey}
Address = ${client_ip}
DNS = ${dns}
[Peer]
PublicKey = ${server_pubkey}
Endpoint = ${server_endpoint}
AllowedIPs = ${allowed_ips}
PersistentKeepalive = 25Remarquons que seules les variables $client_privkey et $client_ip varient selon l'utilisateur, et que j'aurais très bien pu directement inscrire la valeur des autres variables directement dans le fichier. Néanmoins ce code n'aurait pas été très propre ni portable.
Dans mon script, pour effectuer le rendu de ce template, j'ai les instructions suivantes :
export client_privkey client_ip server_pubkey server_endpoint allowed_ips dns
cat template/userconf.tpl | envsubst > generated_conf/${username}.confAinsi, si mon nom est raspbeguy, le fichier raspbeguy.conf contiendra mon fichier de configuration personnel, il ne me reste plus qu'à le télécharger (et à le supprimer du serveur pour des raisons de sécurité).
Si ça ne suffit pas
envsubst est vraiment très pratique car il est très simple et permet de ne pas dépendre de tout un tas de bibliothèques lourdes.
Cependant vous pouvez être amené a avoir réellement besoin d'un moteur de templating complet comme Jinja2, ne serait-ce que pour itérer des des listes d'objets par exemple. Il n'y a pas vraiment d'outil intermédiaire qui vaille le coup à ma connaissance.
Il existe un outil, présent dans les dépôts Debian, permettant de faire des rendus de templates Jinja2 directement en ligne de commande.
apt install j2cliCe paquet fournit un exécutable j2 qui accepte d'être fourni en variable suivant plusieurs méthodes, notament en piochant directement dans les variables d'environnement (comme envsubst) ou bien via des syntaxes répendues comme les format JSON, INI ou YAML. Notament, si vous voulez passez des listes ou des dictionnaires à cet outil, vous serez obligé de passer par ces syntaxes.
Cet outil vous offre toutes les fonctionnalités du moteur Jinja2.
Conclusion
Je pense qu'il est toujours préférable de se tourner en priorité vers des outils simples. Un bon projet est un projet qui ne demande pas tout l'univers en dépendances.
]]>Le problème
Comme vous le savez, lorsqu'un navigateur souhaite obtenir une page d'un site internet, il fait ce qu'on appelle une requête HTTP. Cette requête contient entre autres un certain nombre d'en-têtes, dont un qui s'appelle Host.
Cet en-tête permet de signaler au serveur web quel est le site internet qui est interrogé, dans le cas où ce serveur web sert plusieurs sites à lui tout seul.
Par exemple, pour consulter Hashtagueule, votre navigateur emet une requête HTTPS sur le port 443 du serveur Hashtagueule avec un Host qui ressemble à ça :
Host: hashtagueule.frLe serveur regarde alors la liste des sites qu'il peut servir, il trouve le bon, et il renvoie le contenu demandé par la requête.
Ce que j'ignorais jusqu'alors, c'est que cet en-tête peut contenir de manière facultative le numéro de port distant. Pour Hashtagueule, cela donnerait :
Host: hashtagueule.fr:9091Je ne comprends pas très bien pourquoi le numéro de port peut être inclus dans cet en-tête. D'autant plus que dans la pratique, les navigateurs incluent ce numéro de port dans certains cas seulement. D'après mes tests sous Firefox et curl (sans forcer l'en-tête avec l'option -H) :
- Si le numéro de port correspond au port standard du protocole (80 pour HTTP, 443 pour HTTPS), alors ce numéro de port est omis de l'en-tête (et même si vous ajoutez ce numéro de port dans votre barre d'URL).
- Si le numéro diffère du port standard, il est inclus dans l'en-tête.
Autrement dit, pour l'immense majorité des sites internet, ce numéro de port n'est jamais inclus. Ça explique comment on peut passer à côté de cette réalité.
Certains serveurs web comme nginx vous évitent de vous en soucier et font abstraction de ce numéro de port lorsqu'ils font la correspondence entre requête et site.
Par contre, d'autres comme HAProxy ne le font pas par défaut, et donc si vous n'êtes pas conscient de cela, vous risquez d'avoir des problèmes.
L'apprentissage par l'échec
J'utilise le programme Transmission sur mon serveur à la maison en mode "headless" (c'est à dire sur un serveur distant, avec une interface web). Celui-ci écoute d'habitude sur un port non standard, le port 9091. Cependant je l'ai placé derrière mon preverse proxy qui s'avère être HAProxy, ainsi tous mes sites HTTPS utilisent le port standard 443. Donc pour accéder à l'interface (et à l'API) de Transmission dans mon cas, il faut passer par le port standard 443.
tremotesf est une application Android qui se connecte à l'API de votre instance Transmission pour vous permettre de la contrôler, avec une interface sympa.
C'est en utilisant cette application que j'ai découvert le soucis : toutes les requêtes émises par cette application ont un en-tête Host contenant le numéro de port, qu'il soit standard ou non. Dans mon cas, donc, cela donnait ça :
Host: transmission.example.com:443N'ayant pas prévu le coup, mon HAProxy était configuré pour mettre en correspondance Transmission avec le Host transmission.example.com, mais ne savait que faire avec le Host transmission.example.com:443.
La solution
Elle tient en une seule ligne, à placer dans la section Frontend :
http-request replace-header Host ([^:]+) \1Cette directive dit simplement de supprimer les deux points et tout ce qui se trouve après, c'est à dire le numéro de port. On retombe donc bien sur un Host sans numéro de port.
Ainsi on ne m'y reprendra plus.
]]>Quand nous avons créé le site Hashtagueule, nous voulions éviter de parler d'argent dessus. À titre personnel, je pense qu'on parle bien assez d'argent partout ailleurs et je voulais un petit coin de paradis qui ne soit pas pollué par de basses questions matérielles.
Je vais faire une exception aujourd'hui, car oui, héberger un site coûte de l'argent.
Rassurez-vous, nous ne sommes pas au bord de l'extinction du blog. Cependant, le site est porté par deux personnes, Motius et moi-même, et alors que lorsque nous avons commencé à écrire, nous étions jeunes et insouciants, nous commençons désormais à avoir des vies de familles. Cela veut dire que nous avons plus de choses plus importantes à nos yeux que les finances du blog.
Le serveur hébergeant Hashtagueule est chez OVH et coûte une soixantaine d'euros par mois (mais nous l'utilisons également pour beaucoup d'autres choses). Ces frais pourraient être réduits en rappatriant le site directement à domicile, ce qui sera fait dès lors que la fibre sera installée chez moi...
J'ai donc décidé d'ouvrir une page Liberapay pour permettre aux lecteurs de contribuer financièrement au blog.
Surtout, gardez à l'esprit que nous ne souhaitons pas recevoir d'argent pour écrire des articles. C'est une activité récréative, c'est important pour nous qu'elle reste bénévole. Cet argent est uniquement destiné au maintien de l'infrastructure du site.
Vous trouverez notre page de don dans la barre latérale ou à la fin de cet article.
Je vous remercie et ferme maintenant cette parenthèse "finance".
]]>Depuis quelques semaines, on me rabache les oreilles à propos d'un truc qui n'est pas le web. Bien entendu, beaucoup de choses ne sont pas le web. Voici une liste non exhaustives de choses qui ne sont pas le web :
- un gâteau au chocolat
- l'Arc de Triomphe
- des chaussures de sport
- la révolution industrielle
- la COVID-19
On pourrait aller bien plus loin si on voulait.
En fait, c'est l'un des premiers éléments de présentation de Gemini : ce n'est pas le web. Mais alors qu'est-ce que c'est ?
Ce qui n'est pas le web
Au début des années 90, alors qu'Internet avait été inventé, mais alors utilisé en grande partie par des bandes d'universitaires boutonneux pour faire des trucs d'intellos, plusieurs idées ont germé en parallèle dans le monde pour mettre au point un moyen de consulter des informations sous forme de pages navigables.
L'une de ces idée venant d'Europe est le protocole HTTP, couplé au format HTML, qui forment ce qu'on appelle aujourd'hui le web.
Ce qu'on sait moins, c'est que d'autres protocoles ont vu le jour à peu près en même temps, notamment le protocole Gopher, mis au point aux États-Unis. Ce protocole était vraiment minimaliste (même si HTTP l'était presque autant à l'époque) et se couplait le plus souvent avec du contenu en texte simple.
Au bout d'un certain temps, le web a fini par l'emporter, notament à cause de l'intégration d'image dans les documents HTML, et le monde Gopher s'est réduit à peau de chagrin et est complètement délaissée par l'industrie.
Certains irréductibles continuent de servir des sites Gopher. L'argument de ces derniers des Mohicans, c'est la légèreté des sites Gopher par rapport aux sites web d'aujourd'hui : un site Gopher n'est que du texte : pas d'image, pas de mise en forme, pas de distractions. Ça fonctionne bien pour présenter de l'information austère.
La relève
Gemini est une initiative récente pour tenter de relancer cette contre-culture Internet. Il s'agit à la fois d'un protocole au même titre que HTTP et Gopher, et d'un format de mise en forme, au même titre que HTML et le... texte simple. Sur la page du projet (côté Gemini, gemini://gemini.circumlunar.space/), il se présente comme "plus lourd que Gopher, plus léger que le web". Le but ici est de prioriser la légereté, mais également la vie privée, en prohibant les mécanismes classiques de traçage utilisés sur le web.
Côté protocole, à l'inverse de HTTP qui compte en moyenne une bonne grosse marmite d'en-têtes (y compris ceux concernant les fameux cookies), Gemini ne s'autorise qu'un seul en-tête, permettant de préciser le type de contenu servi. Une requête Gemini ne contient pas de verbe type GET, POST, etc. Uniquement l'URL. Et c'est à peu près tout ce qu'on peut en dire. Ah si, le chiffrement TLS des pages est obligatoire, et les certificats sont pour la plupart auto-signés, dans un fonctionnement TOFU (Trust On First Use). Un choix pas anodin, on en reparlera.
TOFU sur Wikipedia (en anglais)
Côté format de contenu, Gemini privilégie le Gemtext, un format mis au point par le projet dérivé de Markdown. Enfin, un Markdown vraiment dépouillé. La différence avec le Markdown est l'interdiction des liens dans un paragraphe en les déplaçant sur leur propre ligne bien isolée (comme les liens dans le présent article) et l'impossibilité d'intégrer des images autrement qu'en mettant des liens normaux. C'est un peu spartiate mais c'est quand même un peu plus beau que du texte brut. Les détails du Gemtext sont à retrouver sur la page Gopher du projet.
Naviguer sur Gemini
Si on a du contenu navigable, alors il faut un navigateur. Non, vous ne pourrez pas aller sur un site Gemini (les gens du milieu aiment bien les appeler des capsules) avec votre Firefox. Ou alors si, mais en passant par une passerelle qui convertit le contenu Gopher en HTTP/HTML.
Il existe plusieurs navigateurs Gemini. Les deux qui ont retenu mon attention sont :
- Lagrange : c'est un navigateur graphique très esthétique. Je le trouve visuellement très plaisant.
- amfora, en ligne de commande.
Ce que je pense de Gemini
Le web a bien des défaut. Il vous traque, il consomme beaucoup de ressources. Et la plupart du temps, lorsque que vous essayez de ne prendre que ce qui vous intéresse en éliminant les ressources inutiles, vous finissez avec une page immonde et vraiment pas agréable.
L'idée d'un web basé sur du markdown et laissant le soin de la mise en page au le client est présente dans ma tête depuis un certain temps. Quand on m'a parlé de Gemini, j'ai été immédiatement intéressé.
Cependant je suis contrarié par plusieurs points.
Pour moi, même si je suis vraiment satisfait de ce minimalisme, je pense qu'il est complètement inutile de créer un nouveau protocole. À mon sens, il aurait été bien plus intéressant de développer le format Gemtext sur HTTP, et de mettre au point des navigateurs (ou en adapter des existants) pour y mettre un mode ou il n'interprète qu'un nombre bien restraints d'en-têtes.
Développer Gemini sur du HTTP, cela aurait permis deux choses :
- Pouvoir utiliser les infrastructures existantes pour relayer du Gemini. Il n'existe pas encore d'équivalent à HAproxy pour Gemini.
- Rendre les navigateurs existants compatibles, quitte à avoir une mise en page un peu dégueu.
Parlons maintenant des certificats. Selon les créateurs de Gemini, le système de validation des certificats par des autorités de certification est dangereux, car il suffit qu'une autorité soit mise à mal pour corrompre l'ensemble des sites qu'elle a certifié.
Oui, le système des autorités de certification n'est pas parfait. Mais pour la navigation sur des serveurs a priori inconnu, cela reste mille fois mieux que le principe TOFU.
Le mode TOFU est celui adopté par SSH : à la première connexion, la signature de la connexion est enregistrée et pour les connexions suivantes, on vérifie que la signature n'a pas changé, et si elle a changé, on affiche un avertissement.
Pour SSH, cela fait sens. On ne se connecte pas à n'importe quel serveur : normallement, on vérifie que la signature de la première connexion est effectivement la bonne car il s'agit de nos propres serveurs ou ceux d'un ami/collègue. En bref, avec SSH, si on fait les choses bien, on n'accepte pas aveuglément un certificat. Pour la navigation, on est susceptible de pouvoir se connecter sur n'importe quel serveur proposant un serveur Gemini, tenu par des gens inconnus. Là il n'est plus question de pouvoir vérifier quoi que ce soit. Il faut juste espérer que la première connexion a été bonne, et croiser les doigts. Je sais pas pour vous, mais moi ça me met très mal à l'aise.
Nous avons quand même franchis le pas et à titre d'expérience, nous vous proposons notre capsule Gemini, pour ce que cela vaut, sur gemini://hashtagueule.fr.
Merci de votre attention.
]]>On pourrait débattre longtemps sur la décision du déploiement de la 5G. On le fera probablement, mais pas tout de suite. Là maintenant c'est à propos de santé que je vais vous parler. Et non, pas de rapport avec la COVID-19.
Le gouvernement travaille depuis un certain temps sur un projet qu'on appelle la Platerforme de Données de Santé (en anglais Health Data Hub). L'idée derrière tout ça est de centraliser et rationaliser les informations de santé de toute la France, ce qui passe entre autres par y mettre un petit coup d'intelligence artificielle.
Dans l'idée ça pourrait être une bonne idée, cela permettrai d'encadrer les décisions médicales, de faciliter la recherche et de suivre la santé de la population au niveau national. C'est d'ailleurs sur cette infrastructure que s'appuie l'outil StopCovid, dans les condition et l'absence de succès que nous connaissons.
C'est un projet ambitieux sans aucun doute. C'est à ce stade que la route devient glissante. En effet il était prévu, jusque tout récemment, que cette platerforme repose sur Microsoft Azure, donc des données américaines et une entreprise suhette à nombre controverses.
Plusieurs remarques doivent venir à l'esprit :
- Lobbying : L'État français ne respecte pas le procédé règlementaire pour ce projet, qui impose de passer par un cahier des charges et un appel d'offre publique.
- Communication : Par le choix d'une plateforme étrangère et non-européenne, l'État statue que la France et l'Europe n'ont pas la compétence pour assurer techniquement un tel projet.
- Souveraineté numérique : Les données seraient donc sous la juridiction américaine, donc non protégées par le RGPD et soumises à toutes sortes d'atrocités juridiques comme le Cloud Act et le Patriot Act, qui permettent en gros à l'État américain de faire ce qu'il veut avec ces données.
- Vulnérabilité des données : Rien ne permettrait de vérifier que Microsoft ne fait pas d'usage commercial de ces données.
- Économie : Encore une fuite d'argent publique vers un pays étranger qui n'en a pas besoin et sans véritable raison.
La décision avait provoqué un soulèvement tant au niveau des associations et organismes de protection de la vie numérique que de l'industrie hexagonale. Octave est fou de rage. Une pétition au Sénat a été lancée. Des sourcils ont été froncés.
Il semblerait que la polémique ait porté quelques fruits et que l'État envisage un rétropédalage.
On a donc l'air de s'éloigner du ravin, mais on a bel et bien senti le vent du boulet. Vous pouvez toujours signer la pétition, juste au cas où.
]]>Aujourd'hui, je veux vous parler d'une bibliothèque Python3 :
jsonpath2.
Un peu de contexte
Il s'agit d'une petite bibliothèque de code qui permet de filtrer des données au format JSON. Vous me direz, on peut déjà faire ça avec des petites fonctions utilitaires, quelques coups de liste en compréhension. Il y a bien sûr un grand nombre de choses que la bibliothèque ne permet pas de faire, on y reviendra, mais concentrons-nous d'abord sur ce qu'elle permet, et les avantages qu'elle procure.
Pour cela, je vous propose tout simplement de vous présenter l'exemple que j'ai eu à traiter.
Un exemple
Supposez que vous ayez comme moi une application qui écrive un journal
d'exécution au format JSON, dont les entrées sont relevées périodiquement par
un ELK, et que vous ayez à analyser
une journée complète, ce qui vous donne environ 50 Mo de logs compressés en
gzip, et 700 Mo une fois décompressés. Vous rentrez ça dans un interpréteur
ipython et bam, 3 Go de RAM supplémentaires utilisés. (Dans les cas où vous
utilisez beaucoup de mémoire dans ipython, rappelez-vous que celui-ci stocke
tout ce que vous taper dans des variables nommées _i1, _i2... et les
résultats de ces opérations dans les variables correspondantes _1, _2, ce
qui peut faire que votre interpréteur consomme une très grande quantité de
mémoire, pensez à la gérer en créant vous-même des variables et en les
supprimant avec del si nécessaire. Mais je m'égare.)
Il peut y avoir plusieurs raisons qui font que ces logs ne seront pas complètement homogènes :
- vous avez plusieurs applications qui fontionnent en microservices ;
- les messages comportant des exceptions ont des champs que les autres messages plus informatifs n'ont pas ;
- etc.
Toujours est-il que pour analyser ce JSON, vous pouvez être dans un beau pétrin au moment où vous vous rendez compte que chacune des petites fonctions utilitaires que vous écrivez doit :
- gérer un grand nombre de cas ;
- gérer des cas d'erreur ;
- être facilement composable, même pour les cas d'erreur.
Je ne dis pas que ce soit infaisable, et il m'est arriver de le faire ainsi pour certaines actions plutôt qu'en utilisant JsonPath.
Pour l'installation, c'est comme d'habitude dans le nouveau monde Python :
# dans un virtualenv Python3
pip install jsonpath2Cas pratiques
Exemple de code n°1
Par exemple, si je souhaite obtenir toutes les valeurs du champ message où
qu'il se trouve dans mon JSON, je peux le faire ainsi :
import json
from jsonpath2.path import Path as JsonPath
with open("/path/to/json_file/file.json", mode='r') as fr:
json_data = json.loads(fr.read())
pattern = "$..message"
ls_msg = [
match.curent_value
for match in JsonPath.parse_str(pattern).match(json_data)
]La variable qui nous intéresse ici, c'est pattern. Elle se lit ainsi :
$: racine de l'arbre analysé..: récursion sur tous les niveauxmessage: la chaîne de caractères recherchés
Avantage
Le premier avantage que l'on voit ici, c'est la possibilité de rechercher la valeur d'un champ quelle que soit la profondeur de ce champ dans des logs.
Exemple de code n°2
On peut aussi raffiner la recherche. Dans mon cas, j'avais une quantité de
champs "message", mais tous ne m'intéressaient pas. J'ai donc précisé que je
souhaitais obtenir les champs "message" seulement si le champ parent est, dans
mon cas, "_source" de la manière suivante :
pattern = "$.._source.message"Par rapport au motif précédent, le seul nouveau caractère spécial est :
.: permet d'accéder au descendant direct d'un champ.
Avantage
L'autre avantage qu'on vient de voir, c'est la possibilité de facilement rajouter des contraintes sur la structure de l'arbre, afin de mieux choisir les champs que l'on souhaite filtrer.
Exemple de code n°3
Dans mon cas, j'avais besoin de ne récupérer le contenu des champ "message"
que si le log sélectionné était celui associé à une exception, ce qui
correspondait à environ 1% des cas sur à peu près 600 000 entrées.
Le code suivant me permet de sélectionner les "message" des entrées pour
lesquelles il y a un champ "exception" présent :
pattern = "$..[?(@._source.exception)]._source.message"Il y a pas mal de nouveautés par rapport aux exemples précédents :
@: il s'agit de l'élément couramment sélectionné[]: permet de définir un prédicat ou d'itérer sur une collection?(): permet d'appliquer un filtre
Avantage
On peut facilement créer un prédicat simple pour le filtrage d'éléments, même lorsque l'élément sur lequel on effectue le prédicat n'est pas le champ recherché in fine.
Au sujet de jsonpath2
Si vous êtes intéressé par le projet, je vous mets à disposition les liens suivants (ils sont faciles à trouver en cherchant un peu sur le sujet) :
- un article présentant le filtrage JSON d'après l'équivalent XPath pour XML ;
- le lien vers PyPI de la bibliothèque
- le lien GitHub de la bibliothèque
- le lien vers une implémentation JavaScript populaire de JsonPath.
jsonpath2 utilise le générateur de parseur ANTLR,
qui est un projet réputé du Pr. Terence Parr.
Inconvénients
Parmi les prédicats qu'on peut faire, on peut tester si une chaîne de caractères est égale à une chaîne recherchée, mais les caractères qu'on peut mettre dans la chaîne recherchée sont assez limités : je n'ai pas essayé de faire compliqué, seulement de rechercher des stacktraces Python ou Java, qui ont peu de caractères spéciaux.
Il paraît qu'on peut effectuer des filtrages plus puissants avec une fonctionnalité supplémentaire que je n'ai pas présentés parce que je n'ai pas pris le temps de l'utiliser :
(): s'utilise afin d'exécuter des expressions personnalisées.
J'espère que tout ceci pourra vous être utile. Je vous recommande notamment de tester vos motifs sur un petit jeu de données, on peut facilement faire des bêtises et consommer beaucoup de mémoire et pas mal de temps sans cela.
Joyeux code !
Motius
]]>Aujourd'hui, je veux vous parler des dictionnaires en Python, et notamment de leur — relativement — nouvelle propriété d'ordre.
TL;DR: les considérations concernant les dictionnaires ordonnés tourne autour des performances. On oublie de mentionner que cela facilite le débogage, mais que cela peut aussi cacher un bogue dans l'implémentation d'un algorithme, raison pour laquelle j'ai écrit le fragment de code ci-dessous.
Un peu de contexte
Si l'on en croit ce thread StackOverFlow, les clefs d'un dictionnaire dans Python3 depuis sa version 3.6 sont de facto ordonnées dans l'implémentation CPython (dans l'ordre d'insertion), et Python3 dans sa version 3.7 standardise cet état de fait, ce qui veut dire que les autres implémentations (PyPy, Jython...) devront s'aligner afin de correctement implémenter le nouveau standard, pour assurer la compatibilité du code entre "interpréteurs". (Je mets le lien StackOverFlow parce qu'il en contient d'autres vers la liste de diffusion de courriel, etc.)
Si vous vous demandez ce qui a amené à cet état de fait, je vous recommande la vidéo suivante, par le curieux Raymond Hettinger.
Avec ça, vous aurez des éléments pour évaluer la pertinence des dictionnaires ordonnées en Python.
Notez, pour ceux qui n'ont pas regardé la documentation, que Python3 met à disposition un OrderedDict déjà disponible dans les versions antiques, antédiluviennes, je veux dire celles pré-3.4 (oui, je trolle, mais à peine).
Le problème
Voyons un peu le contexte des deux problèmes qui m'ont amené à écrire cet article.
Scénario 1
J'étais en train de déboguer un logiciel, appelons-le Verifikator, qui faisait des appels API afin de vérifier des données en bases. Il se trouve que les résultats de Verifikator étaient aléatoires. De temps en temps, il retournait les bons résultats, i.e. il indiquait que certaines données en base étaient invalides, et de temps en temps, Verifikator n'indiquait pas d'erreur, alors qu'on pouvait vérifier a la mano qu'il y avait effectivement une erreur en base. Pour faire simple, la raison pour laquelle Verifikator n'était pas déterministe, c'est qu'il dépendait de l'ordre d'un dictionnaire dont la donnée provenait de l'API de la base de données. Vous comprenez que j'exagère quand je dit que Verifikator n'était pas déterministe, il l'est heureusement, puisqu'il s'agit d'un système informatique, et qu'on néglige les rayons cosmiques et les bogues système.
Je me permet de rappeler à ceux d'entre vous qui s'étonnent de ce comportement erratique de Verifikator que j'étais en train de le déboguer (qui plus est, j'avais seulement participé à sa conception, pas à son implémentation).
Verifikator tourne en Python3.5, si l'on avait utilisé une version supérieure, on n'aurait pas eu ce problème, notamment, Verifikator aurait soit systématiquement planté, soit systématiquement fonctionné. Ç'eût été mieux afin de pouvoir localiser le bug par dichotomie, je vous avoue que mon état de santé mentale se dégradait à vu d'œil lorsque j'ai commencé à observer ce comportement aléatoire, en cherchant à localiser les lignes fautives par dichotomie.
Je reviens un instant sur cette histoire de dichotomie pour bien faire sentir à quel point c'est fatiguant. Imaginez un peu, vous essayez de déterminer un point A où le programme est dans un état valide et un point B dans lequel l'état est invalide, puis vous regardez un nouveau point C "au milieu", afin de savoir si ce point C est le nouveau point valide A' ou bien le nouveau point B' pour l'itération suivante. Le problème, c'est que parfois vous pensez que l'état du programme est valide à ce point C, mais que ce n'est pas vrai en général. Vous continuez donc à itérer entre C et B, alors que le problème se trouve entre A et C.
Vous comprenez pourquoi j'apprécie fortement le fait que les dictionnaires soient ordonnés pour le débogage.
Mais. Comme vous imaginez, il y a un mais. Parce qu'il n'y a pas que des avantages aux dictionnaires ordonnés. C'est le sujet du second scénario.
Scénario 2
Dans d'autres circonstances, j'ai déjà écrit — j'étais l'auteur du code cette fois-là, contrairement à Verifikator — un algorithme qui ne fonctionnait que si le dictionnaire sur lequel il tournait était ordonné. J'utilisais Python3.6 à l'époque, et par conscience professionnelle, j'ai compilé les versions 3.4 à 3.7 de Python afin de vérifier que les tests étaient corrects avec ces interpréteurs. Quelle ne fut pas ma surprise quand je m'aperçus que ce n'était point le cas. Ce n'était même pas le nouvel Python3.7 encore en bêta qui posait problème, mais les version 3.4 et 3.5. J'ai donc réécrit cet algorithme afin qu'il ne dépende plus de l'ordre du dictionnaire d'entrée (très simplement en construisant un OrderedDict à partir du dictionnaire et d'une liste correctement triée).
Conséquences
À l'époque, je n'avais pas rajouté de code pour tester les fonctions de service du second programme, je m'assurai qu'il fonctionnait avec les 4 versions mineures de Python3 pour lesquelles je développais le programme.
J'ai fait les choses différemment cette fois, puisque j'ai codé cette fonction, qui randomise les clefs d'un dictionnaire plat (fonction non récursive sur d'éventuels dictionnaires en valeurs du dictionnaire passé en argument).
import random as rnd
def shuffle_dict_keys(d: dict) -> dict:
"""shuffle the keys of a dictionary for testing purposes now that
Python dictionaries are insert-ordered. Does not compute inplace.
Does not work recursively.
"""
res = {}
l = list(d)
rnd.shuffle(l)
for k in l:
res[k] = d[k]
return resJ'avais en tête cette planche XKCD en écrivant ce code. Non pas que je préfère l'ancien comportement, mais que pouvoir y souscrire de manière optionnelle me permet d'avoir des tests de meilleure qualité, et qu'il a donc fallu queje trouve un contournement afin de retrouver l'ancien comportement dans les cas de tests.
Conclusion
De manière générale, je suis assez content que les dictionnaires soient ordonnés, mais je ne m'attendais pas à rencontrer de tels écueils, notamment puisque la majorité des conversations que j'avais lues sur le sujet s'attardaient sur les performances de cette nouvelle implémentation, et non sur ce genre de considérations.
Joyeux code !
Motius
]]>Aujourd'hui, je vous propose un micro tutoriel pour créer un enum dynamiquement en Python.
Je vous accorde qu'on ne fait pas ça tous les jours, c'est d'ailleurs la première fois que je suis tombé sur ce cas.
Un peu de contexte
En général, un enum, ça ressemble à ça en Python :
class MonEnumCustom(enum.Enum):
"""docstring
"""
VALIDATION = "VALIDATION"
SEND = "SEND"Si l'enum contient un grand nombre de valeurs, chacune correspondant à un état, on peut aisément les formater avec un programme, afin d'écrire un enum comme ci-dessus.
Ça fait simplement un enum comme ci-dessus, mais en plus gros :
class MonEnumCustom(enum.Enum):
"""docstring
"""
VALIDATION = "VALIDATION"
SEND = "SEND"
COMMIT = "COMMIT"
REVIEW = "REVIEW"
... # une centaine d'états supplémentaires disponiblesMais que faire quand on récupère les valeurs dynamiquement depuis un appel à une API, qui retourne l'ensemble des états possibles sous forme d'une collection, comme ceci :
>>> ls_remote_states = fetch_all_states(...)
>>> print(ls_remote_states)
[
"VALIDATION",
"SEND",
"COMMIT",
"REVIEW",
...
]et que l'on souhaite créer un enum à partir de ladite collection afin d'écrire du code qui dépendra de valeurs d'états prise dans l'enum comme ci-dessous ?
# pseudo-code
ls_remote_states = fetch_all_states(...)
MonEnumCustom = create_enum_type_from_states(ls_remote_states)
# dans le code
if state is MonEnumCustom.VALIDATION:
print("En cours de validation")
elif state is MonEnumCustom.COMMIT:
...
else:
raiseC'est le sujet de la discussion qui suit, qui va présenter les options disponibles, et quelques considérations quant à leurs usages.
Le scénario
Je souhaitais pouvoir m'interfacer avec un service qui définit un grand nombre (un peu plus d'une centaine) de constantes qu'il me renvoie sous forme d'une collection de chaînes de caractères. Trois choix s'offraient ainsi à moi :
-
utiliser les constantes telles quelles dans une collection (
list,dict...)Avantages :
- rapide & facile
Inconvénients :
- sémantiquement pauvre
- la liste des états valides n'est jamais écrite dans le code
-
faire un copié collé et du formatage (avec vim, c'est facile et rapide)
Avantages :
- rapide & facile
- l'intégralité des valeurs connues de l'
enumpeuvent être lues dans le programme à la seule lecture du code
Inconvénients :
- duplique un
enumdont je ne suis pas responsable
-
générer dynamiquement l'
enumAvantages :
- résout les inconvénients des solutions précédentes
- évite la duplication de code inutile.
Il arrive assez souvent que l'on doive définir un même
enumà plusieurs endroits dans un système informatique, par exemple en base de donnée dans Postgre, puis en Java / Python, et enfin en Typescript si vous faites du développement sur toute la stack. Mais dans ce cas-ci, j'aurais redéfini un enum sans que mon code ne soit la source d'autorité sur celui-ci, ce qui contrevient au principe du Single Source of Truth, c'est donc plus gênant que le simple problème de duplication de code. - Plus facile à adapter lors de l'évolution de l'
enum. Ce dernier point est vrai dans mon cas où j'ai l'assurance que l'API ne fera qu'augmenter les états et n'invalidera jamais un état existant. Dans le cas contraire, il faudra changer les fonctions qui utilisent les états définis dans l'enum, avec ou sans la génération d'enumautomatique.
Inconvénients :
- à nouveau, la liste des états valides n'est jamais écrite dans le code
- Un tantinet plus long, surtout si tout ne va pas sur des roulettes du premier coup.
Et si je mentionne les roulettes, c'est que vous imaginez bien que ça n'a pas marché du premier coup (sinon je n'écrirais pas cet article).
La théorie
Selon la documentation officielle, il suffit de passer 3 paramètres à la fonction type afin de créer une classe dynamiquement.
Si vous voulez mon avis, on est là dans la catégorie des fonctionnalités de Python vraiment puissantes pour le prototypage (à côté de eval et exec, même si ces derniers devraient être quasiment interdits en production).
Chouette, me dis-je en mon fort intérieur, ceci devrait marcher :
# récupération du dictionnaire des valeurs
d_enum_values: dict = fetch_all_states(...)
# création dynamique de l'enum
MonEnumCustom = type("MonEnumCustom", (enum.Enum,), d_enum_values)La pratique
Ne vous fatiguez pas, ça ne marche pas. La solution que j'ai trouvée est un contournement dégoûtant (dû justement au module enum de Python).
Je contourne les problèmes de création d'enum à l'aide d'un mapper qui ressemble à ça :
class EnumMappingHelper(dict): # héritage pour contourner type
def __init__(self, mapping: dict = None):
self._mapping = mapping
def __getitem__(self, item):
if item == "_ignore_": # contournement d'enum
return []
return self._mapping[item]
def __delitem__(self, item):
return item # contournement d'enum
def __getattr__(self, key): # Accès au clefs de l'enum par attribut
return self._mapping[key]
@property
def _member_names(self): # contournement d'enum
return dict(self._mapping)
enum_mapping = EnumMappingHelper(d_enum_values)
MonEnumCustom = type("MonEnumCustom", (enum.Enum,), enum_mapping)Je m'en sors donc en torturant un peu un classe personnalisée que j'appelle EnumMappingHelper afin que celle-ci se comporte d'une façon qui soit acceptable à la fois pour la fonction type et pour le module enum.
Je peux utiliser les variantes de mon enum ainsi :
if state is MonEnumCustom.VALIDATION:
print("En cours de validation")
elif state is MonEnumCustom.COMMIT:
print("Validé")
elif state is MonEnumCustom.SEND:
print("Aucune modification possible")
elif ...:
...
else:
raise UnknownEnumStateValue("Code is not in sync with API")Un petit plus... avec un mixin
Je dispose bien entendu d'une fonction qui permet de mapper un état sous forme de chaîne de caractères à la valeur représentée dans l'enum de référence.
Moralement et en très très gros, elle ressemble à ça :
@functools.lru_cache
def map_str_to_custom_enum(s: str) -> MonEnumCustom:
"""docstring
"""
return dict((v.value, v) for v in MonEnumCustom)[s]L'idée étant donc de faire le mapping inverse de celui fourni par 'enum, i.e. de générer automatiquement et efficacement une variante d'enum à partir de sa représentation sous forme de chaîne de caractères.
Sauf qu'en réalité, la fonction n'est pas du tout implémentée ainsi.
À la place, j'utilise un mixin, ce qui me permet d'avoir la même fonctionnalité sur tous les enum.
La fonction ci-dessus est remplacée par une méthode de classe.
Le cache lru_cache est remplacé par un attribut de classe de type dictionnaire, ce qui évite toutes sortes d'inconvénients.
class EnumMixin:
_enum_values = {}
def __init__(self, *args, **kwargs):
self.__class__._enum_values[args[0]] = self
@classmethod
def convert_str_to_enum_variant(cls, value: str):
cls._enum_values
return cls._enum_values(value, object())Avec le mixin de conversion, le code de génération d'enum devient :
# inchangé
enum_mapping = EnumMappingHelper(d_enum_values)
# MonEnumCustom hérite en premier du mixin EnumMixin
MonEnumCustom = type("MonEnumCustom", (EnumMixin, enum.Enum), enum_mapping)Gestion de version de l'API pour les variantes de l'enum
Enfin en ce qui concerne la gestion de version de l'API, il est possible de rajouter un assert dans le code qui vérifie toutes les variantes de l'enum, afin de lever une exception le plus tôt possible et de ne pas faire tourner du code qui ne serait pas en phase avec la version de l'API utilisée.
# je définis la variable suivante en copiant directement les valeurs
# récupérées par un appel à l'API au moment du développement :
ls_enum_variantes_copie_statiquement_dans_mon_code = [
"VALIDATION",
"SEND",
"COMMIT",
"REVIEW",
... # et une centaine d'états supplémentaires
]
# si la ligne suivante lance une AssertionError, l'API a mis à jour
# les variantes de l'enum
assert fetch_all_states(...) == ls_enum_variantes_copie_statiquement_dans_mon_codeDans mon cas, je suis plus souple, car ayant la garantie que les variantes publiées
de mon enum ne seront pas dépréciées par de nouvelles versions de l'API, je vérifie
simplement cette assertion :
# idem
ls_enum_variantes_copie = [
"VALIDATION",
"SEND",
"COMMIT",
"REVIEW",
... # et une centaine d'états supplémentaires
]
# si la ligne suivante lance une AssertionError, l'API n'a pas honoré son
# contrat de ne pas déprécier les variantes de l'enum.
assert set(fetch_all_states(...)).issuperset(set(ls_enum_variantes_copie))Notez que si je souhaite être strict et n'autoriser aucun changement des variantes de l'API, alors il est préférable de copier coller les variantes directement dans le code et de comparer ces valeurs à l'exécution. Le code en est rendu plus lisible. Mais ce n'est pas le cas de figure dans lequel je me trouve.
Conclusion
Seule la solution utilisant un copier coller permettait de voir la liste des valeurs de l'enum dans le code.
Je combine les avantages de cette solution et de la troisième que j'ai implémentée en copiant les valeurs prises par l'enum dans la docstring de sa classe et en mentionnant la version du service distant associé.
Cela me permet de combiner les avantages de toutes les solutions à l'exception, bien sûr, d'un peu de temps passé.
L'inconvénient inattendu de ce code, c'est celui de devoir créer une classe d'aide dont le seul but soit de forcer un comportement afin d'obtenir le résultat escompté. Si vous avez des suggestions pour améliorer ce bazar, je prends.
Joyeux code !
Motius
]]>Aujourd'hui, un micro tutoriel d'administration système pour gérer des problèmes de déconnexion du réseau.
J'utilise sshfs afin de monter un disque distant. Ça me permet d'avoir de la synchronisation de données sur un seul disque dur de référence, qui reste solidement attaché à un serveur. Il m'est donc inutile de brancher et débrancher le disque, et de le déplacer.
Ce programme s'utilise ainsi :
sshfs user@remote:/chemin/du/répertoire/distant /mnt/chemin/du/répertoire/localNote : il vous faudra avoir les droits d'écriture sur le répertoire local sur lequel vous montez le disque distant.
Et pour le démonter, j'utilise :
fusermount -u /mnt/chemin/du/répertoire/localCette commande peut échouer pour plusieurs raisons, notamment s'il y a toujours un programme qui utilise le disque distant. Ça peut être aussi bête que d'essayer de démonter le répertoire depuis un shell (bash, zsh) dont le répertoire courant est dans l'arborescence sous le disque distant.
Le message d'erreur ressemble à ceci :
fusermount: failed to unmount /mnt/chemin/du/répertoire/local: Device or resource busyIl suffit d'utiliser la commande lsof (list open files) pour savoir quels programmes utilisent encore le disque distant de cette manière :
lsof | grep /mnt/chemin/du/répertoire/localMais ! mais mais, il peut arriver que la connexion réseau se coupe (ou que votre serviteur déplace son ordinateur hors de portée du Wi-Fi, il lui arrive d'être distrait...)
Dans ce cas, on peut essayer de recourir à umount en tant qu'utilisateur root, si on lui passe les bonnes options, que voici :
# Lazy unmount. Detach the filesystem from the file hierarchy now, and clean up all
# references to this filesystem as soon as it is not busy anymore.
umount -l /mnt/chemin/du/répertoire/local
# StackOverflow suggère aussi :
# https://stackoverflow.com/questions/7878707/how-to-unmount-a-busy-device
umount -f /mnt/chemin/du/répertoire/local
# mais la page de manuel indique que cette option est utile pour les disques NFS.Joyeux code !
Motius
]]>Il y a eu beaucoup d'articles sur Wireguard, beaucoup de tests, beaucoup de comparatifs. Il faut dire que ce n'est pas passé inaperçu, à tel point que même le grand Linus en a dit du bien.
Mais vous savez bien que je ne suis pas du genre à vanter les prouesses d'un outil pour la seule raison qu'il est à la mode. Sinon je ferais du Docker, de nombreux frameworks Javascript, du Big Data et d'autres digitaleries marketeuses.
Sans plus tarder, je vais donc vous faire l'affront de vous présenter un outil qui est déjà bien couvert.
Je suis tombé sur Wireguard il y a quelques années en me baladant sur le site de Jason Donenfeld, l'auteur de pass, un gestionnaire de mot de passe que j'utilisais déjà. De quoi, je vous en ai jamais parlé non plus ? Franchement c'est impardonnable.
Présentation
Wireguard est un VPN. Un VPN, pour rappel, c'est le fait de mettre plusieurs machines plus ou moins éloignées géographiquement sur un même réseau abstrait, et bien entendu de manière sécurisée. Les VPN sont très utilisés de nos jour, surtout depuis le début du confinement et l'explosion du télétravail. Je vous ai déjà parlé d'OpenVPN par exemple ici et ici. Pour moi, avant Wireguard, OpenVPN était le VPN le plus pratique à déployer. Cependant il a plusieurs défauts :
- La sécurité des transferts est faible voire trouée, notament à cause de l'usage de la bibliothèque OpenSSL.
- Les performances sont loin d'être optimales.
- Plusieurs implémentations différentes mênent à des comportement différents selon les plateformes.
- Le volume de code est extravagant.
D'autres VPN existent et sont un peu plus performants et plus sûrs, comme IPsec. Mais, concernant IPsec, son utilisation est un peu mystique si j'ose dire, et niveau volume de code, c'est encore pire. Mais alors, d'où vient cette malédiction des VPN ? Pas vraiment d'explication si ce n'est que le code est assez vieux, ce qui d'habitude mène à un outil solide et à l'épreuve des bugs, alors qu'ici cela a apporté des couches de codes cancéreuses et la nécrose qui l'accompagne.
Wireguard est donc un nouveau VPN qui est, malgré son aproche moderne et son chiffrement dernier cri, le premier à miser sur la maintenabilité et le minimalisme de son code. Cette stratégie vise à faciliter les audits de sécurité (afin que tout le monde sache que c'est un protocole sûr) et la réduction de la surface d'attaque de personnes malveillantes (moins de code = moins de failles).
Autre point très important, et c'est pour moi le point clef, c'est la simplicité d'utilisation pour les administrateurs systèmes. En gros, une connexion Wireguard pourra être manipulées avec les outil réseau standards disponibles sur UNIX. La simplicité se retrouve aussi dans la configuration. L'établissement d'une liaison Wireguard est pensée pour être aussi simple qu'une connexion SSH. Il s'agit en effet d'un simple échange de clef publiques. Donenfeld dit s'inspirer de la simplicité des outils OpenBSD.
Le protocole étant été prévu comme intégré directement au noyau, il s'est présenté sous la forme d'un module kernel jusqu'à sa fusion directe dans le noyau Linux le 30 mars dernier. Un patch pour le noyau OpenBSD est en cours de peaufinage et fera d'OpenBSD le deuxième système d'exploitation intégrant Wireguard nativement.
Topologie
Contrairement à OpenVPN qui par défaut a une vision client/serveur, c'est à dire que tous les membres du réseau privé gravitent autour d'un unique point d'accès, Wireguard laisse une grande liberté de manœuvre et considère tous les membres du VPN comme des pairs indépendants : chaque nœud possède une liste de pair à qui il va parler directement. Par example, imaginons un réseau privé de trois machines Alice, Bob et Carol. Le plus efficace serait que chacune des trois machines connaisse toutes les autres, c'est à dire qu'elle ait deux pairs correspondant aux deux autres machines :
- Pairs d'Alice :
- Bob
- Carol
- Pairs de Bob :
- Alice
- Carol
- Pairs de Carol :
- Alice
- Carol

L'ennui, c'est que si on veut ajouter une nouvelle machine Dave en respectant cette topologie, il faut récupérer les infos de toutes les autres machines (Alice, Bob et Carol) pour dresser la liste de pairs de Dave, et ensuite on doit ajouter Dave à la liste de pairs d'Alice, Bob et Carol.
De plus, pour établir une liaison entre deux pairs, il faut un point d'accès connu pour au moins un des pairs (une IP et un port UDP). Si on ne connait pas les points d'accès d'Alice et Bob, ou alors si Alice et Bob n'ont pas besoin de se parler entre eux et s'intéressent uniquement à Carol, alors Alice et Bob n'ont besoin que de Carol dans leurs liste de pairs. Carol doit avoir Alice et Bob dans ses pairs. C'est le scénario connu sous le nom de roadwarrior : Alice et Bob sont des pairs mobiles et Carol est une passerelle vers un autre réseau dont les pairs mobiles ont besoin. Dans le cas d'usage du télétravail, Alice et Bob sont des salariés chez eux et Carol est la passerelle du parc informatique de l'entreprise.
- Pairs d'Alice :
- Carol
- Pairs de Bob :
- Carol
- Pairs de Carol :
- Alice
- Bob
Ainsi, quand on voudra ajouter Dave dans la topologie, il suffira que Dave ait connaissance de Carol dans sa liste de pairs, et il faudra dire à Carol d'ajouter Dave à ses pairs.
Ne vous méprenez pas, dans la topologie roadwarrior, le fait que les pairs mobiles ne soient pas les uns dans les listes de pairs des autres ne signifie pas obligatoirement qu'il ne pourront pas communiquer entre eux. Simplement, ils devront communiquer en passant par la passerelle (qui devra être préparée à cet effet) au lieu de communiquer directement comme dans le cas où tout le monde connait tout le monde.
Paire de clefs
Je vous ai parlé d'échanges de clefs sauce SSH. Pour établir une laison entre deux pairs, il faut que chacun des pairs génère une paire de clef.
wg genkey | tee private.key | wg pubkey > public.keywg genkey va générer une clef privée et wg pubkey va créer la clef publique correspondante.
Ensuite, les deux pairs doivent s'échanger leur clefs publiques par les moyens qu'ils estiment les plus adéquats (vérification en personne, mail, SMS, télégramme, fax...).
Disons qu'Alice et Bob souhaitent devenir pairs l'un de l'autre. Chacun se crée une paire de clef.
- Pour Alice :
- Clef privée :
6JcAuA98HpuSqfvOaZjcwK5uMmqD2ue/Qh+LRZEIiFs= - Clef publique :
gYgGMxOLbdcwAVN8ni7A17lo3I7hNYb0Owgp3nyr0mE=
- Clef privée :
- Pour Bob :
- Clef privée :
yC4+YcRd4SvawcfTmpa0uFiUnl/5GR1ZxxIHvLvgqks= - Clef publique :
htjM/99P5Y0z4cfolqPfKqvsWb5VdLP6xMjflyXceEo=
- Clef privée :
Alice et Bob vont ensuite s'échanger leurs clefs publiques.
Notez comme la tête d'une clef privée ressemble à celle d'une clef privée. C'est tentant de confondre les deux. Mais ne le faîtes pas, ce serait mauvais pour votre karma.
Ensuite Alice et Bob vont constituer leurs fichiers de configuration, à placer dans /etc/wireguard/wg0.conf. Le fichier n'est pas obligé de s'appeler wg0.conf, il doit juste se terminer par .conf.
Pour Alice :
[Interface]
PrivateKey = 6JcAuA98HpuSqfvOaZjcwK5uMmqD2ue/Qh+LRZEIiFs=
Address = 10.0.0.1/16
[Peer]
PublicKey = htjM/99P5Y0z4cfolqPfKqvsWb5VdLP6xMjflyXceEo=
AllowedIPs = 10.0.0.2/32Pour Bob :
[Interface]
PrivateKey = yC4+YcRd4SvawcfTmpa0uFiUnl/5GR1ZxxIHvLvgqks=
Address = 10.0.0.2/16
[Peer]
PublicKey = gYgGMxOLbdcwAVN8ni7A17lo3I7hNYb0Owgp3nyr0mE=
AllowedIPs = 10.0.0.1/32Trois remarques :
- Seule la clef publique permet de différencier les pairs. Il n'y a pas de champs pour un nom ou un éventuel commentaire.
- L'IP ou la plage IP définie dans
AllowedIPscorrespond à toutes les adresses IP cibles des paquets qui seront envoyées à ce pair, et à toutes les adresses IP sources des paquets susceptibles d'être reçus par ce pair. On en reparle plus tard. - En l'état, le VPN ne pourra pas marcher : ni Alice ni Bob ne sais où trouver l'autre pair. Il faut qu'au moins un des deux pairs ait un point d'accès, comme nous l'avons expliqué plus haut. S'il est décidé qu'Alice communique son point d'accès, Alice devra ajouter un champ
ListenPortà ta rubriqueInterface, et Bob ajoutera un champEndpointà la déclaration du pair correspondant à Alice.
Pour Alice, sa configuration devient :
[Interface]
PrivateKey = 6JcAuA98HpuSqfvOaZjcwK5uMmqD2ue/Qh+LRZEIiFs=
Address = 10.0.0.1/16
ListenPort = 51820
[Peer]
PublicKey = htjM/99P5Y0z4cfolqPfKqvsWb5VdLP6xMjflyXceEo=
AllowedIPs = 10.0.0.2/16Pour Bob :
[Interface]
PrivateKey = yC4+YcRd4SvawcfTmpa0uFiUnl/5GR1ZxxIHvLvgqks=
Address = 10.0.0.2/16
[Peer]
PublicKey = gYgGMxOLbdcwAVN8ni7A17lo3I7hNYb0Owgp3nyr0mE=
AllowedIPs = 10.0.0.1/32
Endpoint = alice.example.com:51820Routage des pairs
La signification du champ AllowedIPs est un peu subtile, car elle concerne les deux sens de circulation des paquets. C'est à la fois utilisé pour filtrer les paquets arrivant pour vérifier qu'ils utilisent une IP attendue et pour router les paquets sortants vers ce pair.
On est pas obligé de ne mettre que l'adresse VPN du pair. D'ailleurs, notament dans le scénario roadwarrior, il faut que les machines mobiles configurent le pair correspondant à la passerelle d'accès avec un champ AllowedIPs correspondant au réseau VPN entier, par exemple 10.0.0.0/16.
Reprenons notre scénario roadwarrior avec Alice et Bob en pair mobile et Carol en passerelle d'accès. On définit le réseau VPN 10.0.0.0/16. D'autre part, disons que le réseau interne auquel Carol doit servir de passerelle est en 192.168.0.0/16 et contient une machine Dave.

Carol a donc une paire de clef :
- Clef privée :
8NnK2WzbsDNVXNK+KOxffeQyxecxUALv3vqnMFASDX0= - Clef publique :
u8MYP4ObUBmaro5mSFojD6FJFC3ndaJFBgfx3XnvDCM=
La configuration de Carol ressemble alors à ceci :
[Interface]
PrivateKey = 8NnK2WzbsDNVXNK+KOxffeQyxecxUALv3vqnMFASDX0=
Address = 10.0.0.1/16
ListenPort = 51820
[Peer] # Alice
PublicKey = gYgGMxOLbdcwAVN8ni7A17lo3I7hNYb0Owgp3nyr0mE=
AllowedIPs = 10.0.0.1/32
[Peer] # Bob
PublicKey = htjM/99P5Y0z4cfolqPfKqvsWb5VdLP6xMjflyXceEo=
AllowedIPs = 10.0.0.2/16Celle d'Alice et Bob ne contiennent d'un seul pair correspondant à Carol et ressemblant à ceci :
[Peer]
PublicKey = u8MYP4ObUBmaro5mSFojD6FJFC3ndaJFBgfx3XnvDCM=
AllowedIPs = 10.0.0.0/16, 192.168.0.0/16
Endpoint = vpn.example.com:51820La valeur d'AllowedIPs signifie que des paquets en 10.0.0.0/16 et 192.168.0.0/16 vont arriver en provenance de Carol, et que les paquets vers ces même plages IP seront acheminés vers ce pair. On retrouve alors bien le fait que si Alice désire parler à Bob, elle ne le pourra le faire qu'en passant par Carol. Mais ce genre de besoin est rare en roadwarrior.
Dans un futur article j'aborderai la configuration d'une telle passerelle et les subtilités de routages VPN.
]]>Aujourd'hui un tout petit tutoriel pour parler esthétique et sémantique dans le développement Python.
Comme vous le savez sûrement, Python a introduit dans sa version 3.7 le nouveau module dataclasses qui permet de réduire la verbosité dans la création de classes. Pour rappel, cela permet de transformer quelque chose comme ça :
class Chat:
def __init__(self,
taille: float = None,
âge: int = None, # oui oui, c'est légal, déclarez π = math.pi aussi
couleur: str = None,
vivant: bool = None, # Schrödinger
):
self.taille = taille
self.âge = âge
self.couleur = couleur
self.vivant = vivanten ça :
@dataclasses.dataclass
class Chat:
taille: float
âge: int
couleur: str
vivant: boolavec éventuellement plein de paramètres dans le décorateur dataclass, que je vous encourage à aller lire dans la doc Python. On devine assez facilement ce que font les options :
- init=True
- repr=True
- eq=True
- order=False
- unsafe\_hash=False
- frozen=Falseet les conséquences de leurs valeurs par défaut, mais il y a quelques subtilités qui mérite un peu de lecture.
Ce sur quoi je souhaitais mettre l'accent dans cet article, c'est l'existence de la méthode __post_init__ dans le module. En effet, cette méthode est très pratique, et je trouve qu'elle permet facilement de distinguer deux types d'usages de dataclass.
En général, les classes qui n'utilisent pas cet méthode sont plus souvent des vraies dataclass, au sens classes qui contiennent de la données, comparable à une struct en C ou au Records java à venir.
A contrario, celles qui utilisent cette méthode peuvent parfois être des classes qui retiennent un état, par exemple pour de la configuration, mais celles-ci peuvent faire des choses bien plus avancées dans cette méthode qui est appelée automatiquement après la méthode init qui, je le rappelle, est gérée par le module dataclasses.
Par conséquent, si vous rencontrez une dataclass, cela peut être pour deux raisons :
- utiliser une nouvelle fonctionalité Python déclarative et plus élégante ;
- créer un objet contenant principalement de la donnée.
Connaître cette distinction sémantique et l'avoir en tête permet une analyse statique du code à la lecture plus rapide, je suis tombé sur une occurrence de ce phénomène et la partage donc.
Joyeux code !
Motius
]]>Lorsque je l'ai créé au cours de l'été 2015, je ne connaissait pas grand chose en administration système ni en bonnes pratiques pour entretenir un site web. Je suis donc plongé dans le pière de Wordpress. Cette solution est très bien pour avoir un résultat rapide sans toucher au code une seule fois. C'est une solution que je continuerai de recommander à des gens qui n'y connaissent rien, à la condition qu'ils soient accompagnés par des experts Wordpress. Et je ne le suis pas.
J'avais perdu tout contrôle sur le site, qui étais devenu une sorte de tumeur. J'ai décider d'amputer avant la phase terminale.
Vous le savez, au cours de mes tribulations, j'ai affirmé mon goût pour les solutions KISS. Je me suis donc mis à la recherche d'un CMS simple à entretenir, dont je comprends le fonctionnement (et un peu le code), mais aussi dont je puisse me passer avec un minimum d'effort si je décide de trouver encore mieux. J'ai donc opté pour PicoCMS.
PicoCMS, comme son nom l'indique, est un CMS minimaliste. Il a le bon goût de travailler sans base de données : les articles sont stockés sous la forme de simples fichiers Markdown. Il est donc très facile de versionner le contenu du site avec git. D'autre part le langage Markdown est plus ou moins standard et fonctionne avec des tonnes d'autres CMS et générateurs de sites statiques. S'il me prends l'envie de changer du jour au lendemain pour passer à Pelican ou Hugo par example, ce sera très facile.
Pour effectuer la migration de Wordpress à PicoCMS, cela n'a pas été très aisé. La conversion du format base de donnée au Markdown a été assez pénible. Il existe un script assez dégoutant qui fait la plupart du travail. Mais hélas il n'est pas exhaustif et j'ai du repasser sur beaucoup de points manuellement, à coup de find, sed, grep, notamment pour reprendre la liste des tags et les dates. L'intégration des images était aussi à revoir complètement, et les extraits de code, à cause d'une extention Wordpress bizarre (qui me semblait cool à l'époque) a été bâclée.
Une fois les article à peu près propres, je suis tombé sur un thème très intéressant mettant en avant les tags. Et je suis assez satisfait du résultat.
En attendant le prochain changement majeur, je vais danser sur la tombe de Wordpress.
]]>L'introduction reste générale, objective, et pose les contraintes, la première partie expose la solution choisie, et la deuxième partie aborde la mise en œuvre.
Comme tout ingénieur système sain d'esprit, j'aime bien les infrastructures qui ont de la gueule. Par là, j'entends une infra qui soit à l'épreuve de trois fléaux :
- Le temps : Les pannes étant choses fréquentes dans le métier, les différents éléments de l'infrastructure, tant matériels que stratégiques, doivent pouvoir être facilement et indépendamment ajoutés, remplacés ou améliorés.
- L'incompétence : Les opérateurs étant des êtres humains plus ou moins aguerris, le fonctionnement de l'infrastructure doit être le plus simple possible et sa maintenance doit réduire au maximum les risques d'erreurs de couche 8.
- L'utilisation : Personne ne doit être en mesure d'utiliser l'infrastructure d'une façon ou dans un objectif non désiré par ses concepteurs. C'est valable pour certains utilisateurs finaux qui tenteraient d'exploiter votre œuvre dans un but malveillant, aussi bien que d'éventuels changements d'équipe qui ne comprend rien à rien (cf. les dangers de l'incompétence).

Risques de Corona
J'aurais pu aussi préciser que votre infrastructure doit également être à l'épreuve du coronavirus, mais pas grand risque de ce côté là, quoiqu'il ne faille pas confondre avec la bière Corona, qui, si renversée négligemment sur un serveur, peux infliger des dégâts regrettables.
Concrètement, dans le cadre d'un cluster de virtualisation, ça se traduit par quelques maximes de bon sens :
- On fait en sorte qu'une VM puisse être exécutée sur n'importe quel hyperviseur.
- N'importe quel opérateur doit être en mesure d'effectuer des opérations de base (et de comprendre ce qu'il fait) sans corrompre le schmilblick, à toute heure du jour ou de la nuit, à n'importe quel niveau de sobriété, et s'il est dans l'incapacité physique, il doit pouvoir les expliquer à quelqu'un qui a un clavier et qui tient debout.
- La symphonie technologique (terme pompeux de mon cru pour désigner les différentes technos qui collaborent, s'imbriquent et virevoltent avec grâce au grand bal des services) doit s'articuler autour de technos et protocoles indépendants, remplaçables, robustes et s'appuyant les uns sur les autres.
Que de belles résolutions en ce début d'année, c'est touchant. Alors pour retomber sur terre, on va parler du problème épineux de l'unicité des instances de VM.
Et bien oui, le problème se pose, car dans un cluster, on partage un certain nombre de ressources, ça tombe sous le sens. Dans notre cas, il s'agit du système de stockage. Comme on l'a déjà évoqué, chaque nœud du cluster doit pouvoir exécuter n'importe quelle VM. Mais le danger est grand, car si on ne met pas en place un certain nombre de mécanismes de régulation, on risque d'exécuter une VM à plusieurs endroit à la fois, et c'est extrêmement fâcheux. On risque de corrompre d'une part les systèmes de fichiers de la VM concernée, ce qui est déjà pénible, mais en plus, si on effectue des modifications de la structure de stockage partagé à tort et à travers, on risque d'anéantir l’ensemble du stockage du cluster, ce qui impactera l'ensemble du service. C'est bien plus que pénible.
La solution de stockage
La virtualisation
L'outil de gestion de machines invitées que je préfère est libvirt, développé par les excellents ingénieurs de Redhat. À mon sens c'est le seul gestionnaire de virtualisation qui a su proposer des fonctionnalités très pratiques sans se mettre en travers de la volonté de l'utilisateur. Les commandes sont toujours implicites, on sait toujours ce qui est fait, la documentation est bien remplie, les développeurs sont ouverts, et surtout, libvirt est agnostique sur la gestion des ressources, c'est à dire qu'il manipule des concepts simples qui permettent à l'opérateur de le coupler à ses propres solutions avec une grande liberté.
Voici une liste d'autres solutions, qui ne me correspondent pas :
- Proxmox : Il s'agit d'une de ces solutions qui misent sur le tout-en-un, et donc contraire à l'approche KISS. Cela dit, son approche multi-utilisateurs est très intuitive surtout quand on a pas de compétences poussées en virtualisation, du fait de la présence d'une interface web intuitive. Il s'agit d'une solution satisfaisante lorsqu'on souhaite utiliser un unique nœud mais dès lors qu'on construit un cluster, Proxmox fait intervenir des élément très compliqués qui peuvent vite se retourner contre vous lors de fausses manipulations qui peuvent vous sembler bénignes. De ce fait, sa difficulté d'utilisation et de maintenance augmente de façon spectaculaire, et c'est ce contraste que je lui reproche.
- oVirt : Il s'agit d'une solution également développée par Redhat, avec interface web conne proxmox et beaucoup (peut-être trop) de fonctionnalités, et qui utilise libvirt pour faire ses opérations. Cependant, comme j'ai du mal à voir ce qui est fait sous le capot, j'ai décidé de ne pas l'utiliser.
- Virtualbox : Du fait de l'omniprésence et de la disponibilité des tutoriels sur Virtualbox, cela aurait semblé être une bonne solution. Mais il y a plusieurs problèmes : en premier lieu cette solution a été conçue principalement autour de son interface graphique, et son interface en ligne de commande est assez pauvre. Ensuite, par Virtualbox on parle d'une part de l'outil de gestion de VM, mais également du moteur d'exécution lui même. Ce moteur nécessite l'installation d'un module tiers dans le noyau du système, et je préfère éviter cette pratique.
- VMware : Non là je trolle. #Sapucépalibre
Sous linux, la solution la plus logique pour faire de la virtualisation est QEMU + KVM. Comme je l'ai évoqué, il existe aussi le moteur Virtualbox que j'ai exclu pour les raisons que vous connaissez. On aurait pu aussi s'éloigner de la virtualisation au sens propre et se tourner vers des solutions plus légères, par exemple la mise en conteneurs de type LXC ou Docker.
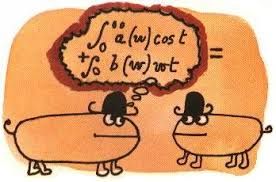
Les conteneurs sont de petits animaux très gentils avec un petit chapeau sur la tête pour pouvoir se dire bonjour. Et ils sont très, très intelligents.
Les conteneurs sont très utiles lorsqu'il s'agit de lancer des programmes rapidement et d'avoir des ressources élastiques en fonction de l'utilisation. L'avantage des conteneurs est qu'ils sont très réactifs en début et en fin de vie, pour la simple raison qu'ils ne possèdent pas de noyau à lancer et donc ses processus sont directement lancés par l'hôte. En revanche, je compte lancer des machines virtuelles complètes, dotées de fonctions propres, parfaitement isolées de l'hôte, et qui vont durer pendant de longues périodes. Pour des services qui doivent durer, les conteneurs n'apportent rien d'autre que des failles de sécurité. Mais bon, c'est à la mode, vous comprenez...
Bon c'est entendu, partons sur libvirt ne demande pas grand chose pour lier une machine virtuelle à son stockage, ce qui fait qu'il est compatible avec beaucoup de façons de faire. En particulier, si votre stockage se présente sous la forme d'un périphérique en mode block dans votre /dev, libvirt saura en faire bon usage.
Le partitionnement
Au plus haut niveau pour le stockage des VM, je me suis tourné naturellement vers LVM. C'est la solution par excellence quand on cherche à gérer beaucoup de volumes modulables et élastiques, avec de très bonnes performances. Besoin d'un nouveau volume ? Hop, c'est fait en une commande. Le volume est trop petit ? Pas de problème, LVM peut modifier la taille de ses partitions sans avoir à s'inquiéter de la présence d'autres partitions avant ou après, LVM se débrouille comme un chef.
LVM s'articule autour de trois notions :
- Les LV (logical volumes) : Les partitions haut niveau qui seront utilisées par les VM.
- Les VG (volumes groups) : un VG est une capacité de stockage sur laquelle on va créer des LV.
- Les PV (physical volumes) : Les volumes qui sont utilisés pour créer des VG. Un VG peut utiliser plusieurs PV, en addition ou en réplication, de façon similaire au RAID.
Par défaut, un VG est local, c'est à dire conçu pour n'être utilisé que sur une seule machine. Ce n'est pas ce qu'on souhaite. On souhaite un VG commun à tous les nœuds, sur lequel se trouvent des LV qui, on le rappelle, ne sont utilisés que par un seul nœud à la fois. LVM nous permet de créer un tel VG partagé, en ajoutant un système de gestion de verrous.
Là encore, il y a beaucoup de façons de faire. Moi, je cherchais un moyen qui ne m'impose pas de mettre en place des technos qui sont très mises en valeur dans la littérature mais sur lesquelles je me suis cassé les dents, à l'installation comme au dépannage. Typiquement, je refusais catégoriquement de donner dans du Corosync/Pacemaker. J'ai déjà joué, j'ai perdu, merci, au revoir. Un jour peut-être vous vanterai-je dans un article les bienfaits de Corosync lorsque j'aurai compris le sens de la vie et obtenu mon prix Nobel de la paix. Ou bien depuis l'au-delà lors du jugement dernier lorsque les bons admins monterons au ciel et les mauvais descendront dans des caves obscures pour faire du Powershell ou se faire dévorer par les singes mutants qui alimentent en entropie les algorithmes de Google. En attendant, j'y touche pas même avec un bâton.
Une technique qui m'a attiré par sa simplicité et son bon sens fait intervenir la notion de sanlock : plutôt que de mettre en place une énième liaison réseau entre les différents nœuds et de paniquer au moindre cahot, on part du principe que de toute façon, quelle que soit la techno de stockage partagé utilisé, les nœuds ont tous en commun de pouvoir lire et écrire au mème endroit. Donc on va demander à LVM de réserver une infime portion du média pour y écrire quelles ressources sont utilisées, et avec quelles restrictions. Ainsi, les nœuds ne se marchent pas sur les câbles. Moi ça m'allait bien.

Une photo de groupe de l'équipe admin de mon ancien travail. On venait de changer de locaux.
D'ailleurs, à ce niveau de l'histoire, je dois dire que je ne suis pas peu fier. En effet, pour mettre au point cette infrastructure, j'ai été inspiré en grande partie par l'infrastructure utilisée dans une de mes anciennes entreprises, dans laquelle j'avais la fonction de singe savant, et je ne comprenais pas (et ne cherchais pas à comprendre) le fonctionnement de mon outil de travail. Après mon départ, quand j'ai cherché à comprendre, j'ai entretenu une correspondance courriel avec un de mes anciens référents techniques, qui a conçu cette infra et pour qui j'ai toujours eu beaucoup de respect.
Je lui avais demandé des infos sur le sanlocking, ce à quoi il m'a répondu :
Quand j'ai testé le sanlocking ça avait fonctionné, mais je suis pas allé plus loin. Mais ici on gère vraiment le locking à la main.
En effet, les VG de stockages étaient de simples VG locaux. Les métadonnées étaient individuellement verrouillées localement sur chaque nœud, et dès lors qu'on voulait provisionner une nouvelle VM, on devait lancer un script qui déverouillait les métadonnées sur le nœud de travail. Du coup, rien n'empêchait un autre nœud de faire la même chose, au risque d'avoir des modifications concurrentes et la corruption de l'univers. Donc, on était obligé de hurler à la cantonade dans l'open space dès qu'on touchait à quoi que ce soit. Si on avait de l'esprit, on aurait pu parler de screamlock à défaut de sanlock. De la même façon, on risquait à tout moment de lancer des VM à deux endroits à la fois !
En fait on passe petit à petit sur oVirt pour gérer ce cas là. Aujourd'hui sur notre cluster KVM "maison", rien ne nous empêche de démarrer x fois la même machine sur plusieurs hôtes et de corrompre son système de fichiers 😕️ C'est une des raisons de la bascule progressive vers oVirt.
Donc je suis fier de ne pas avoir eu à passer à oVirt pour faire ça. Libvirt est suffisamment simple et ouvert pour nous laisser faire ce qu'on veut et c'est ce que j'aime.
Le partage
Quel PV doit-on choisir pour notre cluster ? Il nous faut un machin partagé, d'une manière ou d'une autre. J'ai envisagé au moins trois solutions :
- Un LUN iSCSI depuis un SAN (aka. la solution optimale) : Un SAN est un serveur de stockage mettant à disposition des volumes (appelés LUN). Le stockage est donc géré par des appareils dédiés, qui se fichent complètement de la façon dont on utilise ses volumes ni sur combien de nœuds. Le SAN ne sait pas si ses volumes contiennent des systèmes de fichiers, et il ne bronchera pas du tout si vous corrompez leur contenu parce que vous êtes pas fichu de vous organiser. Le soucis avec les SAN, c'est leur coût qui fait souvent dans les cinq chiffres...
- Une réplication DRBD multimaster (aka. la solution du pauvre) : Si vous êtes comme moi et que les brousoufs ne surpopulent pas votre compte en banque, vous pouvez vous limiter à utiliser le stockage local de vos nœuds, que vous mettez en réplication multimater DRBD. De cette façon, chaque modification du volume sera instantanément répercuté sur l'autre nœud. L'avantage de cette solution est que le stockage est local, donc pour les accès en lecture on ne génère pas de trafic réseau. D'autre part, on a de facto une réplication de l'ensemble des données en cas de panne d'un nœud. Le soucis avec DRBD, c'est qu'il ne supporte, pour l'instant, que deux nœuds. D'un autre côté, comme on est pauvre, on a difficilement plus de deux nœuds de toute façon, mais cela empêche une mise à l'échelle horizontale dans l'immédiat. On peut se consoler en planifiant qu'on pourra passer sans trop d'efforts à la solution SAN quand les finances seront propices.
- D'autres protocoles plus lourds comme Ceph qui vous promettent la lune et des super fonctions haut niveau (aka. la mauvaise solution) : Attention danger, on rentre dans l'effroyable empire des machines à gaz : on sait pas trop ce que ça fait, ça bouffe des ressources sans qu'on sache pourquoi, et quand ça foire, si on a pas passé sa vie à en bouffer, on peut rien faire. Déjà, Ceph est une solution mise en avant par Proxmox, donc il y a déjà matière à se méfier. En plus, les fameuses fonctions haut niveau, comme le partitionnement, le modèle qu'on a choisit nous pousse à le gérer avec autre chose, ici LVM. Donc merci, mais non merci.
Notez que peu importe la solution que vous choisirez, comme il s'agit de stockage en réseau, il est fortement recommandé d'établir un réseau dédié au stockage, de préférence en 10 Gbps. Et malheureusement, les cartes réseau et les switchs 10 Gbps, c'est pas encore donné.
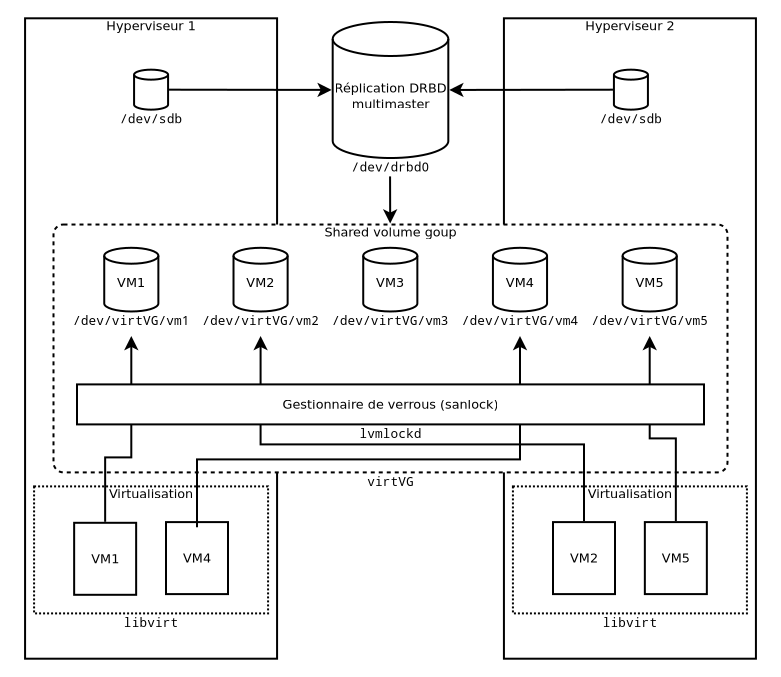
Schéma récapitulatif
La mise en œuvre
Lors de la phase de conception, on est parti du besoin haut niveau pour descendre au contraintes matérielles. Pour la mise en œuvre, on va cheminer dans l'autre sens.
DRBD
Comme je vous l'ai avoué, d'un point de vue budget infrastructure, j'appartiens à la catégorie des pauvres. J'ai donc du me rabattre sur la solution DRBD.
Sur chacun de mes deux nœuds, je dispose de volumes de capacité identique, répondant au nom de /dev/sdb.
Après avoir installé DRBD, il faut créer sur chacun des nœuds la ressource associés à la réplication, qu'on va nommer r0.
# /etc/drbd.d/r0.res
resource r0 {
meta-disk internal;
device /dev/drbd0;
disk /dev/sdb;
syncer { rate 1000M; }
net {
allow-two-primaries;
after-sb-0pri discard-zero-changes;
after-sb-1pri discard-secondary;
after-sb-2pri disconnect;
}
startup { become-primary-on both; }
on node1.mondomaine.net { address 10.0.128.1:7789; }
on node2.mondomaine.net { address 10.0.128.2:7789; }
}Quelques explications :
/dev/sdbest le périphérique de stockage qui va supporter DRBD./dev/drbd0sera le volume construit par DRBD- Les noms des nœuds doivent correspondre au nom complet de l'hôte (défini dans
/etc/hostname) et ne pointe pas obligatoirement vers l'adresse IP précisée, qui est souvent dans un réseau privé dédié au stockage.
Une fois que c'est fait, on peut passer à la création de la ressource sur les deux machines :
drbdadm create-md r0
systemctl enable --now drbdDRBD va ensuite initier une synchronisation initiale qui va prendre pas mal de temps. L'avancement est consultable en affichant le fichier /proc/drbd. À l'issue de cette synchronisation, vous constaterez que l'un des nœuds est secondaires. On arrange ça par la commande drbdadm primary r0 sur les deux hôtes (normalement uniquement sur l'hôte secondaire mais ça mange pas de pain de le faire sur les deux).
LVM
On a besoin d'installer le paquet de base de LVM ainsi que les outils pour gérer les verrous.
apt install lvm2 lvm2-lockd sanlockLa page du manuel de lvmlockd est extrêmement bien ficelée mais je sens que je vais quand même devoir détailler sinon ce serait céder à la paresse. On va donc reprendre les étapes de la même façon que la documentation.
On prends conscience que c'est bien le type sanlock qu'on veut utiliser. L'autre (dlm) est presque aussi nocive que Corosync.
Dans le fichier /etc/lvm.conf on modifie :
use_lvmlockd = 1
locking_type = 1Sur la version de LVM de la Debian actuelle (Buster), le paramètre locking_type est obsolète et n'a pas besoin d'être précisé.
Ne pas oublier de donner un numéro différent à chaque hôte dans le fichier /etc/lvm/lvmlocal.conf dans la rubrique local dans le paramètre host_id.
On active sur chaque hôte les services qui vont bien :
systemctl enable --now wdmd sanlock lvmlockdOn crée le VG partagé virtVG (sur un seul nœud) :
vgcreate --shared virtVG /dev/drbd0Puis enfin on active le VG sur tous les hôtes :
vgchange --lock-startVous pouvez dès à présent créer des LV. Pour vérifier que votre VG est bien de type partagé, vous pouvez taper la commande vgs -o+locktype,lockargs. Normalement vous aurez un résultat de ce genre :
VG #PV #LV #SN Attr VSize VFree LockType VLockArgs
virtVG 1 2 0 wz--ns 521,91g 505,66g sanlock 1.0.0:lvmlockDans la colonne Attr, le s final signifie shared, et vous pouvez voir dans la colonne LockType qu'il s'agit bien d'un sanlock.
Pour créer un LV de 8 Go qui s'appelle tintin :
node1:~# lvcreate -L 8g virtVG -n tintin
Logical volume "tintin" created.
node1:~# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
prout virtVG -wi------- 8,00g
test virtVG -wi------- 8,00g
tintin virtVG -wi-a----- 8,00gLe a de la commande Attr indique que le volume est activé. C'est sur cette notion d'activation qu'on va pouvoir exploiter le verrou. Pour en faire la démonstration, rendez-vous sur un autre hôte (on n'a qu'un seul autre hôte comme on est pauvre).
node2:~# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
prout virtVG -wi------- 8,00g
test virtVG -wi------- 8,00g
tintin virtVG -wi------- 8,00gNotez que tintin n'est pas activé ici, et on a d'ailleurs tout fait pour que l'activation n'ait lieu que sur un seul nœud à la fois. Voyons ce qui se passe si on essaye de l'activer :
node2:~# lvchange -ay virtVG/tintin
LV locked by other host: virtVG/tintin
Failed to lock logical volume virtVG/tintin.Cessez les applaudissements, ça m'embarrasse. Donc, pour l'utiliser sur le deuxième nœud il faut et il suffit de le désactiver sur le premier.
node1:~# lvchange -an virtVG/tintin
node1:~# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
prout virtVG -wi------- 8,00g
test virtVG -wi------- 8,00g
tintin virtVG -wi------- 8,00gEt sur le deuxième on retente :
node2:~# lvchange -ay virtVG/tintin
node2:~# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
prout virtVG -wi------- 8,00g
test virtVG -wi------- 8,00g
tintin virtVG -wi-a----- 8,00gMagie. Quand un volume est activé, libre à vous d'en faire un système de fichier, de le monter, de faire un dd dessus... Tous ce dont vous aurez besoin c'est du chemin du périphérique /dev/virtVG/tintin. Le plus probable dans le cadre de la virtualisation est qu'il va y être déployé une table de partition MBR ou GPT, auquel cas il faudra, si un jour vous souhaitez explorer ce LV autrement que depuis la VM, lire sa table de partition avec kpartx.
Virtualisation
On arrive presque à l'issue de la chaîne des technos. En fait, dès maintenant, libvirt est capable de créer des VM. Mais par contre, en l'état, vous devrez vous charger manuellement de l'activation des LV. C'est un peu fastidieux, surtout dans un milieu industriel.
D'un point de vue conceptuel, deux possibilités s'offrent à nous :
- On définit toutes les VM sur tous les hôtes (et bien sûr on ne démarre des VM que sur un seul hôte à la fois).
- On définit sur un hôte uniquement les VM que cet hôte a le droit d'exécuter pour l'instant
J'ai choisi la deuxième option pour des raisons de clarté, mais je n'exclue pas de passer à la première option dans le futur pour une raison ou une autre.
Il faut ensuite adopter une stratégie d'activation des LV. On peut en choisir entre ces deux là :
- Un hôte active les LV de toutes les VM qui sont définies sur lui.
- Un hôte active uniquement les LV des VM en cours d'exécution sur lui.
J'ai choisi la deuxième stratégie, car la première est incompatible avec l'option de définir toutes les VM sur tous les hôtes.
Selon cette deuxième stratégie, il y a trois opérations de base sur les VM qui nécessitent d'intervenir sur l'activation des LV :
- La mise en service
- L'arrêt
- La migration (le transfert d'une VM d'un hôte à un autre)
Pour la mise en service, il faut activer le volume (et donc poser un verrou) avant que la machine ait commencé à s'en servir. Pour l'arrêt, il faut désactiver le volume (et donc libérer le verrou) après que la machine ait fini de s'en servir. Pour la migration... c'est plus compliqué.
Pour la migration à froid, c'est à dire pendant que la machine est à l'arrêt, c'est facile : il faut activer le volume sur la machine cible avant la migration et le désactiver après. Pour la migration à chaud, c'est à dire pendant que la VM est en marche, je vous propose d'étudier la suite des états de la VM et du LV, avec en gras les événements et en italique les périodes :
- Avant l'instruction de migration : la VM est en marche sur l'hôte source, donc le LV associé doit être activé sur l'hôte source.
- Instruction de migration
- Entre l'instruction de migration et la migration effective : la VM est en marche sur l'hôte source, donc le LV associé doit être activé sur l'hôte source ; l'hôte cible vérifie qu'il peut accéder au LV, donc le LV doit être activé sur l'hôte cible.
- Migration effective
- Après la migration effective : la VM est en marche sur l'hôte cible, donc le LV associé doit être activé sur l'hôte cible.
Vous le voyez bien : à l'étape 3, il est nécessaire que le LV de la VM soit activé à la fois sur la source et sur la cible. Et là, ce pour quoi on s'est battu depuis le début de cet article vole en éclat, et notre beau château de carte est désintégré par une bourrasque de vent.
Mais non, il reste de l'espoir, car je ne vous ai pas encore tout dit.
En fait, par défaut, les verrous des LV sont exclusifs, mais il est aussi possible de poser un verrou partagé :
lvchange -asy virtVG/tintinLorsqu'un LV est activé avec un verrou partagé, n'importe quel autre hôte a la possibilité d'activer le même LV avec un verrou partagé. Il faudra attendre que tous les hôtes aient désactivé le LV (et donc libéré leurs verrous partagés) pour que le LV puisse à nouveau être activé avec un verrou exclusif.
Bien entendu, si on laisse un verrou partagé sur plusieurs hôtes pendant une longue période, il est probable qu'un opérateur négligeant finisse par commettre l'irréparable en lançant la VM en question alors qu'elle est déjà en marche ailleurs...
C'est pourquoi il faut absolument que les périodes d'usage des verrous partagés soient réduites au nécessaire, c'est à dire pendant la migration.
Heureusement, libvirt vous donne la possibilité de mettre en place des crochets, c'est à dire des scripts qui vont être automatiquement appelés par libvirt au moment où il lance ces opérations. L'emplacement du crochet dont on a besoin est /etc/libvirt/hooks/qemu.
Nouveau problème : en l'état actuel, en ce qui concerne la migration, libvirt invoque le crochet uniquement sur l'hôte cible, et uniquement avant la migration effective. Nous avons besoin qu'il invoque le crochet à trois autres reprises :
- Avant la migration effective, sur l'hôte source, pour permettre de muter le verrou exclusif en verrou partagé
- Après la migration effective, sur l'hôte source et l'hôte, pour permettre de libérer les deux verroux partagés, dans le cas d'une migration à froid
Dans le cas d'une migration à chaud, libvirt notifie de toute façon, à la source, l'arrêt de la VM et donc la libération du verrou quel qu'il soit, et sur la cible, le démarrage de la VM et donc la pose d'un verrou exclusif qui écraserait un éventuel verrou partagé.
J'ai remonté le problème aux ingénieurs de Redhat en charge de libvirt, ils sont en train de développer la solution (suivez le fil sur la mailing list). Je publierai mon script dès que ce problème sera réglé.
À propos de la configuration de libvirt, j'ai un dernier conseil qui me vient à l'esprit. Il ne sert pas à grand chose de configurer le VG en temps que pool de volume, au sens de libvirt. En vérité, on peut très bien démarrer une VM même si son volume est en dehors de tout pool défini dans libvirt. En plus, si le pool est en démarrage automatique, libvirt va activer tous les LV quand il va démarrer, ce qui va provoquer une erreur dans le cas d'un redémarrage d'un hôte dans un cluster en service.
Le seul avantage de définir un pool auquel je peux penser est que libvirt peut créer des LV sans commande LVM auxiliaire au moment de la création d'une VM. La belle affaire. Personnellement je provisionne déjà mes VM avec un outil auxiliaire qui s'appelle virt-builder, faisant partie de la très utile suite utilitaire libguestfs. Je vous la recommande, elle fera peut être l'objet d'un futur article.
J'ai déjà beaucoup trop parlé et ça m'a saoulé, alors maintenant je vais la fermer et dormir un peu.
]]>Bref.
Plus rationnellement et plus décemment, la virtualisation (ou l'isolation de contexte, alias les conteneurs, mais j'ai plus de mal avec ça) est le moyen le plus efficace pour avoir des services propres, maintenables et sûrs. C'est une méthode de travail excellente et très intéressante.
La virtualisation nécessite que la machine hôte mette à disposition des machines invitées un certain nombre de ressources : processeurs, mémoire, interfaces... Notamment, nos machines virtuelles ont la plupart du temps besoin de réseau.
Il existe au moins deux façons de faire du réseau avec des machines virtuelles, une bonne et une mauvaise une facile et une pratique :
- La méthode facile, c'est de mettre toutes les VMs d'un hyperviseur dans un réseau NATé, dont l'hyperviseur est la passerelle.
- La méthode pratique, c'est de passer un pont (bridge) liant l'interface physique de l'hôte avec les interface virtuelles des invités.
Maintenant un brin d'explication.
- La méthode NAT est facile car elle est déployée par défaut par la plupart des hyperviseurs. Elle ne demande aucune modification du réseau de l'hyperviseur. Toutes les requêtes des invités semblent donc émaner de l'hôte, de la même manière que dans votre réseau local dans votre maison, toutes vos machines passent leurs requêtes à votre box-routeur. Cela pose un problème de taille lorsque les invités ont besoin d'être accessible de l'extérieur, ce qui nécessite de gérer des règles d'ouvertures de ports (et donc deux machines ne peuvent pas écouter sur le même port, vu de l'extérieur). D'autre part, il arrive souvent que l'hôte soit lui même derrière un NAT (par exemple si vous ne disposez que d'une seule IP publique pour votre foyer comme c'est le cas dans 99% des connexions internet des particuliers). Placer donc un deuxième NAT géré par votre hôte apporte donc un niveau de complexité à votre infrastructure réseau.
- La méthode Bridge est pratique car, d'un point de vue réseau, vos invitées sont sur le même niveau que votre hôte. Outre le fait que vous avez autre chose à faire de votre vie que de gérer un double NAT et les redirections qui s'ensuivent, ça rend les invités en quelque sortes indépendants de leurs hôtes. Par exemple, imaginons que vous avez deux hôtes H1 et H2 qui font tourner un invité chacun, G1 sur H1 et G2 sur H2. Un client tiers n'a pas besoin de savoir sur quel hôte se situe G1 et G2 pour les contacter car ils ont tous les deux des IPs indépendantes. D'autre part, si vous devez passer H1 en maintenance, il vous suffit de migrer G1 sur H2 sans autre forme de procès, ce sera complètement transparent pour votre infrastructure (pour peu que votre routage de flux soit flexible).eth0
Disons donc que pour faire tourner une distribution desktop ponctuellement pour tester un programme, vous n'avez probablement pas besoin de cet article et vous pouvez très bien vivre avec la solution NAT. Mais pour un parc de machine en production, il est presque toujours indispensable de passer par la solution Bridge.
Mais au fait dis moi Jamy, c'est quoi un bridge ? Et bien Fred, un bridge ça veut dire pont en anglais, et comme son nom l'indique, ça va permettre de lier des interfaces réseau. Ici, le but est de lier les interfaces virtuelles des invités à l'interface physique de la machine. Cela implique que l'interface physique sera partagée par plusieurs machines.
Mettons nous dans la tête d'un hôte dont on a pas encore configuré le bridge. Disons que son interface réseau physique s'appelle eth0. Donc, par défaut et de manière naturelle, cette interface va porter son IP et il ne va pas se poser plus de question que ça. Nous, on veut changer ça. On va créer un bridge, appelons le br0, qui va être le maître de eth0, que sera donc son esclave (ne me regardez pas comme ça, ce sont là les termes officiels, je vous assure). On configurera notre plateforme de virtualisation préférée (libvirt en ce qui me concerne, proxmox pour d'autres, vmware pour les pêcheurs) pour lui dire d'utiliser br0 comme périphérique réseau. Alors, lorsqu'on lancera un invité, son interface virtuelle sera esclave de br0. Quant à l'hôte, l'interface qui utilisera à présent pour se connecter au réseau sera br0.
Si votre hôte est sous CentOS, on peut configurer un nouveau bridge, ici en adressage statique sur mon réseau privé derrière mon routeur, en créant le fichier /etc/sysconfig/network-scripts/ifcfg-br0 contenant ceci :
DEVICE=br0
TYPE=Bridge
BOOTPROTO=static
DNS1=8.8.8.8
DNS2=8.8.4.4
GATEWAY=192.168.1.1
IPADDR=192.168.1.10
NETMASK=255.255.255.0
ONBOOT=yesPour un hôte sous Debian, on aura ce bloc dans /etc/network/interfaces :
iface br0 inet static
bridge_ports eth0
address 192.168.1.10
broadcast 192.168.1.255
netmask 255.255.255.0
gateway 192.168.1.1Il ne faut alors pas oublier de changer la configuration de eth0 pour qu'aucune IP ne lui soit associé. Cette interface n'aura d'autre rôle que de transmettre et recevoir les paquets bruts à notre bridge, qui se chargera de dispatcher les paquets à ses esclaves où à l'hôte.
C'est tout pour aujourd'hui. Allez chauffe Marcel, envoie le générique de fin.
]]>Jistti Meet, pour ceux qui ne le connaissent pas, c'est une solution libre pour faire des discussion vidéo qui s'appuie entre autres sur les technologies XMPP et WebRTC. En gros ça a l'avantage de s'appuyer sur une techno de communication existante et ça ne demande pas d'installation de programmes autres qu'un navigateur un minimum récent. C'est compatible Firefox, Chrome, Edge, pour ne citer qu'eux.
Pour faciliter l'installation, Jitsi met à disposition des dépôts APT permettant d'installer sans galérer cet outil clef en main. En théorie seulement car en pratique il faut quelques étapes préliminaires afin que tous les rouages s'emboîtent correctement.
J'ai donc déployé une nouvelle VM sous Debian Stretch toute nue et j'ai installé les packets.
echo 'deb https://download.jitsi.org stable/' >> /etc/apt/sources.list.d/jitsi-stable.list
wget -qO - https://download.jitsi.org/jitsi-key.gpg.key | apt-key add -
apt update
apt install jitsi-meetL'installeur pose ensuite quelques questions :
- La première porte sur le nom du service (comprendre ici le FQDN).
- La seconde vous demande si vous souhaitez utiliser votre propre certificat ou bien générer un certificat auto-signé. Moi je suis parti sur mon propre certificat, ce qui active les deux questions suivantes.
- Le chemin du fichier de clef.
- Le chemin du fichier de certificat.
Je me dis : cool, cela a l'air de s'être bien passé. Mais je me trompais.
J'ai refais l'installation plusieurs fois en variant plusieurs paramètres : certificat, chemin des fichiers, installation du reverse proxy avant... Dans certains cas j'avais droit à un handshake TLS foireux, dans d'autres cas des comportements bizarre comme l'impossibilité de rejoindre une room, et dans le reste des cas des erreur APT/DPKG.
Il se trouve que l'unique suite d'opération qui ait fonctionné pour moi est la suivante :
- Installer nginx (ou apache si vous aimez utiliser un tank pour casser un œuf). De cette façon, le paquet Jitsi va détecter la présence d'un proxy et va tout seul ajouter son vhost.
- Obtenir vos certificats (letsencrypt si vous le souhaitez) et faire en sorte que nginx écoute sur les ports 80 et 443) avant l'installation de Jistsi. Si ce n'est pas le cas, le processus java de Jitsi va s'approprier les ports 80 et 443 ce qui va créer une erreur au moment de recharger nginx avec la nouvelle configuration. C'est délicat comme position...
- Finalement, installer Jitsy.
J'ai écrit cet article pour économiser un peu de temps au prochains admin qui devront installer ça. Par ailleurs, il est possible que lorsque vous lancerez votre première room, un bug vous frappe: à chaque fois que quelqu'un d'autre rentre dans la room, l'occupant actuel est éjecté... Selon la page du bug sur Github, un reboot de la machine suffit et le bug ne se reproduit apparemment plus. Pour moi ce n'est pas satisfaisant d'appliquer des méthodes à la Windows, mais j'avoue que je n'ai pas eu le courage de chercher plus longtemps.
]]>Je suis revenu sur ce vieux WordPress tout pété que j'ai laissé pourrir pendant presque 2 ans, et je me suis dit que j'en avais assez de ce marécage nauséabond dans lequel je m'étais embourbé. J'ai donc sorti les doigts de mon anus et j'ai remis ça sur pieds.
Je plaide coupable, mais qui irait me jeter la pierre ? Parfois on a besoin de faire d'autres trucs ou de mettre en pause certains d'entre eux, surtout quand le succès n'est pas au rendez-vous. Je ne suis d'ailleurs pas seul, mon compagnon de plume Motius n'ayant plus non plus autant de temps à consacrer à ses tribunes que naguère.
D'ailleurs, que suis-je devenu entre temps ? Il m'est arrivé beaucoup de choses, sans mentir. Rassurez-vous, principalement de bonnes choses, de merveilleuses choses même. Rendez-vous compte, j'ai changé de travail, j'ai déménagé et je me suis marié. Oui, marié. C'est plutôt positif ça comme bilan, non ? Vous comprendrez donc que j'ai pas mal d'autres choses à faire en plus que de m'occuper d'administrer des services web ou d'autres machins. Déjà que le simple fait de faire plus de 8 heures de travail sur systèmes informatiques correspond à une dose de technique presque trop importante pour moi pour ressentir le besoin d'allumer un PC à la maison, mais maintenant que je mène une vie heureuse et épanouie, ça coupe un peu l'envie de bouffer du code et de la ligne de shell.
Cependant ne craignez pas, j'ai décidé de ne pas arrêter. Je vais me refaire une station de travail à la maison pour m'occuper du blog, de mon infra, et du reste. Pourquoi ? Et bien, c'est important de finir ce qu'on commence, en tout cas de le finir autrement que laisser un cadavre de site qui pue. Et d'autre part, et surtout, je ne dois pas oublier ce qui m'a poussé à créer ce blog, à savoir que ça me plaît d'écrire. Je n'écris plus du tout assez ces derniers temps.
J'ai envie de continuer à expliquer des choses au fur et à mesure que je les apprends. J'ai envie de piquer des crises contres telle ou telle techno, tel ou tel événement. J'ai envie de vous expliquer ma vision de l'informatique, du libre et du futur. J'ai envie de collaborer avec Motius, mais également avec toute âme qui serait prête à accorder un peu de son temps pour ce site. J'ai envie de discuter avec vous sur IRC, comme au bon vieux temps, de m'énerver contre Motius parce qu'il parle trop, mais qui a tant de bonnes idées et d’initiatives, ce qui en fait un collaborateur de qualité.
Tout cela m'a manqué. Vous m'avez manqué. J'espère que ça pourra reprendre. Je vais donc lutter férocement contre mon envie de tout lâcher et je vais dédier un peu de mon temps à ce blog.
D'ailleurs, l'IRC est dans les choux en ce moment. Les amis qui hébergeaient le serveur ont disparu du jour au lendemain sans donner de nouvelle. Il faut croire qu'il ont soudain eu de nouveaux chats à fouetter eux aussi. Je vais donc prochainement créer un nouveau canal sur un réseau stable, je vous tiendrai au courant.
Merci de continuer à me lire, portez vous bien, à très bientôt. Merci d'être restés gentils.
]]>Nous avons vu il y a quelques jours les principes de base d'un répartiteur de charge et exposé brièvement les concepts fondamentaux de HAProxy. Nous avons également mené une réflexion sur la manière de gérer un certificat sur une architecture avec répartiteur de charge et la voix du bon sens nous a susurré que le certificat devait être porté par HAProxy. Bon, mettons ça en pratique.
Rangez vos affaires, sortez une feuille, interro surprise. Rappelez-moi ce qu'est le principe de base du protocole ACME. Et comme vous suivez bien et que vous buvez les paroles de l'instituteur comme un breton boit du cidre, vous saurez donc me répondre que l'agent de certification crée un challenge ACME en générant des fichiers de test auxquels le serveur ACME devra pouvoir accéder via HTTP, ces fichiers étant soit servis par l'agent via un serveur web intégré, soit mis à disposition du serveur de notre choix qui servira ces fichiers en statique. C'est en pratique presque toujours la deuxième solution qui est utilisée, sachant que justement, un serveur web tourne déjà sur les ports web standard (80 et 443). On ne veut pas d'interruption de service, non mais.
Serveur statique
Nous avons un petit problème ici. Les ports HTTP sont utilisés par HAProxy, qui n'est pas un serveur web, mais un répartiteur de charge. Souvenez-vous, il ne peut pas générer de lui même un flux web, pas même servir des fichiers statiques, il se contente de relayer des flux web créés par d'autres serveurs. Conclusion : il nous faut un serveur web tournant sur la machine hébergeant HAProxy capable de servir des fichiers statiques. L'idée, c'est qu'on va faire écouter ce serveur uniquement en local, et HAProxy se chargera de le propulser sur le réseau publique.
On n'a que l'embarras du choix pour trouver un serveur web sachant servir du bon vieux statique. On pourrait choisir Nginx ou Lighttpd par exemple, mais comme nous sommes sur OpenBSD, le choix se portera sur le serveur web déjà préinstallé, communément appelé openhttpd.
Première étape, il faut dire à OpenBSD d'activer le service.
echo 'httpd_flags=""' >> /etc/rc.conf.localAinsi on pourra démarrer le service, et il sera démarré à chaque démarrage de l'OS.
Ensuite, il va nous falloir créer un dossier qui va accueillir les fichiers du challenge ACME. Comme le processus httpd est chrooté dans /var/www (sur OpenBSD, on appelle ça un jail), ce dossier sera donc /var/www/htdocs/webroot.
La configuration de notre httpd sera on ne peut plus simple :
server "default" {
listen on 127.0.0.1 port 1375 #ça fait "let's" en l33t
root "/htdocs/webroot"
}Démarrons le service :
/etc/rc.d/httpd startNotre serveur statique est prêt.
Configuration HAProxy
Il faut dire à HAProxy de rediriger les requêtes ACME vers notre serveur statique fraîchement configuré.
Pour ça, on va définir un backend dédié à Let's Encrypt, vers lequel seront redirigés tous les flux ACME reçus sur les frontends qui nous intéressent.
backend letsencrypt-backend
server letsencrypt 127.0.0.1:1375Propre. Syntaxe explicite, pas besoin d'expliquer je pense. Je fais juste remarquer qu'en plus de nommer le backend globalement, je donne un nom au serveur du backend même si ici il n'a aucune forme d'importance, il ne sera jamais appelé ailleurs dans le fichier, c'est néanmoins obligatoire sur HAProxy. Enfin, un nom clair est toujours profitable, car il est éventuellement utilisé dans ses logs, ses statistiques et il rend la lecture du fichier de conf plus facile.
Le backend est prêt, c'est excellent, mais encore faut-il l'utiliser. Pour être exact, on ne va l'utiliser que si l'URL demandée correspond au chemin classique demandé par le validateur ACME, à savoir /.well-known/acme-challenge/. Reprenons l'exemple de la dernière fois, modifions-le de la sorte :
frontend mon_super_site
bind *:80
mode http
acl url-back-office path_dir /admin
acl letsencrypt-acl path_beg /.well-known/acme-challenge/
use_backend back-office if url-back-office
use_backend letsencrypt-backend if letsencrypt-acl
default_backend mes-frontaux
backend back-office
server backoffice 192.168.0.14:80
backend mes-frontaux
balance roundrobin
server backoffice1 192.168.0.11:80
server backoffice2 192.168.0.12:80
server backoffice3 192.168.0.13:80
backend letsencrypt-backend
server letsencrypt 127.0.0.1:1375On a ajouté une ACL et une directive use_backend. Rappelez-vous, une ACL est tout simplement une condition, ici elle porte sur le chemin de l'URL. Rien de nouveau, on a déjà expliqué le concept.
On recharge le schmilblick :
/etc/rc.d/haproxy reloadOn est prêt à générer notre premier certificat. Mais on ne va pas le faire tout de suite. Comme vous vous en souvenez, HAProxy veut ses certificats sous une forme un peu spécifique, il nous faut donc traiter le certificat dès qu'il a été généré, et pour ça on va faire un peu de scripting. On pourrait déjà générer le certificat sans le script de post-traitement, mais si on faisait ça, on devrait ensuite éditer la configuration d'acme.sh et c'est un peu barbant, sachant que la commande qui génère le premier certificat génère également par magie la configuration associée pour les renouvellements. Donc ce serait stupide.
Script de post traitement
Rien de bien compliqué, je vous rassure. Le principe est simple : HAProxy n’accepte des certificats que sous la forme d'un fichier contenant la chaîne complète de certification et la clef privée, dans cet ordre.
Le script est très simple. Vous pouvez bien entendu le mettre où bon bous semble, pour ma part j'ai décidé de le mettre dans /etc/haproxy/generate-ssl.sh.
#!/bin/sh
SITE=$1
LE_CERT_LOCATION=/root/.acme.sh/$SITE
HA_CERT_LOCATION=/etc/haproxy/ssl
cat $LE_CERT_LOCATION/fullchain.cer $LE_CERT_LOCATION/$SITE.key > $HA_CERT_LOCATION/$SITE.haproxy.pem
/etc/rc.d/haproxy reloadLE_CERT_LOCATION représente l'endroit où seront générés les certificats par acme.sh (il s'agit ici de l'emplacement par défaut, mais vous pouvez changer ce chemin à condition d'utiliser l'option adéquate lors de la génération du premier certificat).
HA_CERT_LOCATION est l'emplacement où seront créés les certificats au format HAProxy. D'ailleurs, n'oubliez pas de créer le dossier en question.
Le script devra être appelé avec en paramètre le domaine complet principal du certificat. N'oubliez pas de le rendre exécutable.
Génération du premier certificat
On y est, maintenant on va enfin pouvoir générer ce satané certificat. Partons du principe que vous avez correctement installé acme.sh, le README du projet est très simple à suivre.
acme.sh --issue -d mon-super-site.com -w /var/www/htdocs/webroot/ --renew-hook "/etc/haproxy/generate-ssl.sh mon-super-site.com" --debug
Remarquez que vous pouvez générer un certificat couvrant plusieurs domaines à la fois, il suffit d'ajouter -d mon-domaine-secondaire.com entre le domaine principal et l'option -w. Remarquez l'option --renew-hook, elle permet d'appeler le script qu'on vient de définir à chaque fois qu'un renouvellement est effectué.
Une fois la commande effectuée avec succès (ça peut prendre une minute ou deux), votre certificat est généré, il vous faut encore ajouter le certificat dans la configuration du frontend comme il suit :
bind *:443 ssl cert /etc/haproxy/ssl/mon-super-site.com.haproxy.pemComme il s'agit de la première génération et non d'un renouvellement, il est nécessaire d'appliquer le script à la main.
/etc/haproxy/generate-ssl.sh mon-super-site.comVérifiez, et pleurez de joie. Votre certificat est déployé et fonctionnel. C'est magnifique.
Automatisation du renouvellement
Ultime étape, celle qui fait prendre tout son sens à la révolution Let's Encrypt, celle qui fait qu'on peut oublier sans scrupule que tel ou tel site a un certificat proche de l'expiration, il s'agit du renouvellement automatique. Pas de subtilités, une simple ligne dans la crontab fait l'affaire. Et en plus, si je ne dis pas de bêtises, acme.sh s'occupe tout seul d'ajouter cette ligne.
26 0 * * * "/root/.acme.sh"/acme.sh --cron --home "/root/.acme.sh" > /dev/nullLa commande sera lancée tous les jours à minuit vingt-six, libre à vous de changer cet horaire. acme.sh sera assez intelligent pour savoir si votre certificat a besoin d'un coup de jeune ou non, donc rassurez vous, il n'y aura pas un renouvellement par jour.
Conclusion
Le protocole ACME peut s'appliquer à toutes les architectures web pour peu qu'on puisse traiter les requêtes du challenge correctement. À moins de disposer d'un stockage partagé (NSF, iSCSI, Samba...), il est indispensable que le challenge ACME soit créé par la machine capable de le traiter.
Illustration : The Great A'Tuin par Paul Kidby
]]>À l'époque, je vous parlais d'une infrastructure simple, à savoir un unique serveur frontal : c'est lui qui interceptait les requêtes et qui les traitait, point barre. L'infra d'un site avec une audience restreinte, car tout doit être traité par une unique machine. Bonjour l'indispo surprise.
Parlons à présent d'une architecture un peu plus ambitieuse, le genre de topologie qu'on peut trouver en production pour des sociétés importantes (et les technophiles enthousiastes). Cette première partie sera dédiée à l'explication de cette mystérieuse architecture et à la présentation d'une manière de la mettre en œuvre. Dans une seconde partie, on apprendra à y déployer ses certificats Let's Encrypt.
Souvent donc, on ne se contente pas d'un unique frontal, mais de plusieurs frontaux, sous la coupe d'un répartiteur de charge, (load-balancer en anglais) qui se chargera de réceptionner les requêtes des utilisateurs et de les distribuer aux frontaux, selon une stratégie définie. Cette architecture a quatre avantages :
- On gagne en charge maximale supportée, donc en nombre de visiteurs.
- Multiplier les frontaux amoindrit fortement les risques de crash du site, car en cas de panne d'un frontal, les autres frontaux se partagent le trafic.
- La mise en production d'une nouvelle version d'un site web peut se faire sans aucune interruption de service : il suffit de déployer sur un frontal à la fois.
- Les frontaux sont sur un réseau privés et non directement accessible sur le réseau global, donc la sécurité du site est renforcée.
On constate que le répartiteur de charge est un potentiel goulot d'étranglement et il nous faut donc un programme optimisé pour la haute disponibilité afin que le flux des requêtes ne soit pas le facteur limitant.
Disons maintenant que l'on souhaite apposer un certificat sur cette architecture. Question à dix sesterces : qui parmi ces serveurs doit porter ce certificat ?
Si on choisit de faire porter le certificat par les frontaux, cela signifie qu'il faut que tous les frontaux doivent le porter, et qu'il faudra déployer le certificat sur toutes ces machine à chaque renouvellement. Mais surtout, cela signifie que, le trafic étant chiffré jusqu'aux frontaux, le répartiteur de charge ne pourra pas prendre en compte le contenu de la requête dans sa stratégie de répartition, ce qui est fort pénalisant. En effet, il est coutume de configurer le répartiteur de charge pour distribuer certaines URL sur un pool de frontaux différent du pool normal, par exemple le back-office (la page d'administration et de saisie de contenu du site). Enfin dernier point, si vous vous souvenez du fonctionnement du protocole ACME comme décrit dans notre tutoriel, vous saurez que le certificat doit être généré sur la machine qui en fait la demande et qui répondra au challenge ACME. Ceci implique qu'un des frontaux doit être désigné pour la génération des certificat, et donc que le répartiteur de charge doit rediriger toutes les requêtes de type ACME vers ce frontal, ce qui est à la fois moche et justement impossible car notre répartiteur de charge ne peut pas comprendre ce qu'il redirige à cause du chiffrement.
La solution la plus sensée, qui maintient également le plus l'isométrie des frontaux, est de faire porter le certificat par le répartiteur de charge.
Zoomons alors sur cette fameuse machine, le répartiteur de charge. On va partir d'un socle OpenBSD. Pourquoi pas un Linux ? Parce qu'on utilise souvent la même machine pour la répartition de charge et pour le pare-feu, et qu'OpenBSD est le système de prédilection pour faire un routeur libre. Et en plus j'aime bien cet OS, ça change un peu les idées.
Sur ce socle, on va utiliser le répartiteur de charge HAProxy. Les seules tâches de HAProxy sont de porter le certificat du ou des sites (on parle de SSL-offloading) et d'aiguiller le trafic web sur les frontaux. Il ne peut pas générer de flux web par lui-même, il peut seulement relayer une requête à un autre service. Et d'ailleurs il est très bon pour ça.
HAProxy est organisé en frontends et en backends : un frontend est la façade présentée au monde extérieur qui va recevoir les requêtes des internautes. Un backend est un pool de serveurs frontaux qui va traiter la requête. HAProxy doit donc choisir sur quel backend envoyer une requête, mais il doit également gérer le pool de frontaux que représente ce backend.
Prenons un exemple de configuration simple. On passera les directives globales HAProxy qui ne sont pas intéressantes et présentent peu de valeur ajoutée. Et bien entendu, on part du principe que vos frontaux sont configurés, écoutent sur des adresses locales et tout le toutim.
frontend mon_super_site
bind *:80
mode http
acl url-back-office path_dir /admin
use_backend back-office if url-back-office
default_backend mes-frontaux
backend back-office
server backoffice 192.168.0.14:80
backend mes-frontaux
balance roundrobin
server backoffice 192.168.0.11:80
server backoffice 192.168.0.12:80
server backoffice 192.168.0.13:80Dans cette configuration, le frontend écoute sur toutes les adresses IP attribuées au serveur, sur le port 80 (donc pour le moment, uniquement du trafic en clair). Le mode HTTP signifie qu'on utilise ce frontend pour répartir du flux web, et non pas comme le mode TCP ou l'on redirige un flux TCP intouché.
On a écrit une ACL, autrement dit une condition. Retenez cette notion car les ACL sont au cœur du principe de HAProxy. Ici notre ACL est vraie si le chemin de l'URL commence par /admin et fausse sinon. On utilisera donc le backend back-office si l'ACL est vraie et sinon, on utilisera le backend par défaut mes-frontaux.
Le backend back-office est très simple car il ne comporte qu'un serveur. Le backend mes-frontaux comporte trois serveurs répartis en round-robin.
Et voilà, vous avez un répartiteur de charge. Si vous avez un certificat SSL, vous pouvez ajouter une ligne au frontend :
bind *:443 ssl cert /chemin/vers/mon/certificat.pemSauf que ça ne marchera pas. En tout cas pas tant que vous aurez mis votre certificat sous la forme attendue par HAProxy, à savoir la clef privée et le certificat dans le même fichier. Nous verrons cela dans la seconde partie, qui vous expliquera également (et finalement) comment diable utiliser Let's Encrypt avec ce bidule. En tout cas, si vous êtes perspicace, vous vous doutez que ça tournera en partie autour des ACL, car il y a bien une raison pour laquelle c'est le seul élément en gras de l'article.
(Source de l'image d'en-tête : Great A'tuin par Schiraki)
]]>Pour ceux qui ont déjà fait du développement web avec Django le titre est évident, pour les autres, bienvenue sur mon introduction à Django !
Django est un excellent framework Python qui permet de développer rapidement des applications web, et qui est très complet. Il est plus long à prendre en main que Flask, un autre microframework Python que je vais utiliser comme exemple afin d'introduire quelques concepts de Django, et de montrer que ces idées bizarres ne sortent pas de nulle part.
Parés ? C'est parti !
Prérequis
Ce tutoriel va référencer des tags du dépôt git à cette adresse. Je vous conseille aussi cet excellent tutoriel qui pourra compléter ce que j'écris ci-dessous. Enfin, la documentation de Django est complète et facile à utiliser.
Je vous conseille donc de cloner le dépôt ci-dessus :
git clone https://git.hashtagueule.fr/motius/django-tutorial.gitet de suivre les tags que j'ai indiqués au fur et à mesure de l'avancement du tutoriel grâce à la commande :
git checkout <tagname>Je préfixe les noms de tous les tags git de ce tutoriel par un "_", afin que ceux-ci ne polluent pas le projet si vous en réutilisez le dépôt git par la suite (git tag admet l'option -d pour ceux qui veulent vraiment se débarasser de mes tags).
La quasi-totalité de ce tutoriel n'impose pas d'accès root sur le système de développement, je suppose tout de même que vous avez python3 et pip3 d'installés, un accès au réseau pour les packages Python supplémentaires, ainsi que le gestionnaire de versions de code git.
J'utilise une debian GNU/Linux 9.1 Stretch pour le développement, mais ce tutoriel doit facilement être adaptable à d'autres distributions.
Commençons en douceur avec Flask.
Flask, en deux mots
Je vais me faire battre, je vais parler de Flask alors que je l'ai utilisé en tout et pour tout 7 minutes 24 secondes dans ma courte vie.
Installation
Prenons l'exemple le plus basique avec Flask. La documentation du projet se trouve ici.
Elle indique qu'il suffit de taper la commande suivante pour installer Flask :
pip3 install --user FlaskLe projet fil d'ariane
Si vous avez suivi l'étape précédente, vous savez qu'il faut revenir à la version du tag "_v0_flask" comme ceci :
git checkout _v0_flaskpour cette partie du tutoriel. Vous pouvez alors faire tourner le serveur de test à l'aide de la commande :
makeJe vais faire une utilisation intensive des Makefiles, que j'affectionne, mais je vous encourage à les parcourir pour voir ce qu'ils exécutent.
Ici, la commande est simplement :
python3 ma_flasque.pyVous pouvez alors vous rendre à l'url suivante : http://localhost:5000 dans mon cas.
Le pourquoi du comment
La partie intéressante que je voulais mettre en avant avec cet exemple concerne la structure du code Flask : j'ai divisé le source en trois parties, les imports, les routes Flask, et le code pour faire tourner l'application. La deuxième partie concernant les routes et le code métier est celle qui nous intéresse.
Les routes sont indiquées par un :
@app.route('/', methods=["GET"])tandis que le code à exécuter dans le cas où l'utilisateur demande ('GET') la page par défaut de l'application ('/') se situe dans le code de la fonction Python index, qui dans notre cas retourne la chaîne de caractères "Hello World!" (tradition oblige) :
def index():
return "Hello World!"Ainsi, Flask pose les bases de la programmation avec le motif MVC, que Django utilise : on décrit de manière séparée le code de routage des URL et le code permettant d'obtenir le résultat demandé.
Django utilisera des fichiers séparés pour le routage (Vues) et pour les fonctions Python du Contrôleur, mais le principe est le même.
Il va falloir un peu de travail pour arriver au même résultat avec Django, mais n'aillez pas peur, on y arrivera. L'essentiel est de garder les yeux sur l'objectif : avoir une séparation entre le code de routage et le code métier.
Django va un peu plus loin car il permet de s'interfacer très facilement avec une base de données et en propose une abstraction très propre, il possède un moteur de template pour prémâcher du HTML, permet d'installer des modules, mais tout ça viendra plus tard, je vous mets l'eau à la bouche...

Un gâteau au chocolat pour vous mettre l'eau à la bouche si ma description des fonctionnalités de Django n'a pas suffi.
Même résultat avec Django
Installation
La page de téléchargement de Django indique, à l'heure actuelle, qu'il suffit de taper la commande suivante pour installer la dernière version de Django :
pip3 install Django==1.11.5Si vous utilisez Django de manière professionnelle ou amateure, il faut consulter la page de téléchargement pour mettre à jour la version de Django utilisée.
Vous pouvez aussi installer la version de votre distribution, par exemple à l'aide de
su -c 'apt-get install python3-django'si vous utilisez une debian ou dérivée (Ubuntu, Mint...)
On utilisera Django dans un virtualenv Python pour ce projet.
Virtualenv
Python est un langage de programmation modulaire dont le cœur des fonctionnalités est assez réduit, mais qui reste très puissant grâce au grand écosystème disponible de bibliothèques logicielles, officielles ou tierces.
Celles-ci peuvent être importées dans un script par une primitive import du type :
import os, sys
import re
import numpy as np
from django.http import HttpResponseetc.
Les virtualenv Python servent à gérer pour chaque projet ses dépendances exactes, à l'inclusion des numéros de version des bibliothèques utilisées, et ce sans interférer avec d'autres projets.
On utilisera donc les virtualenv pour des questions de facilité, et parce qu'ils permettent de s'assurer de la pérennité d'un développement.
Vous pouvez installer virtualenv à l'aide de la commande :
sudo apt-get install python3-virtualenvou en tapant :
pip3 install --user virtualenvPremier projet Django dans un Virtualenv
La version "_v1_django" permet d'installer Django dans un virtualenv Python. Si vous avez installé Django et Virtualenv comme indiqué précédemment, l'installation devrait se faire sans retélécharger des bibliothèques Python depuis internet.
Elle suppose que vous installez toutes les bibliothèques avec pip, si ce n'était pas le cas, il faut éventuellement changer la variable VENV du Makefile, ou installer une version avec pip3.
Pour installer le virtualenv, Django, créer un projet et une application, tapez simplement la commande :
makePour l'arrêter, tapez la combinaison de touches CTRL-C.
Détaillons les étapes du Makefile :
- création du répertoire d'installation de l'environnement de développement, représenté par la variable
INSTALL_DIRdans le Makefile ; - création du virtualenv Python dans l'environnement de développement ;
- mise à jour de pip3 dans l'environnement de développement ;
- installation de Django ;
- création du projet, dont le nom est représenté par la variable
PROJECT_NAME; - création de l'application
APP_NAME.
Vous remarquerez que chacune des étapes ne modifie que le répertoire d'installation situé à l'intérieur du répertoire git, jamais des bibliothèques système.
Utilisation de Django
Jusqu'ici, on n'a toujours pas écrit de code correspondant à notre application, seulement décrit une manière générale d'obtenir un projet Django d'équerre pour commencer. Il reste quelques étapes à connaître pour avancer dans le développement d'applications web avec Django sans que celui-ci se mette en travers de notre chemin.
Migrations
Lors de la création d'un projet Django, certaines applications sont installées pour nous, par exemple l'interface d'administration. Celle-ci n'est pas migrée, opération qu'il faut réaliser pour pouvoir l'utiliser.
On a par ailleurs créé notre propre application, qui n'est pas non plus migrée.
Il est nécessaire d'effectuer les migrations des applications, car celles-ci peuvent entraîner une modification du modèle en base de données.
Obtenez le code de la version _v2_migration du projet git pour pouvoir migrer les applications du projet, et lancer le serveur Django de développement.
La commande :
makepermet d'effectuer toutes les étapes décrites jusqu'ici :
- installation de virtualenv, mise à jour de pip3, installation de django, etc. ;
- création d'un projet django ;
- création d'une application django ;
- migrations du projet et de l'application ;
- lancement du serveur de développement.
Rendez-vous à l'URL suivante pour la page par défaut de Django : http://localhost:8000
Organisation du dépôt
Le dépôt est organisé de la manière suivante :
.
+-- doc
│ \-- README.md
+-- exec\_django.sh
+-- LICENSE
+-- Makefile
+-- mon\_django
│ +-- Makefile
│ +-- mon\_app
│ \-- mon\_django
+-- README.md
\-- sandbox
+-- bin
+-- db.sqlite3
+-- include
+-- lib
+-- Makefile -> ../mon\_django/Makefile
+-- manage.py
+-- mon\_app -> ../mon\_django/mon\_app
+-- mon\_django -> ../mon\_django/mon\_django
+-- pip-selfcheck.json
+-- static
\-- templates -> ../mon\_django/templates- les sources sont dans le répertoire mon_django (nom du projet) ;
- la production est dans le répertoire sandbox ;
- les sources ont des liens sympboliques vers la production ;
- à la racine du projet se retrouvent éventuellement :
- la documentation ;
- la licence ;
- les tests (unitaires, intégration).
Cette organisation a pour but de simplifier le développement :
- le Makefile (et les scripts qu'il appelle) permet de construire et reconstruire le projet à l'aide d'une seule commande ;
- à chaque enregistrement d'une modification d'un fichier source sur disque, le serveur de développement Django redémarre avec la mise à jour, grâce aux liens symboliques vers les sources ;
- la production est séparée des sources ;
- le dépôt git peut être organisé en suivant les bonnes pratiques de développement Python :
- disposition de la documentation ;
- disposition des tests unitaires et intégration...
Comparaison Django et Flask
Ça y est, on a enfin tout un environnement prêt pour le développement. Vous allez me dire "était-ce bien la peine de faire tout ça pour en arriver au même point ?" Je crois que oui.
Avantages de Django
Pour plusieurs raisons :
- le code de Django est plus organisé que celui de Flask, ce qui procure un avantage sur le long terme :
- les vues et le contrôleur sont séparés ;
- Django incite à faire du développement de petites applications réutilisables au sein de plusieurs projets
- Django va permettre de s'interfacer facilement avec une base de données, ce qui fait qu'on a en fait de l'avance par rapport au cas où l'on serait restés avec Flask
- j'ai mis en place un système de construction avec les Makefiles qui permet de tester son application à l'aide d'une seule commande, comme pour Flask.
Je ne détaille pas les inconvénients de Django, il y en a un principal selon moi, la relative difficulté de le mettre en place, ce qui est fait par le système de construction logicielle avec Makefile.
Comprendre le code de Django en comparaison avec celui de Flask
Django fonctionne fondamentalement de la même manière que Flask pour le routage, mais il sépare les vues et le contrôleur :
- on utilise généralement le fichier
urls.pypour décrire la liste des urls proposées par une applications :- ces URL ne doivent pas se chevaucher, autrement une seule des URL serait prise en compte (la première rencontrée par Django) ;
- la liste des URL de tous les fichiers
urls.pyde toutes les applications constitue l'API backend offerte par votre projet Django ;
- on utilise le fichier
views.pypour le code métier qui va recevoir les requêtes GET/POST HTTP ; - on peut éventuellement créer d'autres modules Python pour du code spécifique ;
- on utilise le fichier
models.pypour décrire les modèles des données de l'application, tels que ces données seront sauvegardées en base de données.
Le développement avec Django
Maintenant que vous avez vu l'installation de Django en virtualenv Python, ainsi que la théorie sur la manière dont il faut organiser le code Python, allons voir quelques exemples simples.
Hello World!
Obtenez la version _v3_application du dépôt. Elle contient un simple "Hello World!" si le client demande la page http://localhost:8000/, et une simple indication "Not found" pour toutes les autres pages. Comme pour chanque étape de ce tutoriel, la commande :
makepermet de faire le café (enfin presque). Par rapport à l'étape précédente, on dispose désormais d'une application Django dont le code Python est importé.

Le café au lait que mon ordinateur ne sait toujours pas faire... Ça viendra.
En lisant le code,on s'aperçoit que son organisation est similaire à celle de Flask : d'un côté on route les urls, on utilise un ou plusieurs fichiers urls.py pour ce faire, et dans les vues du fichier views.py de chaque application du projet, on peut écrire le code à exécuter pour chaque requête.
urlpatterns = [
url('^$', views.index),
url(r'^admin/', admin.site.urls),
url('^.*', appviews.p404),
]Le routage des URL du projet (et de chacune des applications) est défini à l'aide de regex Python. Je fait correspondre les URL suivantes :
http://localhost:8000/http://localhost:8000
au code ci-dessous :
def index(request):
return HttpResponse("Hello World!")à l'aide de la première règle de routage.
La page suivante de la documentation permet une utilisation avancée des URL de routage de l'application. On peut par exemple utiliser un champ de l'URL comme paramètre.
Je ne vous ai pas promis la lune mais presque, allons plus loin dans les fonctionnalités qui sont un des grands avantages de Django.
Mon premier gabarit
La version _v4_template permet d'utiliser les templates de Django. Je n'en fait qu'un usage très limité, je me limite à indiquer à Django où il doit aller chercher les fichiers de template correspondant au code HTML/CSS/JavaScript, servis par le serveur de développement, mais ce moteur de gabarits possède de nombreuses fonctionnalités, comme les variables, les tags, des boucles, des conditions...
La page accessible à l'URL par défaut http://localhost:8000/ affiche le code du template index.html :
def index(request):
return render(request, "index.html", {})J'ai rajouté de manière explicite un paramètre optionnel : le dictionnaire vide {}. Il sert à préciser des variables Python à transmettre au moteur de gabarits.
Toutes les autres requêtes redirigent vers la page 404.
Un accès à la base de données
Une grande quantité d'applications web nécessite une base de données. Django propose un moyen simple pour s'interfacer avec une base de données sans nécessairement en connaître les subtilités, fournit des garanties qui permettent éventuellement de changer de moteur de base de données, et permet au développeur de manipuler les objets en base facilement.
La version _v5_bdd présente un exemple simple d'utilisation d'une base de données. Les URL suivantes sont valides :
http://localhost:8000/create/: crée un objet en base de données ;http://localhost:8000/delete/: supprime tous les objets ;http://localhost:8000/get_nb_objects/: affiche le nombre d'objets en base de données.
Attention, celles-ci ne le sont pas, il manque un / à la fin :
http://localhost:8000/create;http://localhost:8000/delete;http://localhost:8000/get_nb_objects.
Si vous vous demandez pourquoi l'exemple marche bien que tous les objets aient le même nom et la même valeur de booléen, c'est parce qu'ils se voient attribuer un identifiant entier automatique croissant si on ne définit pas d'attribut ayant une clef primaire, cf. la documentation.
Découpage en modules
Vous remarquerez l'utilisation de la primitive Django include dans le code, par rapport à la version _v4_template, qui permet de découper le routage vers les URL d'une application.
Utilisation d'un constructeur personnalisé
Django utilise la fonction __init__ qui sert à construire des objets Python. La documentation explique comment attacher un constructeur aux objets sérialisés en base de données, plutôt que de recourir à une méthode build comme je m'y suis pris dans l'exemple _v5_bdd. L'exemple se trouve dans le code de la version _v6_constructeur.
Pour aller plus loin
Je ferai peut-être une suite à ce tutoriel Django. Dans tous les cas, sachez que le point auquel nous sommes arrivés n'est pas suffisant ! En effet, on utilise toujours le serveur de développement de Django, qui n'est pas fait pour être utilisé en production, entre autres :
"(notre métier est le développement d’environnements Web, pas de serveurs Web)."
Mise en production
D'autres éléments sont à considérer durant et après la phase de développement :
- la mise en place d'un mécanisme de journalisation de l'application ;
- la mise en place d'un chien de garde permettant de s'assurer que le serveur (nginx, apache, ou autre) sert toujours l'application que vous avez écrite ;
- la mise en place d'une sauvegarde des données en base...
Il s'agit d'un travail d'administration système indispensable. À ce travail s'ajoute éventuellement celui de développer une interface web ou autres, si besoin est.
Modules
Je n'ai pas parlé des modules de Django. Dans la version _v4_bdd, on utilise la fonction Django render, qui permet de retourner une chaîne de caractères en temps que réponse HTTP. Cela diffère de Flask, qui permet de simplement retourner une chaîne de caractères. L'explication tient au fait que Django utilise l'objet request pour le passer aux modules Django, dans la fonction render.
Si vous êtes intéressés par le sujet, je vous conseille cette page, qui décrit les interactions possibles sur une requête, ainsi que la base de leur fonctionnement.
Réutilisation
Voilà un bon début de projet Django. Pour le réutiliser, n'oubliez pas :
- de changer la clef API située dans le fichier mon_django/settings.py ;
- de respecter la licence GPLv3.
Vous pouvez également créer un répertoire git de zéro à partir d'un des tags du dépôt exemple. Pour cela, obtenez les sources du dépôt au tag que vous souhaitez :
git checkout <tagname>Puis supprimez le dépôt git sans toucher au fichiers existant en enlevant l'arborescence sous le répertoire .git :
rm -rf ./.gitEnfin, créez un nouveau dépôt :
git initVous pouvez aussi garder le dépôt git en l'état, le script del_tags.sh permet de supprimer les tags commençant par "_".
Conclusion
Mon but ici n'est pas de prétendre que Django est meilleur que Flask, comme je l'ai indiqué au début de ce tutoriel, j'ai très peu touché à Flask. Flask est un prétexte pour moi pour montrer un des différents aspects de Django (le routage des requêtes). Par ailleurs, en lisant un peu sur le sujet, on s'aperçoit que beaucoup de modules peuvent être utilisés pour donner à Flask des capacités similaires à celles qui viennent avec Django, par exemple :
- une interface d'administration ;
- un module ORM pour s'interfacer avec une base de données...
Il y a donc des arguments en faveur de Flask par rapport à Django, par exemple :
- le code de Flask est composé de moins de lignes de code ;
- on peut choisir ce dont on a réellement besoin parmi des fonctionnalités offertes par la bibliothèque qu'on utilise...
Django, a de son côté :
- l'organisation générale d'un projet web :
- Django encourage à structurer son code ;
- Django suggère la division du code en applications ;
- il permet aux développeurs de travailler sur des applications différentes, ce qui facilite la collaboration ;
- il vient avec un moteur de templates ;
- il vient avec un ORM...
Cette comparaison n'est évidemment pas exhaustive, mais permet de se rendre compte des convergences et divergences de philosophie de ses deux projets.
Vous voilà parés pour démarrer ! J'espère que ce tutoriel vous a été utile. Pour ma part, je trouve que Django est très sympathique à utiliser, sa documentation est facile à prendre en main pour un usage débutant, même si elle est touffue. Enfin sachez que raspbeguy et moi-même avons quelques projets web (parmi lesquels clickstart, et Hashtagueule Express) qui utiliseront peut-être cette technologie.
Bonne journée et bon développement Python/Django !
Motius
PS : après avoir commencé cet article, je suis tombé sur celui-ci, en anglais. Je tiens à le mentionner car la majorité des articles Flask vs Django sont théoriques (souvent des descriptions fonctionnelles, assez intéressantes pour se familiariser rapidement avec les deux projets), mais je n'avais pas vu (ni vraiment cherché) d'article les comparant en mettant la main dans le code.
]]>Aujourd'hui je vais me concentrer sur les outils de lecture et de gestion de contenus multimédias : images, films, et surtout musique, ce dernier média étant celui que je bichonne le plus avec une bibliothèque de plusieurs mois de longueurs cumulées et presque 500 Go de taille. Ça commence à faire gros et automatiser la gestion d'un machin pareil devient assez nécessaire.
D'aucuns pourraient se dire que visionner du contenu multimédia sur un poste qui veut se passer d'environnement graphique, c'est un peu contradictoire. Mais rassurez-vous, il n'en est rien, c'est tout à fait possible, et même conseillé dans certains cas (histoire de réserver de la ressource pour lire le média lui-même et non pour gérer un ensemble d'effets de fenêtres débile qui fait prout quand on les ferme). Je vais donc vous exposer des outils KISS, faisant le travail demandé, ni plus, ni moins.
Images
Pour ouvrir des images, feh fait très bien le travail. Ça ouvre les jpg, png, gif, et bien d'autres, en fait tous les formats supportés par Imlib2. Il suffit de l'invoquer de la sorte :
feh rem\_is\_best\_waifu.pngÀ l'aide d'ImageMagick, ça peut même convertir d'autres formats afin de les ouvrir, par exemple le svg. Il suffit de donner une valeur de timeout à ImageMagick :
feh --magick-timeout 5 logo\_hashtagueule.svgAstuce, si vous avez des images de grande dimension et que vous souhaitez adapter automatiquement la taille à la fenêtre de feh, ajoutez l'option suivante :
feh -. playboy\_special\_tshirt\_mouille.jpgOn peut même s'en servir pour le fond d'écran :
feh --bg-scale windowsXP\_wallpaper.jpgCette commande va créer par la même occasion un petit script ~/.fehbg afin de faciliter l'instauration du fond d'écran. Il suffira donc de dire à X11 ou à votre gestionnaire de fenêtre préféré de lancer ce script à chaque début de session (pour i3 on avait vu que ça se faisait avec la directive exec).
Enfin, sachez que feh peut également ouvrir des images distantes via HTTP.

Vidéos
La plupart des gens, si on leur dit "vidéo sur linux", ils répondront à la microseconde et le plus fort possible "VLC!!!". Sachez qu'il n'y a pas que VLC dans la vie, mes enfants. Mon avis est que, même si VLC c'est très bien pour amener de l'open-source en terrain ennemi (ça tourne partout, y compris Windows et Mac), ça a une interface intuitive (c'est du QT, portable sur toutes les plateformes) et relativement facile à mettre en œuvre grâce à là nucléarité de ses fichiers d’exploitation (La plupart des bibliothèques utilisées par VLC sont des bibliothèques maison, et il y en a très peu), ben ces avantages apparents sont en partie des inconvénients pour les utilisateurs avancés. L'interface agréable, la belle affaire quand on veut se passer d'environnement graphique. La nucléarité de VLC également est un problème : ce sont des bibliothèques que seul VLC utilise ; résultat, personne n'y comprends plus rien et ça fait doublon avec d'autres bibliothèques plus communes et à mon sens plus propre.
Bref, pour toutes ces raisons j'ai renoncé à VLC. Quand on y réfléchit, les raisons sont presque les même que les arguments contre GNOME.
À la place, j'utilise mpv, qui a vraiment une interface minimale (et par conséquent élégante), et qui est plus léger que VLC, et ça se voit quand on lis des vidéos sur des machines pas super récentes.
mpv a un système de raccourcis clavier hautement configurable et possède les même fonctionnalités que VLC. Il possède également un mécanisme d'accélération graphique.
Bon, vu que je m'y connais pas vraiment côté vidéo, je vous laisse avec une capture d'écran.
 Rem is best waifu
Rem is best waifu
Musique
Bon, là c'est du sérieux. Je ne gère pas de photothèque, et mes bibliothèques de films et de séries ne nécessitent pas beaucoup d'effort pour rester rangé. Mais la musique c'est une autre paire de manche.
Gestionnaire de musique
Pour ranger ma musique, jusqu'il n'y a pas si longtemps, j'utilisais l'utilitaire graphique Ex Falso, livré avec le lecteur de musique Quod Libet. Ces deux programmes sont très bons, c'est ceux que j'utilisait quand j'étais encore sous Cinnamon. Ex Falso est très puissant et permettait de faire des opérations sur des fichiers audio : modification des tags manuellement, par nom de fichier, ou encore et surtout l'opération inverse, à savoir changer l'emplacement et le nom de fichier en fonction des tags. L'ennui c'est que c'est du GTK, et pas d'interface en ligne de commande donc pas scriptable du tout.
Je me suis finalement mis à beets, un outil full CLI destiné à maintenir une bibliothèque de musique rigoureusement organisée, que j'exécute directement sur le NAS. Beets peut à peu près tout faire et répond à toutes les demandes, pour peu qu'on passe du temps à comprendre toutes ses options. Et Dieu sait qu'il y en a beaucoup.
Beets intègre un autotaggeur, c'est à dire que par défaut, il va chercher les tags des nouveaux fichiers. Sachant qu'en général les fichiers que j'importe sont déjà correctement taggés, j'ai choisi de désactiver cette fonctionnalité (et j'ai trop peur de ce qui arriverai si beets se plantait). Par contre, je l'utilise pour qu'il intègre mes nouveaux fichiers dans l'arborescence correcte. Je tiens à ce que ma bibliothèque soit rangé ainsi (pour faire simple) : racine/artiste/album/numdisque_numpiste-titre.flac
Voici mon fichier de configuration (il est ridiculement petit et n'exploite qu'un fragment des possibilités de beets) :
directory: /mnt/data/multimedia/Musique
import:
copy: yes
#incremental: yes
log: ~/.config/beets/beets.log
autotag: no
paths:
default: %if{$albumartist,$albumartist,%if{$artist,%artist,unknown}}/%if{$album,$album,unknown}/%if{$disc,$disc-}%if{$track,$track - }$titleMaintenant, quand je veux importer de nouveaux fichiers, il me suffit d'invoquer beets de la sorte :
beet import /chemin/vers/dossier/contenant/nouveaux/morceauxEt paf, ça fait le taf. Bon je vous laisse lire la signification des instructions sur la (très bonne) documentation de beets. Vous allez vous en sortir, je crois en vous.
Lecteur de musique
C'est là que le bât blesse. En fait je n'ai pas encore trouvé le lecteur qui couvre exactement % de mes besoins. Je suis partagé entre deux programmes, qui ont chacun des avantages.
MPD
Mon rêve c'est de ne pouvoir tourner qu'avec MPD. Je vous en ai déjà parlé sur l'article Un jukebox à partir d'un Raspberry Pi en vous disant que ça déchire, et c'est effectivement le cas. Ça ne consomme quasiment aucune ressource, ça peut lire plein de formats, ça se contrôle avec un protocole simple (même avec MPRIS2, le protocole universel de contrôle de lecteur multimédia sur Linux, grâce à l'outil mpDris2) et ça vous fout la paix. Le problème, c'est que tous les clients MPD en ligne de commande que j'ai trouvé ont à mon sens une interface peu ergonomique. Le meilleur candidat étant ncmpcpp (déjà il à un nom à coucher dehors), l'ergonomie de son interface (pourtant en très joli ncurse, et vous savez à quel point j'aime ncurse) ne m'a pas emballé. Naviguer dans sa bibliothèque est assez douloureux, la répartition des différentes vues du programme sont pour le moins folkloriques, les raccourcis clavier par défaut sont assez déroutant... Dommage.
cmus
On parlait d'interface, et cmus en a une très réussie et intelligemment pensée. Les utilisateurs de lecteurs de musique graphiques comme Rhythmbox, Quod Libet ou encore iTunes s'y retrouveront assez facilement. Et depuis la version 2.8, encore au stade de release candidate, on peut également le contrôler nativement par MPRIS2. Le problème est qu'il s'agit uniquement d'un lecteur local, pas prévu pour être contrôlé depuis une autre machine que celle sur laquelle il est exécuté (ou alors on le contrôle depuis une session tmux sur la machine distante, mais c'est sale, et de toute façon, on perd les avantages de MPD mentionnés). Là encore, c'est dommage.
 mcmpcpp à gauche, cmus à droite. Et pour rajouter du kikoolol, l'utilitaire cava en bas.
mcmpcpp à gauche, cmus à droite. Et pour rajouter du kikoolol, l'utilitaire cava en bas.
L'idéal pour moi serait donc un cmus qui contrôlerait MPD, mais à en croire la réponse à une feature request, c'est loin d'être à l'ordre du jour hélas.
Je me suis donc résolu à utiliser MPD pour le seul usage sur mon installation audio dédiée, et cmus quand j'ai besoin de travailler avec des écouteurs, au boulot comme à la maison.
N'hésitez pas à me dire votre avis, notamment si vous avez un client MPD préféré, et nous dire qui est votre waifu. Rem c'est la mienne alors pas touche.
]]>Je vous présente Clickstart. Enfin, ce qui sera Clickstart. Il s'agit d'une idée qui me trotte derrière la tête depuis plus d'un an maintenant. J'ai pris conscience que l'extension de domaine .ART était enfin sorti de sa période landrush et que tout le monde pouvait à présent en acheter un domaine sans être obligé d’hypothéquer un de ses reins. J'ai donc acquis le domaine, ce qui a mentalement déclenché la processus de production.
Clickstart, c'est une plateforme visant à créer une communauté d'artistes débutant et/ou en manque de moyens de gagner de la popularité, dans laquelle chacun sera libre de partager son travail et de faire son trou comme il peut. Aucune censure n'y sera mise en place (mis à part sur le contenu prohibé par la loi, tel le contenu pédopornographique) avec création de filtres pour ne pas heurter les utilisateurs les plus sensibles. Tous les arts sont concernés, pour peu qu'il ait un support : Musique, livres, cinéma, jeux-vidéos, dessin, photo... De nouvelles catégories pourront être créées au besoin.
Voici une liste des fonctionnalités qui seront au rendez-vous, à plus ou moins grande échéance :
Dès le jour de sortie :
- Pages personnelles avec description, mise en avant des travaux préférés par le publique ou par l'artiste, diverses infos, liens externe, et cætera.
- Comptes d'utilisateurs non-artistes.
- Groupes de travail, permettant à plusieurs artistes de collaborer et présenter leur travail sur un pied d'égalité.
- Liens de téléchargements, dans un premier temps sur des serveurs externes.
- Travaux classés par type d'art (catégories) et par style artistique (étiquettes).
- Commentaires de la communauté sur les œuvres et sur la page des artistes/groupes.
- Flux de nouvelles (RSS/Atom) propres à un artiste/groupe/catégorie/étiquettes.
À long terme :
- Mise à disposition d'un espace d'hébergement pour les œuvres.
- Page entièrement personnalisable pour les artistes (possibilité de créer ses propres CSS).
- Création automatique de fichiers torrents pour proposer une alternative au téléchargement direct.
- Création de galeries de favoris.
Des questions ?
C'est quoi ton argument face aux trucs qui existent déjà genre Bandcamp, Deviantart, Soundcloud, YouTube, etc ?
Déjà, un peu de compétitivité n'a jamais fait de mal. Ensuite, ces plates-formes ont en commun de ne présenter qu'un unique type d'art. Et ne venez pas me dire que YouTube propose plusieurs types d'art : c'est peut être vrai, mais YouTube a clairement été conçu pour de la vidéo. Les morceaux de musiques qui y sont présents ne sont que des bandes sons de vidéos, en glorieux MP3 pourri (ou autre format avec pertes, je sais plus).
Je pense qu'il est nécessaire qu'il existe un endroit où toutes les formes d'art puissent cohabiter, sachant que souvent des œuvres sont tout bonnement inclassable. Je souhaite également que la plateforme soit très à l'écoute de ses utilisateurs : Si quelque chose est impossible, on réfléchit et on trouve une solution.
Il faut également savoir que l'intégralité du code source du site sera mis en licence libre. Bah oui, je reste un gentil du net quand même.
D'autre part, il faut aussi prendre en compte le public visé par cette plateforme. C'est bel et bien les artistes tout frais qui seront visés. Le site sera pensé de telle sorte qu'il soit une aubaine pour tous ces nouveaux artistes et peu avantageux pour un artiste devenu populaire.
Tu vas interdire aux gros artistes d'utiliser ta plateforme ? Même Johnny Hallyday ?
Interdire, bien sûr que non, soyons sérieux. Sur quel critère ? Quelle limite de popularité pourrait-on se fixer ? De toute façon, je crois bien que c'est pas vraiment autorisé de refuser l'accès à quelqu'un pour de telles raisons, et c'est en plus contre toutes mes convictions. Non, absolument rien ne sera différent dans les conditions d'utilisation pour un Gérard Lagratte, plombier de métier se sentant l'âme d'un artiste, et un Johnny Hallyday ou une Lady Gaga. Toute l'astuce étant que dans ce dernier cas de figure, l'artiste n'a aucun intérêt à utiliser la plateforme (en tant qu'artiste entendons-nous bien). Pareil pour les artistes arrivés petits, mais devenant "trop" populaires : ils vont vite se sentir à l'étroit sur Clickstart et ils partiront d'eux même vers d'autres horizons. C'est pas que je veux qu'il partent, c'est juste comme ça, on ne peut offrir que ce qu'on a dans une certaine limite.
Est-ce que les artistes pourront vendre leur œuvres sur Clickstart ?
Absolument pas. Ce serait bien évidemment à la fois une tonne de paperasse et de contrôle fiscaux pour moi, et en opposition avec le fil rouge du site. Sur Clickstart, on gagne de la popularité et du respect de la communauté. Pas d'argent. Il existe des plate-formes très efficaces pour ça. Donc je te coupe tout de suite sur ta prochaine question : non il n'y aura pas de DRM. Autant je n'ai rien contre gagner de l'argent avec son art, ce qui est normal, autant les DRM, j'affirme haut et fort que c'est mal.
Tu as assez de place sur tes disques pour héberger tout le contenu artistique des utilisateurs ?
Ta question est bête, Antoinette, mais le sujet ne l'est pas, Roberta. Bien entendu que quand le site gagnera en popularité, si tout le monde dépose du contenu comme des gros porcs, je vais vite poser la clef sous la porte. Mon plan d'attaque est d'imposer des quotas, genre pas plus de 5 Go par utilisateur dans un premier temps. Il faudra que j'y réfléchisse. Ensuite, si la demande d'espace supplémentaire est forte et/ou y a vraiment plein d'utilisateurs (ce qui est une bonne chose hein), je vais devoir proposer des plans payants. Eh oui, l'espace disque, c'est pas gratuit malheureusement, si vous me croyez pas, allez lire mon tutoriel sur le RAID. Ça ne m'a jamais dérangé de mettre un peu de ma poche pour héberger des projets, mais là, ça fait un gros paquet de poches à retourner.
Ce sera francophone ?
Il s'agit d'un site international. Donc dans un premier temps, le site sera uniquement en anglais. Après, rien n'empêche les artistes de publier dans un autre langues, à eux de voir.
Bon, c'est prévu pour quand la mise en ligne ?
Pour l'instant je suis tout seul à travailler dessus. Ça dépendra du monde que j'arriverai à embrigader, mais je planche sur fin printemps 2018. Vous trouvez le temps long ? Ben alors venez m'aider ! Ça va finir par devenir un running-gag venant de moi de demander de l'aide sans arrêt. En tout cas, vu que j'aime bien le Python, le choix de la techno s'est arrêté sur Django. En plus Motius me l'a conseillé, et vous savez l'importance que j'accorde à son opinion. Y a plein de choses à faire, du dev et du design. Parce que j'ai envie que le look du site roxe du poney. Je veux un truc de ouf.
Comment garder un œil sur l'avancée du développement ?
Il est vrai que le syndrome Korben ça va bien 5 minutes, et je vais très peu reparler de Clickstart sur Hashtagueule. Donc vous savez où me trouver sur IRC. En plus, un canal IRC dédié a été ouvert, il s'agit de #clickstart sur freenode, ainsi qu'un salon Discord (pas taper s'il vous plaît, faut chercher le publique là où il est). Ces deux salons sont en anglais uniquement.
Bon, ben j'ai à peu près tout dit. N'oubliez pas que vous pouvez participer à l'aventure. J'accepte également les petits mots d'encouragement, c'est bon de savoir son travail utile et désiré.
EDIT : J'ai ouvert un blog de développement. Y a un RSS et tout ce qu'il faut.
À la prochaine.
]]>En théorie
RAID est l'acronyme de Redundant Array of Independent Disks (Alignement redondant de disques indépendants), et comme son nom l'indique, il va permettre de regrouper plusieurs disques durs et d'y instaurer une politique de stockage pour faire de la redondance, de l’agrégation de taille, enfin ça répond à plein de besoins différents. En fait on ne devrait pas vraiment parler d'un seul RAID, mais bel et bien de la famille des RAIDs, car en effet il y a autant de RAIDs que de besoins différent.
On va présenter les assemblages RAID les plus utilisés. Pour plus de détails, je vous conseille la page Wikipédia qui est très claire et qui contient des schémas très explicites.
Dans la suite, on va beaucoup parler de bandes de stockage : il s'agit d'une quantité de stockage de valeur prédéfinie, qui correspond à une "section" contiguë du disque qui la contient. Dans ce modèle, lors de l'écriture sur le volume, une bande est d’abord remplie avant d'en entamer une suivante. Il s'agit en fait d'abstraire le stockage et de pouvoir mieux comprendre la répartition des données sur les différents disques.
RAID 0
Les bandes sont tout bonnement distribuées sur les disques, toujours dans le même ordre. On remplit donc une bande par disque, puis une fois qu'on a touché à tous les disques, on repart du premier disque et on recommence une couche de bandes. Tous les disques contiennent des données différentes. Ainsi, si vous avez n disques durs de capacité exploitable x, la capacité totale du montage sera nx.
- Avantages : Ce montage permet d'utiliser le plus grand espace possible de votre assemblage. De plus, en moyenne, les accès disques parallèles seront plus rapide, pour peu que ces accès disques se fassent dans des bandes différentes et sur des disques différents.
- Inconvénients : Il suffit de perdre un seul disque pour corrompre l'intégralité des données. Or, statistiquement, plus on a de disques, plus on a de chances d'en perdre.
RAID 1
Les bandes sont écrites à l’identique sur tous les disques. Tous les disques contiennent exactement les même données. Ainsi, si vous avez n disques durs de capacité exploitable x, la capacité totale du montage sera x.
- Avantages : C'est le montage qui permet la plus grande sécurité des données faces aux pannes : tant qu'il vous reste un disque fonctionnel, vos données sont intactes et complètes. Les accès disques sont aussi nettement améliorés, avec une vitesse théorique multipliée par le nombre de disques dans le montage.
- Inconvénients : Il est frustrant d'avoir beaucoup de disques durs pour avoir au final l'espace d'un seul disque. Évidemment les données sont très sûres mais quand même, faut pas pousser...
RAID 5
Les bandes sont réparties sur tous les disques sauf un, qui reçoit une bande de parité. La bande de parité est tout simplement une bande dont chaque bit est obtenu en appliquant le OU exclusif (XOR) à l'ensemble des bits correspondants dans les bandes alignées des autres disques. Cette bande de parité est attribuée à chaque disque alternativement au fil des couches de bandes remplies. Donc si un disque vient à tomber en panne, pour chaque couche de bande, si la bande du disque en panne est la bande de parité, alors les données de la couche sont intactes. Si la bande contient de la donnée, alors elle peut être recalculée à partir des autres couches de données et celle de parité. C'est du calcul logique, et c'est la force du XOR. Ainsi, si vous avez n disques durs de capacité exploitable x, la capacité totale du montage sera (n-1)x.
- Avantages : Un bon compromis entre place exploitable et sécurité des données. On se donne le droit de perdre un disque dur dans la bataille. Pour retrouver l'usage des données, il suffit de remplacer le disque défaillant et les données sont reconstruites.
- Inconvénients : Ça dépends des cas, mais un droit à un unique disque dur en panne, ça peu être peu. Pour certain ça peut être insuffisant.
RAID 6
Il s'agit d'une extension du RAID 5 dans laquelle on se permet de pouvoir perdre plus d'un disque. La solution étant d'attribuer plus de bandes de "parité" par couche, une par nombre de pannes maximum permises. Ici, j'utilise les guillemets car il ne s'agit plus vraiment de la parité simple de la logique de base, mais d'un truc chelou reposant sur un principe tout autre dont je ne pas trop vous parler parce que j'en ignore tout. Donc si vous avez n disques durs de capacité exploitable x, et si vous mettez en place k bandes de redondance par couche, la capacité totale du montage sera (n-k)x.
- Avantages : On se sent un peu plus à l’abri des intempéries matérielles, au pris d'un peu de place de stockage.
- Inconvénients : Le principe chelou dont je vous ai parlé, enfin dont je ne vous ai pas parlé pour être honnête, eh bien il est tellement chelou qu'il pète pas mal les performances. Et pour couronner le tout, la plupart des implémentations de ce type d'assemblage est bien moins stable que les autres.
Il est également possible de combiner les RAIDs. Une combinaison fréquente est le RAID 10 (RAID 1 + RAID 0). Par exemple si on a 10 disques, on peu monter 2 RAID 1 de 5 disques chacun, puis assembler ces deux volumes en RAID 0. On a également aussi le RAID 50, combinaison dur RAID 5 et du RAID 0 selon le même principe.
La gestion du RAID
Je vous parlais de différentes implémentations du RAID. En fait, le RAID n'est pas un programme en tant que soi, juste un ensemble de spécifications. Du coup chacun y va de sa sauce : il existe des implémentations libres et propriétaires, logicielles et matérielles. Les solutions matérielles se basent sur du matériel dédié (un contrôleur RAID), le système d'exploitation n'a donc pas à s'occuper de ça et le plus souvent ces solutions marchent out of the box, sans avoir besoin de configurer quoi que ce soit. Mais elles ont l'immense inconvénient d'être propriétaire dans leur quasi-totalité, et pour le coup il n'existe aucun standard. Dans certains cas, si votre contrôleur RAID rend l'âme, il vous faudra acquérir exactement le même modèle de contrôleur, sinon, peu importe que vos disques soient tous intacts, plus rien ne pourra les lire, et vous serez alors en légitime position d'être fort contrarié. À mon humble avis, le principal argument des RAIDs matériel auparavant était les meilleures performances. Aujourd'hui cet avantage est de plus en plus obsolète, car désormais les machines sont bien plus puissantes qu'il y a 15 ans et les programmes de RAID ont été nettement optimisés et stabilisés. Cette différence de performance est aujourd'hui presque intangible.
En pratique
J'ai hérité par un ami d'une tour de bureau. Elle est bien cool car elle contient une grande baie de disques et pas mal de ports SATA (bien entendu, vous pouvez faire votre RAID avec des disques branchés en USB si vous le souhaitez). J'ai donc décidé d'en faire un NAS fait main.
Choix des armes
J'ai donc initialement acheté 3 disques de 3 To chacun (des Western Digital Red, gamme dédiée justement aux usage en RAID) et j'ai opté pour un RAID 5 logiciel. Et sur Linux, le programme de RAID par excellence est mdadm. J'ai décidé de garder branché le disque dur d'origine (500 Go) mais de ne pas l'intégrer au RAID, il sert uniquement de disque de démarrage. Notez que si j'avais voulu optimiser les performances, j'aurais pu troquer ce disque pour un petit SSD, mais bon, je suis déjà content comme ça.
Par ailleurs, pour faire de la place dans la baie de disques, j'ai du déménager le disque de démarrage dans la baie frontale, celle destinée à accueillir les périphériques comme le lecteur optique.

Le 4ème disque du RAID, on en parlera plus tard. Je l'ai acheté bien après.
Pour ça j'ai utilisé un adaptateur 3,5 pouces vers 5,25 pouces bien pratique, qui m'a permis de fixer bien solidement le disque dur au lieu de le laisser se balader dans la tour.
Partitionnement et formatage
Du côté software, je me retrouve avec un disque sda de démarrage, et sdb, sdc et sdd des disques vierges prêts à être assemblés en RAID. Avant ça, j'ai besoin de les partitionner. J'utilise donc fdisk pour les trois disques à tour de rôle, je choisis une table de partitions GPT et j'y crée une unique partition de type "Linux RAID" (code 29 dans fdisk).
Création de l'assemblage RAID
C'est tout bête, ça tient en une seule ligne de commande :
mdadm --create --verbose /dev/md0 --level=5 --raid-devices=3 /dev/sdb1 /dev/sdc1 /dev/sdd1Dans cette commande, j'indique que le nom du volume abstrait sera /dev/md0, que ce sera un RAID 5, qu'il comporte 3 disques et je lui précise les partitions que je veux utiliser.
Pour suivre l'évolution de la création de l'assemblage, jetez un coup d'oeil au fichier /proc/mdstat. Ce fichier sera votre nouvel ami, c'est lui qu'il faudra consulter dès que vous ferez une opération qui touche au RAID.
Puis j'ajoute l'assemblage à la configuration de mdadm pour que celui-ci me l'assemble au démarrage :
mdadm --detail --scan >> /etc/mdadm.confPuis il ne vous reste plus qu'à mettre votre système de fichier préféré sur le volume créé !
mkfs.ext4 /dev/md0Pour que votre assemblage soit monté au démarrage, j'ajoute à mon /etc/fstab :
/dev/md0 /mnt/data ext4 defaults 0 0Il ne faut pas confondre assemblage et montage, il s'agit de deux étapes lors de la connexion d'un RAID. On doit assembler un RAID afin qu'il soit reconnu comme un volume propre, puis on doit monter notre volume pour pouvoir lire et écrire dessus.
Enfin on monte le volume :
mkdir /mnt/data
mount /mnt/dataAyé vous avez un RAID 5 qui fonctionne !
Il est recommandé de procéder régulièrement à des reconstruction de RAID, opération qui va vérifier la cohérence de l'assemblage. Il s'agit d'une opération transparente mais qui dure plusieurs heures et qui va se traduire par une forte augmentation de l'activité des disques. Pour ça il vous faudra lancer un petit programme sans arguments, raid-check, à un intervalle raisonnable, disons, toutes les semaines. Choisissez un horaire de faible activité, comme la nuit du samedi au dimanche à 3h du matin. Pour ça, faites vous plaisir, entre la crontab et les timers de systemd, on manque pas de solutions.
Ajout d'un nouveau disque à l'assemblage
Mon RAID 5 était constitué de 3 disques de 3 To ce qui nous fait 6 To exploitables, si vous avez bien suivi. 6 To, c'est un grand espace, il m'a suffi pendant presque 2 ans... Puis j'ai eu besoin de plus de place. J'ai donc racheté un autre disque (même modèle, même taille) que j'ai fourré dans ma tour. Je vous avoue que sur le coup, j'étais encore puceau au niveau extension de RAID, j'ai donc flippé énormément et j'ai fait une sauvegarde de mes 6 To sur divers disques externes que j'ai pu trouver dans ma caverne. Je vous raconte pas comme c'était pénible...
Petites observations à ce niveau :
- Remarquez que l'ordre des disques dans le nommage des périphériques physiques (sdX) et tout sauf fixe. En théorie, il faut être préparé à ce que vos disques changent de noms. Votre petit
sdbchéri que vous avez bordé et vu s'endormir dans le creux douillet de son lit un soir peut très bien vous trahir et s'appelersdcau petit matin dès le prochain redémarrage. Bon c'est un peu exagéré, mais une chose est sure, il ne faut jamais faire confiance au nommage des périphériques physiques (c'est pour ça entre autres qu'il faut privilégier la désignation par UUID dans la fstab). - mdadm se fiche complètement du nommage de ses périphériques. Il utilise sa propre magie noire pour déterminer les membres d'un assemblages. En conclusion, ne vous tracassez pas pour retrouver le nom de vos disques de votre assemblage, mdadm, lui, s'y retrouvera toujours.
Cependant, faites quand même gaffe lorsque vous allez ajoutez votre nouveau disque dur. Par exemple chez moi, le nouveau disque s'est vu nommé sdb, tandis que les autres s'étaient vu relégués en sdc, sdd et sde. Faut juste le savoir et traiter les disques pour ce qu'ils sont, et non pas des étiquettes à trois lettres.
Tout ce que j'ai eu à faire, en définitive, a été de partitionner-formater mon nouveau disque ainsi que l'ont été ses aînés, puis j'ai lancé les deux commandes suivantes :
mdadm --add /dev/md0 /dev/sdb1
mdadm --grow --raid-devices=4 --backup-file=/root/grow\_md0.bak /dev/md0La première va juste indiquer à mdadm qu'on lui ajoute un disque, mais sans plus. C'est la deuxième commande qui va lancer l'opération de reconstruction (rééquilibrage de l'assemblage). Opération qui dure plusieurs heures, donc suivez son déroulement dans /proc/mdstat.
Une fois que c'est terminé, il faut maintenant procéder à l'extension du système de fichier lui même. Et là vous priez pour avoir choisi un système de fichier pas trop stupide qui accepte ce genre d'opération. Rassurez-vous, ext4 le supporte très bien.
Il le supporte même tellement bien que vous pouvez le faire directement à chaud, sans démonter votre volume. Pour ça, premièrement, si vous utilisez une connexion SSH, ouvrez une session tmux. Il serait bête qu'un incident réseau de rien du tout vienne corrombre tout votre système de fichire tout de même. Puis il vous faudra exécuter :
resize2fs -p /dev/md0Il va vous mettre en garde et ronchonner un tantinet que votre disque est toujours monté, mais écoutez, il s'en remettra, dans la vie on fait pas toujours ce qu'on veut. Les minutes passent, vous vous rongez les ongles, vous prenez un café, vous videz un pot de glace, et normalement, si tout se passe bien, le système de fichier aura été étendu à tout l'espace disponible sur l'assemblage. Félicitations !
Conclusion
J'ai rencontré beaucoup de monde m'ayant dit qu'ils préféraient rester éloigner autant que possible de RAID parce que ça leur faisait peur. En réalité, il n'y a rien d'effrayant là dedans. mdadm est un outil ma foi fort bien codé et les années ont prouvé qu'il était fiable. Il ne faut pas avoir peur du RAID. Enfin un peu quand même, faut pas faire n'importe quoi.
]]>Bon, on va passer la partie plan-plan de l'évènement. Gâteaux, confettis, tout ça. Passons d'emblée au bilan.
Ah tiens, c'est vrai qu'on avait déjà établi un plan l'année dernière, voyons si on a été bons.
Premièrement, nous allons bien sûr continuer d’écrire.
Bon ça, ça va. On a sûrement pas écrit autant qu'on aurait du mais bon, au moins on a tenu la barre.
Nous aimerions également enrichir notre équipe de rédaction.
Hum, ça coince de ce côté là. On est toujours deux à tenir le bar. Faut dire qu'avec mes piètres talents en communication, on s'est également un peu chamaillé avec d'autres personnes, tss, pour des broutilles. Enfin bon, ce qui ne vous tue pas vous rends plus fort, pas vrai ?
On a essayé des trucs cela dit. Par exemple on est devenu partenaires avec Freemind Gentoo-nazis Alfra, un collectif qui de prime abord a un peu le même but que nous, à savoir sensibiliser les gens sur le libre, la neutralité du net et tout le toutim. Bon, ce collectif connaît à présent un petit vide d'activité en ce moment, mais bon, on lui souhaite un prompt rétablissement.
En tout cas c'est l'occasion pour moi de renouveler mon appel à bonnes volontés, on vous offre la chance de devenir contributeur sur un projet sympa. N'hésitez pas à nous contacter.
Nous avons aussi le projet de créer une partie dédiée au news rapides / partage de news.
Alors ce serait quand même faux de dire qu'on a pas avancé. Disons qu'on a principalement avancé à la façon de Thomas Edison, à savoir qu'on a trouvé des manières ingénieuses de ne pas réussir un tel projet. Mais c'est pas tout, on a aussi un projet qui a l'air de tenir plus longtemps que les autres, en python, tenu par notre ami Motius à ses heures perdues. Moi j'y crois et je pense qu'il va aboutir un jour.
Bon sinon, y a quand même des trucs qui se sont passés. Par exemple, maintenant j'ai un boulot, ce qui me permet de payer un serveur qui peut virtualiser, et donc pouvant jouir d'une administration plus flexible et agréable.
Bon ben voilà, "Putain deux ans" comme dirait Chirac aux Guignols, avant que ça devienne une émission fade et pas drôle aux mains d'un patron un peu trop susceptible.
Restez avec nous, restez gentils.
]]>...
Nan j'déconne.
Enfin je vous conseille quand même de faire la mise à jour bien entendu, pour des raisons évidentes de sécurité, prévoyez de le faire au moins à long terme. Parce que bon, la oldstable est toujours supportée à travers des mises à jour de sécurité, mais après y a plus rien, et votre serveur est livré à lui même et aux attaquants qui sauront profiter de failles non corrigées.
Ce que je veux dire, c'est qu'en mettant à jour votre distribution, attendez-vous à des trucs qui vont péter sévère. Faites-ça quand vous n'avez rien d'autre à faire et quand un minimum de choses vitales sont attendues de votre serveur par vos utilisateurs. Va y avoir du vilain.

Donc oui j'aime Debian, mais Debian me gonfle parfois. Notamment ce comportement très fâcheux que je viens de découvrir aujourd'hui même concernant OpenVPN.
OpenVPN, j'en ai déjà parlé et je ne m'étendrai pas plus là dessus, est un outil permettant de construire des réseaux virtuels privés (VPN), utiles pour abstraire des réseaux entre des machines géographiquement distantes et/ou pour déporter son point de sortie pour "sembler" se connecter d'ailleurs. Il y a donc une machine qui crée le VPN, dite serveur ou tête de pont, et des machines qui s'y connectent à distance, dites clients.
J'ai donc une tête de pont que j'ai récemment mis à jour sur Stretch. Tout se passa bien entendu parfaitement en apparence, et tout le monde il était beau. Je me retrouvai avec une jolie Debian Stretch toute mignonne dont le cœur et l'âme n'aurait en aucun cas pu être mis en doute par quiconque. Sauf que sous ses jupons, elle avait dissimulé des trucs moins fun. Et en conséquence, quelques jours après, je me rendis compte que mes clients OpenVPN ne se voyaient plus. Je ne mis pas longtemps à soupçonner la belle Stretch d'avoir des aveux à me faire.
L'élément fautif : le service Systemd a changé bien en profondeur. Sous Jessie, les fichiers nécessaires pour l'établissement du VPN (configurations, certificats, clefs...) se trouvaient alors modestement dans /etc/openvpn, et ne faisait pas la distinction entre configurations clients et configurations serveurs. Le service utilisé pour démarrer OpenVPN était nommé tout simplement openvpn.service, et son boulot était uniquement de lancer une instance d'OpenVPN par fichier de configuration (dont le nom se terminait par .conf) dans ce dossier. Pour lancer openvpn, il suffisait donc de la commande simple suivante :
systemctl start openvpnSous Stretch, tout a été changé. Premièrement, le service a changé de nom très salement. Par salement, je veux dire que l'ancien nom existe toujours, mais a été remplacé par un service qui ne fait absolument rien (il lance le programme /bin/true, programme dont l'utilité crève les yeux), ce qui fait que ce changement de service implique non seulement une rupture de ce service si aucune action n'est prise par la suite, mais également que c'est très difficile de s'en rendre compte, le service ancien openvpn.service étant diagnostiqué par le système comme actif et bien portant. Donc, la nouvelle forme de ce service est en fait un couple de service, [email protected] et [email protected], le premier se chargeant de lancer OpenVPN en temps que client, et le second en temps que serveur. Mais ce n'était pas fini : les configurations VPN devaient être déplacées aux nouveaux endroits adéquats, et la ségrégation entre clients et serveurs a été instaurée : désormais, les configurations clients doivent aller dans /etc/openvpn/client et les configurations serveurs dans /etc/openvpn/server. Mais ce n'est encore pas tout : ces nouveaux services ne s'invoquent plus de la même manière. On doit maintenant spécifier le nom de la configuration dans la commande qui démarre le service. Par exemple, pour une configuration serveur qui s'appelle hashtagueule.conf (dûment placée dans /etc/openvpn/server), la commande pour démarrer le service associé est donc :
systemctl start openvpn-server@hashtagueulePour couronner le tout, un bug de configuration, oui un bug, et non une modification de comportement, s'est glissée dans le fichier de service [email protected]. Ce fichier comporte la ligne suivante :
LimitNPROC=10Cette directive est utile pour contrôler le nombre maximum de processus exécutés par un service, pour éviter dans certain cas l'explosion du load du serveur. Sauf qu'ici, cette valeur est beaucoup trop petite. On se retrouve alors avec l'erreur suivante consignée dans les logs :
openvpn_execve: unable to fork: Resource temporarily unavailableCe qui veut dire que le système refuse la création d'un nouveau processus pour ce service. Je me résolus donc à réparer salement et de manière non safisfaisante en changeant la valeur 10 par 100 (aucune idée si c'est carrément trop), et enfin, le service a accepté de fonctionner.
Quelle leçon tirer de cette aventure ? Premièrement, les mises à jour sont rarement simple, surtout dans le cas de Debian. Deuxièmement, même si le nouveau fonctionnement d'OpenVPN est désormais plus propre et correspond à l'usage conventionné sur les systèmes les plus récents, on peut déplorer la manière dont elle a été mise en place. Le bon usage aurait été d'instaurer une période de transition pendant laquelle les deux workflows auraient coexisté, plutôt que de casser brutalement une configuration existante et fonctionnelle. Et je ne parle même pas de la mauvaise limite du nombre de processus...
En espérant que cette histoire aura été utile à des gens, je vous souhaite une bonne mise à jour.
]]>C'est bientôt l'été, j'imagine que ça ne vous a pas échappé. Bientôt les vacances estivales pour certains, pour nous ça ne change pas grand chose, à part en terme de litre de sueur sécrétés et de kilos de glace consommés.
Des choses se passent sur le blog, certaines dont vous n'avez probablement rien à faire, mais on va les dire quand même parce que c'est quand même important pour comprendre les choses. Un peu comme quand les pubs à la télé pour yaourts nature font des jolis animations de flèches descendantes sur des corps de femmes pas tellement vêtues, ça porte à peu près aucune info exploitable pour le consommateur mais c'est joli, ça rassure et ça aide à vendre.
Nous sommes en pleine migration des services sur un nouvel hôte (encore). Je vous entends rager, railler et demander avec inquiétude : Mais pourquoi ? Pourquoi encore changer d'hôte après même pas un an ? Eh bien on s'est rendu compte (il était temps) que gérer des services isolés et virtualisés c'était bien plus chouette que de gérer des services emmêlés façon sac de nœuds. On a par le passé déjà eu le cas de comportements mystérieux de services dus à une intervention sur un service qui n'avait rien à voir. Nous avons donc opté pour un hôte un peu plus costaud, et pas mal plus cher aussi. Heureusement que j'ai un salaire à présent, et désormais Motius aide financièrement, on fait de la collocation de serveur. Du coup on a franchit le pas de la virtualisation (enfin, surtout de la conteneurisation en l’occurrence), et au moment ou je vous parle, le blog a déjà été migré (et mis à jour par la même occasion). On s'était décidé à effectuer cette migration à l'occasion de la livraison de Debian Stretch en version stable. Bon, on a pris un peu d'avance, Stretch ne sortant que la semaine prochaine le 17 juin, mais bon, pour 2 semaines pendant lesquelles le blog aura tourné en version testing, on va pas en faire tout un plat.
En ce qui me concerne, quelques évènements auxquels j'ai participé ces derniers mois :
- Du 1er au 2 avril, j'étais présent aux JDLL à Lyon, pour défendre les couleurs d'un hackerspace local que je fréquente, mais également pour découvrir des associations et rencontrer des gens très sympatiques.

Membres présents de l'association LILA lors des JDLL
- Le 21 mai, je me suis rendu à Toulouse pour rencontrer David Revoy, le créateur du webcomic Pepper & Carrot dont on vous a déjà parlé, lors d'une séance de dédicace dans une petite librairie.
Je ne pourrai malheureusement pas me rendre aux prochaines RMLL à Saint-Étienne En fait si, je me suis juste emmêlé les pinceaux au moment de regarder dans mon calendrier, j'y serai donc les 1er et 2 juillet prochains. D'autre part, je vais tout faire pour me rendre aux prochain Capitole du Libre à Toulouse les 18 et 19 novembre prochains (ça semble encore loin certes).
D'autre part, je suis en train de monter avec des amis une émission de radio locale orientée autour de l'actualité numérique et du logiciel libre. Nous avons déjà enregistré le pilote, je vous en parlerais plus en détail si la programmation de l'émission est validée par l'administration de la radio. Mais il va sans dire qu'il s'agit d'un projet très excitant.
C'est la fin de cette série d'infos inutiles. Avant de vous quitter, je tiens à vous faire connaître Erma, un webcomic que j'ai découvert récemment, et qui est mon coup de cœur artistique du moment. Vous connaissez peut-être le film d'horreur The Ring sorti en 2002, dans lequel figure Samara, un spectre féminin aux longs cheveux noirs masquant le visage, qui a notamment le pouvoir de sortir de l'écran du téléviseur (sans pour autant vous parler de yaourts vous, remarquez) à des moments contrariants et de marcher à quatre pattes au plafond. Dans ce webcomic, Samara s'est calmée, a arrêté de faire peur aux gens, s'est intégrée paisiblement parmi les humains et a même un mari, dont l'union a donné Erma, une petite fille qui tient beaucoup de sa mère, tant sur l'apparence que sur les pouvoirs surnaturels. Le décalage entre horreur et slice of life est assez comique mais mène souvent à des situations attendrissantes. Ce webcomic est tout bonnement adorable.

Erma © Copyright 2016 Brandon Santiago
Voilà, bon vote si ce n'est déjà fait, hydratez-vous bien, et soyez gentils.
]]>Au nom de l'équipe d'Hashtagueule, je tiens tout d'abord à vous adresser nos sincères félicitations (des félicitations républicaines, le terme étant très à la mode dans les médias aujourd'hui) pour votre victoire à l'élection du chef de l'État français. Nous sommes soulagés en premier lieu que la France n'ait pas cédé au désespoir qui semble s'emparer du monde entier, en donnant le pouvoir à un parti extrémiste dangereux, prompt à briser les alliances amicales entre les nations européennes et mondiales, alliances qui ont demandé tant d'efforts, de réflexions et de remises en questions, et qui sont, à mon sens, l'évolution naturelle dans le cadre de l'épopée de l'humanité vers le Bien. À titre personnel, je suis même plutôt satisfait du résultat de cette élection, qui a au moins le mérite d'ouvrir des possibilités que les précédents titulaires de la Présidence ne laissaient pas apercevoir. Sur un point de vue bassement terre-à-terre, l'élection d'un Président ayant moins de 15 ans de plus de moi me remplit d'espoir quant au minimum d'ouverture d'esprit de la société. Bon, je sais très bien qu'on ne peut pas juger quelqu'un sur son âge, pas de panique, bien que je sois une personne très faible en politique et diplomatie, je garde quand même un brin de lucidité.
J'admire également la manière dont vous ne cédez pas (au moins en apparence) au triomphalisme de bas étage et le sang-froid que vous témoignez. J'espère très sincèrement que cela va durer.
Le but de cette lettre ouverte n'est bien sûr pas uniquement de vous féliciter, sans quoi ce blog aurait plutôt un nom du style notice-me-president.fr et on aurait d'ailleurs bien du mal à éviter de rester politiquement neutre. Le but n'est pas non plus de vous ennuyer, c'est pourquoi je renonce à la langue formelle et imbitable afin de vous délivrer l'essentiel. Vous me paraissez être une personne capable de se remettre en question et d'écouter les arguments sensés. À ce titre nous aimerions que vous preniez conscience de nos espoirs et de nos craintes concernant notre domaine de prédilection qui est l'informatique.
Vous avez évoqué dans votre programme l'importance de la mise des administrations au numérique. En voilà une bonne nouvelle. Un bon moyen d'apporter de la sécurité au sein des institutions (pour peu que l'outil informatique soit correctement utilisé) et de l'emploi moderne. Et puis il y a un aspect écologique à ne pas négliger, même s'il n'est pas forcément aussi trivial qu'il n'y paraît. Mais attention, ce chemin, très bénéfique pour peu que l'on suive un minimum de précautions, peut très rapidement finir en eau de boudin dans le cas contraire.
Le bon chemin, à notre sens, est de favoriser et même d'imposer aux administrations publiques l'usage de logiciels libres. Afin que vous gardiez toute votre attention et votre ouverture d'esprit pour les raisons qui font que c'est une drôlement bonne idée, examinons de plus près les arguments avancés par les lobbyistes contre le logiciel libre.
Les mauvaises langues diront qu'on ne change pas une équipe qui gagne, et que l'administration a toujours tourné sur du logiciel privateur comme Microsoft Office, Windows, Oracle SQL, services Google, j'en passe et pas des moindres, et que ça a toujours très bien marché. Vous êtes désormais Président, vous devez donc être incollable dans le domaine de l'industrie, et vous n'ignorez donc pas le nombre de sociétés à croissance forte qui se spécialisent dans le logiciel libre. Il s'agit d'ailleurs d'un domaine dans lequel la France excelle, soit dit en passant. Ces sociétés qui ont le vent en poupe sont appelées des SS2L, sociétés de services en logiciel libre. Et croyez moi M. le Président, ça dépote grave. Vous avez donc des entreprises à la pelle, des entreprises européennes et françaises prêtes à fournir leur savoir-faire pour concevoir, déployer et maintenir des architectures libres, ainsi qu'à former le personnel pour qu'il soit autonome.
Les mauvaises langues répliqueront : oh là là, le coût de mise en place va être exorbitant. À ces personnes visiblement expertes en mauvaise foi, je ferai remarquer que les licences d'utilisation des logiciels privateurs ont elles-même un prix à tomber par terre, tout simplement parce que les sociétés qui les proposent ont le monopole sur le produit qu'elles vendent et qu'elles sont les seules aptes et autorisées à vendre du support. Le fonctionnement du logiciel libre est simple : vous avez liberté d'utiliser le logiciel gratuitement, vous avez le droit de l'entretenir et de le faire évoluer à votre convenance, et vous avez la liberté de distribuer votre version et tout le savoir-faire que vous y avez placé. Si vous avez recours à une SS2L afin de vous aider à utiliser vos logiciels libres, vous être libre à tout moment de prendre en charge la maintenance et l'infogérance du logiciel en interne ou encore de changer de SS2L. Ce mode de fonctionnement est beaucoup plus sain au niveau industriel, favorise la concurrence nécessaire à l'économie et est un gage de qualité.
Mais alors, rétorqueront les mauvaises langues, je préfère encore payer pour une société qui développe mes logiciels plutôt que de confier mon infrastructure à du travail "gratuit", car c'est bien connu, plus on y met d'argent, plus c'est efficace. Alors déjà, travailler dans le domaine du libre n'est pas du tout incompatible avec gagner de l'argent. Sinon les fameuses SS2L dont je vous parle tant n'existeraient pas. Comme je l'ai dit, ces entreprises vendent le savoir faire et non le logiciel en question. Les ingénieurs n'y inventent pas des technologies à partir de rien : ils font un énorme travail de "veille technologique" constant et rigoureux afin d'adapter leurs offres et d'en proposer de nouvelles. Et éventuellement, si la société en vient à modifier le code des logiciels libre qu'elle utilise, elle reverse les modifications à la communauté, elle y est tenu par la licence du logiciel libre. Le meilleur exemple de ce fonctionnement est la société américaine Red Hat qui vend la compilation de son propre système d'exploitation et qui reverse les modifications à la communauté, ce qui permet à n'importe qui ayant les compétences d'obtenir gratuitement le logiciel en question, pour peu qu'il puisse le maintenir lui-même. La mise à disposition des sources permet également à n'importe qui de vérifier le fonctionnement d'un logiciel et c'est grâce aux vérifications menées par la communauté qu'on peut s'assurer que le logiciel est de confiance. En comparaison, du côté des logiciels privateurs, absolument rien ne vous assure que le logiciel fait exactement ce qu'on lui demande et qu'on y a pas glissé une faille de sécurité, par incompétence ou par malice, vu qu'il n'y a qu'une seule société qui accède à la recette du logiciel.
Pour être sûr que vous me compreniez, M. le Président, je vais utiliser une analogie classique, et je vais vous demander de comparer un logiciel à un gâteau au chocolat. Cette analogie est parlante car elle tend à unifier le peuple Français, non, l'humanité entière, autour du fait que les gâteaux au chocolat c'est bougrement bon. Donc, imaginez qu'un pâtissier vende des gâteaux au chocolat. S'il ne donne pas la recette de son gâteau, il encourt plusieurs risques. D'une part, en théorie, il peut remplacer le chocolat par une matière marron beaucoup moins ragoutante et le vendre tel quel, le client n'y verra que du feu jusqu'à ce qu'il le mange, et ce sera trop tard. D'autre part, si le pâtissier fait faillite, plus personne ne sera en mesure de le remplacer, condamnant ainsi l'humanité à se passer de gâteau au chocolat, ce qui, vous en conviendrez, M. le Président, serait bien triste. Cependant, s'il partage la recette du gâteau au chocolat, certes il va devoir faire preuve d'esprit pratique pour gagner autant d'argent, car n'importe qui sera en mesure de devenir pâtissier et de se lancer dans le gâteau au chocolat. Cependant, à partir de ce moment là, le pâtissier vendra son talent et non pas un produit alimentaire, car aussi claire une recette de cuisine peut être, un gâteau au chocolat demande du talent et de l'amour : on a gagné ainsi un gage de qualité. S'il est inventif, il pourra également se distinguer sur des plus-values, par exemple proposer une jolie salle de restauration où les clients peuvent savourer leurs gâteaux au chocolat dans un décor détendu, avec des jolies plantes, et du smooth-jazz en musique de fond. Et en plus, désormais, n'importe quel pâtissier peut déployer son talent en proposant des versions altérées de la recette, disons en ajoutant de la crème de marron, ce qui est succulent à mon sens, mais peut déplaire à d'autres personnes, et on a donc une recette qu'il est très aisé d'adapter en fonction du client.
Passons désormais au reste des arguments. Adopter le libre, c'est refuser de s'enfermer dans un cercle vicieux mené par les sociétés privatrices. Par exemple, en utilisant Microsoft Office, on condamne non seulement l'utilisateur, mais également tous ses collaborateurs à utiliser Microsoft Office. En effet, le meilleur compère du logiciel privateur est le format fermé : le format des documents générés par un logiciel privateur a toutes les chances d'avoir des spécifications tenues secrètes, ce qui oblige chaque personne disposant d'un document privateur d'utiliser le logiciel privateur correspondant : c'est de l'esclavagisme numérique. À l'opposé, un format ouvert est un format dont les spécifications sont publiques : n'importe quel logiciel (en particulier un logiciel libre) sera en mesure d'implémenter la prise en charge de ce format. Les formats fermés sont donc un frein à la collaboration. Prenons un cas concret : supposons que pendant votre campagne, vous ayez mis en consultation votre programme en format Microsoft Word sur votre site internet. Surtout que votre programme, ce n'est pas la chose la plus légère informatiquement : il y a énormément d'images, de styles de texte différents, et globalement la mise en page a demandé beaucoup de travail et a utilisé beaucoup de spécificités. Il n'y a aucune chance que ce document ait pu être ouvert par autre chose que Microsoft Word. Du coup, les seules personnes à même de pouvoir lire votre programme auraient été les possesseurs de licences Microsoft, dont je ne fais pas partie. Vous conviendrez, M. le Président, que c'est un peu gênant pour se faire élire. Mais en réalité, votre programme a été exporté au format PDF, qui est un format ouvert : tout le monde disposant d'un ordinateur était en mesure de lire votre programme sans débourser un sou de plus. Vous voyez à quel point c'est important ?
Enfin, nous pensons que le logiciel libre devrait être surtout favorisé dans les systèmes éducatifs. À l'heure de la transition vers les métiers du futur, il est nécessaire de former nos enfants et étudiants à des technologies neutres et libres plutôt que de déjà les enfermer dans des technologies orientées par des entreprises qui ne sont motivées que par l'appât du gain plutôt que par le rayonnement de la connaissance et du savoir faire. Grâce au logiciel libre, les enfants peuvent être menés à s'interroger sur le fonctionnement des choses, et peuvent reprendre des mécanismes pour créer quelque chose d'encore plus grand, de totalement nouveau, et que peut-être personne n'aurait vu venir. Le logiciel libre est une source d'inspiration et d'innovation.
Ma longue tirade approche de sa fin, si vous m'avez lu jusque là, rassurez-vous, vous allez pouvoir retourner à vos occupations plus "présidentielles". Je veux simplement attirer votre attention sur la surveillance de masse qui sévit actuellement en France, dans le cadre de ce que certains ont appelés "l'état d'urgence". Nous avons bien connaissance des raisons qui motivent de tels dispositifs, et sans pour autant adhérer aux mesures effectives, nous les comprenons. Nous tenions juste à vous inciter à faire preuve d'une immense sagesse et de vous rappeler que la sécurité ne justifie pas la privation de liberté, sous peine de mettre la démocratie en danger, et nous ne vous cachons pas que nous avons conscience que la démocratie est depuis un certain temps en réel danger et nous nous faisons beaucoup de souci. Je suis sûr qu'en tant que Président du pays des libertés, vous saisissez complètement nos inquiétudes. Je ne vais pas m'étendre sur le sujet tout de suite, un seul sujet à la fois.
Sur ces paroles, nous nous permettons encore une fois de vous féliciter, et nous vous rappelons que, sur les points évoqués ici, vous avez le pouvoir de faire changer les choses et que nous comptons sur vous.
Amicalement,
Raspbeguy, pour l'équipe d'Hashtagueule.
]]>Le Raspberry Pi (et les autres ordinateurs monocartes de la même farine) est remarquable du fait de la multitude d'usages qu'on peut lui attribuer. On le vois dans tous les domaines, Domotique, informatique embarquée, serveur écologique, ordinateur de bureau low-cost, Internet des objets, montage électronique, cluster de calcul réparti, pour ne citer que ces exemples. Cet article va se concentrer sur l'aspect média-center du Raspberry Pi et plus précisément la lecture de bibliothèque musicale.
Dans un premier temps, je vais vous expliquer comment vous monter un serveur MPD de base, chose que vous pourrez en grande partie trouver en quelques clics sur n'importe quel moteur de recherche. La deuxième partie présentera une manière très amusante de contrôler votre serveur de musique via un écran LCD, un projet en python qui a occupé mes soirées depuis ce dimanche (panne d'internet, vous comprenez) et dont je suis par conséquent assez fier, parce qu'il marche d'une part, et qu'en plus vous pouvez épater la galerie lorsque vous invitez des amis à l'heure de l'apéro et que vous voulez mettre un fond sonore.
Le serveur MPD
Si vous fréquentez des milieux barbus parlant entre autres d'usage de Linux au quotidien, de lecteurs multimédia, qui lancent des guerres sanglantes ayant pour motif par exemple le meilleur environnement graphique, qu'un environnement graphique en fait c'est pourri, que Arch Linux c'est bien mieux que Gentoo, bref, de tout ce qui relève de l'UNIX porn, vous avez très certainement déjà entendu parler de MPD (Music Player Daemon). Il s'agit d'une référence dans le domaine des lecteurs de bibliothèques musicales du type client-serveur (vous avez une machine qui lis la musique, et vous pouvez vous connecter dessus avec un client pour la contrôler).
Ce qui fait la force de MPD, c'est sa légèreté (un Raspberry Pi peut l'exécuter sans trembler des genoux) ainsi que la flexibilité de sa configuration vis-à-vis des sorties audio, mais également et surtout la grande diversité des programmes clients, reflétant une communauté considérable, ce qui en fait en quelques sortes un standard de la lecture musicale sur UNIX.
Nous partirons du principe que vous disposez d'un Raspberry Pi (même la première génération convient), et que vous avez installé une distribution dessus (par exemple Raspbian). Il est également conseillé de disposer d'un DAC (Digital to Analog Converter) externe, la carte son intégrée su RPi étant médiocre pour rester poli. Le DAC, pour faire court, est l'élément qui convertit le flux numérique audio en signal électrique analogique que vous pouvez brancher sur un ampli. Par exemple, la carte son de n'importe quel PC est un DAC. Je vous conseille également d'utiliser un DAC USB et non un DAC branché sur GPIO, sachant qu'ils est appréciable de pouvoir utiliser le GPIO pour autre chose (par exemple la deuxième partie du tutoriel...). Si vous cherchez une bonne affaire mais que vous pouvez quand même y mettre un certain prix, je vous conseille le Cambridge DacMagic 100, qui est d'excellente qualité, qui fonctionne sur le RPi avec une configuration de base et que j'utilise moi-même en étant satisfait.
Niveau installation, il vous suffit d'installer MPD, présent sur la très grande majorité des distributions. Chose à noter, si vous avez des morceaux au format ALAC dans votre bibliothèque, vous devres en plus installer les plugins gstreamer adaptés. Sur Raspbian, il s'agit du paquet gstreamer1.0-plugins-bad. Puis vous êtes bon pour le décollage.
Il est important d'ajouter le support de votre bibliothèque musicale dans le fichier /etc/fstab du RPi, cela permettra bien entendu de monter votre disque dur USB ou votre volume NFS dès le démarrage de l'appareil. Dans le cas d'un partage NFS, vous pouvez par exemple écrire :
192.168.0.5:/chemin/vers/dossier/musique /data nfs rsize=8192,wsize=8192,timeo=14,intrEn remplaçant bien sûr l'IP de votre serveur NFS et le chemin du dossier musique sur ce serveur.
Ensuite vous aurez besoin de configurer MPD. Direction le fichier /etc/mpd.conf pour dans un premier temps dire au lecteur où se trouve votre musique.
music_directory "/mnt"Le fichier de configuration de MPD est assez bien documenté via le texte commenté. Ainsi vous pourrez personnaliser l'emplacement de vos futures playlists et de la base de donnée par exemple si ça vous chante.
Partie également importante de ce fichier, la configuration des sorties audio. Si vous n'utilisez pas de DAC externe, vous pouvez laisser sans toucher. Si vous avec un DAC externe supportant de bonnes fréquences d'échantillonnage et que vous avez de la musique haute qualité, il sera intéressant d'y faire figurer :
audio_output {
type "alsa"
name "My ALSA Device"
device "hw:CARD=C1,DEV=0"
mixer_type "none"
auto_channels "no"
auto_format "no"
auto_resample "no"
}Le nom de la carte correspond pour le Cambridge DacMagic 100. Pour trouver le nom de votre DAC, vous pouvez par exemple faire usage de la commande aplay -L, qui vous listera l'ensemble des périphériques audio et leurs caractéristiques.
Cette configuration impose à MPD de laisser le flux intouché (pas de traitement a posteriori) et de laisser le DAC révéler son potentiel en traitant du son à des fréquences échantillonnages élevées.
Normalement c'est tout bon, vous pouvez démarrer ou redémarre MPD et initialiser la base de donnée. Pour ça, vous allez avoir besoin d'un client, à installer sur les machines qui contrôleront le serveur. Par exemple sonata si vous voulez une interface graphique, ou l'excellent ncmpcpp si vous voulez du joli ncurses dans votre console. Astuce : il est pratique d'utiliser directement sur le RPi un client en ligle de commande minimaliste mpc, qui vous permettra rapidement de faires certaines actions, par exemple mettre la musique en pause parce que le voisin vous attend à votre porte avec une batte de baseball (mpc pause) ou bien mettre à jour la base de donnée (mpc update). Attention, la création de la base de donnée peut être très longue en fonction de la taille de votre bibliothèque. Pendant cette période, le CPU du RPi sera très solicité. Du coup vous saurez vite quand il aura fini...
L'utilisation de MPD se base sur une liste de lecture centrale, dans laquelle vous ajoutez les morceaux dans l'ordre souhaité de lecture. Pour alimenter cette liste, vous aurez besoin de piocher dans la banque de musique qui a été créée par MPD. Je reste volontairement vague à ce sujet car la présentation de ces concepts varie en fonction du client utilisé.
Il est également très amusant de contrôler son serveur via une interface web. Si vous désirez le faire, je vous conseille vivement de jeter un œil à ympd, une interface web propre et très légère, et dont il existe une version pour RPi justement.
Bon, vous l'aurez compris, toute cette première partie n'était qu'un prétexte pour vous présenter le fruit de mon temps libre, mon projet du mois.
Utiliser un écran LCD
Il y a quelques années, je cherchais un écran LCD à contrôler par le RPi. J'ai craqué pour le Display-O-Tron 3000, qui dispose d'un rétroéclairage sous stéroïdes et multicolore, d'une série de diodes lumineuses supplémentaires à contrôler et d'un joystick de contrôle. Tout est contrôlable et personnalisable, et le fabriquant a développé une bibliothèque très facile d'usage, utilisable en Python, en C/C++ et en NodeJS. J'avais eu l'idée d'en faire un panneau de contrôle MPD mais je n'avais jamais pris le temps de le coder. C'est maintenant chose faite.
Ce programme en python donc permet d'afficher les informations de la musique en cours sur MPD, avec les fonctionnalités suivantes :
- Affichage du titre, de l'artiste et de l'album
- Défilement du texte quand celui ci est trop long pour tenir sur une ligne
- Changemment de la couleur du rétroéclairage en fonction de l'état du lecteur
- Contrôle du lecteur grâce au joystick
- Killer feature : affichage en temps réel de la puissance sonore via les diodes supplémentaires.
Mieux que des paroles, voici une vidéo de démonstration
Je vous invite à allez voir mon code commenté en détail (en anglais).
Pour le mettre en application, il vous suffira d'installer la bibliothèque Python (voir le lien vers la page Github du fabricant) ainsi que la bibliothèque python-mpd2 utilisée pour contrôler MPD.
Si vous trouvez des fonctionnalités à ajouter ou des améliorations possibles, n'hésitez pas à me le faire savoir, je serais heureux de prendre toutes les remarques en considération.
]]>Fort heureusement, aujourd'hui le chiffrement des flux est devenu en quelques sortes un standard grâce à l'essor des implémentation du protocole TLS et de ses variantes. Les protocoles anciens se sont pour la plupart dotés d'une surcouche sécurisée (HTTP, IMAP, SMTP, IRC) et les protocoles naissants sont aujourd'hui regardés de travers s'ils omettent la sécurité dans leurs cahiers des charges.
Malheureusement il existe encore des protocoles/programmes irréductibles qui continuent sans répit à laisser se balader à poil des paquets sur la toile. Ne leur jetons pas tout de suite la pierre, ou du moins pas trop fort, ce choix n'est pas toujours dénué de sens comme nous le verrons par la suite.
Ici comme dans pas mal d'articles sur Hashtagueule, il y a un déclencheur personnel du besoin qui fait l'objet du tutoriel en question. On est pas des hommes politiques, nous on vous parle de choses qu'on connaît. On a l'idée de parler de certaines choses en se frottant à des problèmes et en y trouvent des solutions. Je vais donc vous parler de l'outil Bitlbee, qui agit comme une passerelle entre divers messageries comme Jabber, Twitter, MSN et Yahoo d'un côté, et IRC de l'autre côté, ce qui permet de centraliser toutes ses messageries sur un simple client IRC. Pour ce faire, il simule un serveur IRC sur lequel se connectent les client qui veulent accéder aux services agrégé. Seulement, alors que la plupart des serveurs IRC proposent une connexion sécurisée, Bitlbee n'implante pas cette couche TLS. En partie parce que le serveur est destiné à être exécuté en local (donc pas grand risque d'intercepter les communications). Mais n'empêche que ça semble bizarre et qu'à priori ça bride pas mal les utilisations.
En réalisant ça, j'étais d'abord outré, et ça a même remis en question mon utilisation du programme. Cependant, j'ai trouvé une solution, qui est par ailleurs proposée par les développeurs. J'ai découvert un outil magique qui s'appelle stunnel, qui permet de transformer n'importe quel flux en clair par un flux chiffré à travers un certificat TLS. Pour ceux qui s'y connaissent un peu en serveur web, il s'agit du même principe qu'un reverse proxy comme le ferait un nginx ou un HAproxy, mais pour n'importe quel flux TCP (même si HAproxy est capable de gérer les flux TCP mais c'est moins marrant).
Du coup, il suffit de posséder un certificat adapté au nom de domaine qui pointe vers votre serveur (chose très facile en utilisant Let's Encrypt, pour peu que vous ayez un serveur web qui sert ce nom de domaine) et il vous est possible d'envelopper ce flux dans un tunnel TLS. Voici ce que j'ai ajouté dans ma configuration stunnel :
[bitlbee]
accept = 6697
connect = 6667
cert = /etc/letsencrypt/live/mon.domaine.tld/fullchain.pem
key = /etc/letsencrypt/live/mon.domaine.tld/privkey.pemLe port 6667 est le port non sécurisé, et le port 6697 est le port sécurisé. Elle est pas belle la vie ?
De plus stunnel peut fonctionner dans l'autre sens, c'est à dire servir du contenu en clair à partir d'un canal sécurisé, ce qui est pratique quand derrière on a pas de client compatible avec TLS.
Bon, revenons sur les raisons qui poussent un programme à ne pas adopter la sécurisation des flux. Dans le cas de bitlbee, comme je l'ai dit plus tôt, c'est un serveur destiné à être atteint en local. De plus, certains projets choisissent de ne pas implémenter le chiffrement et de recommander explicitement des solutions comme stunnel pour ne pas être responsables d'une éventuelle faille dans leur implémentation. Et aussi parce que c'est gonflant de faire de la sécu quand le projet à l'origine n'a absolument pas de rapport, il faut le reconnaître.
]]>Aujourd'hui je vais vous présenter (pour ceux qui ne le connaissent pas déjà) le jeu Battle For Wesnoth. C'est un très beau jeu mono- et multijoueur en tour par tour, stratégique, et qui fait aussi appel à la chance, le tout dans un univers de type médiéval fantastique.
Battle for Wesnoth est un logiciel libre écrit en C++ et disponible sous licence GPLv2. Il s'installe très facilement sous Windows (binaires disponibles) GNU/Linux, et sous Mac aussi, quoique je n'ai pas testé. Sur ma debian (idem sur Ubuntu) je l'ai installé ainsi :
apt-get install wesnothVous avez la possibilité de jouer une campagne pour vous familiariser avec le jeu, après avoir fait le tutoriel. Comme vous le voyez ci-dessous, le jeu est facile à prendre en main, puisqu'on vous indique ce qu'il faut faire.

Dans le jeu, on se déplace sur des cases hexagonales, vous pouvez voir un hexagone jaune autour de la pièce que mon roi a recruté.
Les bases de la stratégie
Le héros/roi
Vous avez un roi qu'il ne faut pas perdre sans quoi vous perdez le jeu, et qui est le seul qui permette de recruter de nouvelles unités, seulement quand il est à certains endroits stratégiques de la carte : ici à une place particulière du château, celle entourée par des tours pointues.
L'or
Vous avez une certaine quantité d'or qu'il faut bien gérer, il s'agit de l'unique ressource du jeu. L'or diminue quand vous recrutez des combattants, et à chaque tour, proportionellement au nombre de combattants. Vous gagnez d'autant plus d'or que vous avez de villages (ceux avec un drapeau rouge au dessus).
Se déplacer
La distance de déplacement dépend du terrain pour les unités qui ne volent pas. Certaines unités vont plus vite sur l'eau, d'autres sur terre. Ici, on voit que mon roi se défend mieux dans la forêt (50%) que sur un chemin (40%).
On se déplace mal dans les cases adjacentes à des ennemis, une partie de la stratégie repose donc parfois sur la création d'un "mur" de personnages pour empêcher la prise de villages. Pour un mur, il suffit d'espacer les unités de 0 ou 1 ou 2 cases pour que l'adversaire ne puisse pas passer.
Combattre
Il y a deux types d'attaques : corps-à-corps et à distance. Ici je suis dans le tutoriel, donc je n'ai qu'une attaque : "6-3" signifie que j'attaque 3 fois en faisant 6 points de dommage. Le hasard fait que j'ai touché deux fois sur trois, et que mon adversaire a riposté trois fois sur cinq. Il a "3-5", qui signifie qu'il attaque cinq fois, en faisant trois points de dommages
Il y a des armes qui sont plus efficaces que d'autres sur un adversaire, il faut donc choisir qui attaque qui sera la plus efficace. Par défaut le jeu propose souvent l'attaque la plus utile.
Vous pouvez voir le détail des attaques avec des statistiques avancées.
Par exemple si un adversaire n'a pas d'attaque à distance, il peut être utile de l'attaquer à distance pour ne pas subir de dommages. Lorsque lui nous attaquera, on pourra riposter avec notre attaque corps-à-corps. Les attaques à distance se font aussi quand on est sur une case adjacente à notre adversaire, ce qui fait qu'il pourra aussi attaquer à son tour.
La stratégie minimale
Il y a beaucoup de modificateurs de chance qu'il faut bien utiliser (c'est une grande partie de la stratégie). Premièrement le terrain, on attaque mieux à certains endroits que d'autres. Deuxièmement le jour est divisé en deux tours ou il fait "jour", deux ou il fait "nuit", et deux périodes liminaires. Certains combattants sont avantagés le jour, d'autre la nuit, certains lors des périodes limites, enfin d'autres ne sont pas affectés.
Il faut aussi choisir ses combattants en fonction de l'adversaire si possible. Je vous l'ai déjà dit, certaines armes sont plus efficaces que d'autres.
Pour la suite, je vous conseille le tutoriel, il est très facile. Le jeu vient en anglais par défaut mais est complètement traduit en français.
Vous pourrez vous diriger vers cette page du wiki pour en apprendre plus sur la stratégie, et défaire plus facilement l'IA, qui est assez fûtée.
Une partie à plusieurs
Sur la machine d'un joueur
Retrouvons les passionnés du code et de l'adminsys en installant un serveur Wesnoth.
Sous Windows, on peut lancer le serveur Wesnoth à partir du jeu. Sous debian, wesnoth est un service.
Tout d'abord, installer le serveur wesnoth à l'aide de la commande :
apt-get install wesnoth-1.10-serverou
apt-get install wesnoth-1.12-serverLa version du serveur importe moins que celle du client, et c'est un problème que l'on verra plus tard.
Puis démarrez le service. Il tourne sur le port 15000.
service wesnoth-1.10-server status
service wesnoth-1.10-server start # si status == stop.Sur un serveur dédié
Pour pouvoir jouer avec des personnées n'étant pas sur votre sous-réseau local, il faut installer le service sur un ordinateur exposé à internet. Personnellement, j'ai installé un serveur Wesnoth sur une machine virtuelle Qemu-KVM de mon serveur. Pour la simple raison que mon serveur est sous debian 8 stable codename Jessie, et que la version de Wesnoth par défaut est la 1.10, qui est l'ancienne version stable. Sous debian testing codename Stretch, on a la version 1.12 de Wesnoth.
Je n'ai pas eu de problèmes de compatibilité client-serveur, mais j'en ai eu client-client, donc pour une partie à plusieurs, choisissez la même version (1.10 ou 1.12 au moment de publication de l'article).
Voici la configuration que j'ai utilisée (il faut rediriger le trafic IP du port 15000 depuis le serveur vers la machine virtuelle). Cette machine virtuelle a pour adresse 192.168.122.145, il faudra que vous adaptiez en fonction de votre propre configuration :
#!/bin/bash
IP_FWD_ON=`/sbin/sysctl net.ipv4.ip_forward | cut -d '=' -f2 | tr -d '[:space:]'`
if [ "${IP_FWD_ON}" = "1" ] ;
then
/sbin/iptables -t nat -I PREROUTING -p tcp -d 192.168.1.16 --dport 15000 -j DNAT --to-destination 192.168.122.145:15000
/sbin/iptables -t nat -I PREROUTING -p tcp -d 192.168.1.16 --dport 15000 -j DNAT --to-destination 192.168.122.145:15000
/sbin/iptables -I FORWARD -m state -d 192.168.122.0/24 --state NEW,RELATED,ESTABLISHED -j ACCEPT
else
echo "Err: Routage NAT désactivé."
fiCe script (à utiliser en tant que root sur la machine hôte) vérifie que l'IP forwarding est activé, et si oui route le trafic du port 15000 vers l'IP 192.168.122.145.
Le jeu est assez complet et mériterait une description plus avancée, notamment des races (Loyalistes, Rebelles, Nordiques, Morts-Vivants, Aliance knalgane, Dracans) des types d'attaques (perforantes, tranchantes, froid, chaud) , mais ça ferait un article long comme le bras, et c'est déjà assez bien documenté dans le jeu et dans le wiki, donc je vous laisse là avec largement de quoi jouer, et même de quoi mettre en place un serveur, éventuellement public. Vous pouvez aussi rejoindre des serveurs officiels.
Bonne partie !
Motius
]]>Bon, si vous ne connaissez pas Git, cette news vous est inutile, à part pour vous présenter cette outil qui a de grande chances de vous être très utile. Si vous utilisez Git, vous connaissez donc ce besoin de vérifier rapidement les dernières évolution du code, par vous-même ou par vos collaborateurs. Ils vous est possible d'en avoir une vue via la commande git log, un peu fastidieuse à utiliser si vous voulez filtrer ce que vous voulez voir.
Vous avez également une autre possibilité de le faire, de manière interactive et avec des option faciles et minimalistes pour vous aider à faire le tri. Il s'agit de la commande git recall qui s'installe sous la forme d'un simple script à installer. Vous pouvez alors préciser le nombre de jours dans lesquels vous souhaitez faire votre recherche, préciser l'auteur des commits qui vous intéressent, puis naviguer interactivement dans la liste des commits afin d'afficher des différentiels.
J'espère que cela vous sera utile.
]]>Alors la moindre des choses, c'est de le remercier. Je vous invite tous à le faire en lui envoyant un gentil courriel (parce que oui, du coup c'est grâce à lui les courriels) contenant vos éloges, vos plus beaux poèmes en son honneur ainsi qu'une rédaction portant sur votre journée parfaite en compagnie de François Fillon, minimum 500 mots.
P.S. : à quand des candidats politiques compétents ?
]]>Pour la suite de cette série d'articles sur l'épuration de votre bureau, j'avais prévu de passer à la présentation d'outils courants pour les tâches quotidiennes, mais en continuant ma propre configuration de bureau, je me suis rendu compte qu'il y avais pas mal de choses à ajouter par rapport au dernier article. En tout cas, trop de choses pour essayer de les bourrer dans un coin de marge.
J'aimerais vous parler plus en détail de py3status qui, si vous vous en rappelez, sert à améliorer la barre d'information d'i3. Ainsi, alors que cette barre par défaut propose assez peu de modules et une personnalisation minimale, la barre améliorée avec py3status propose des fonctionnalités bien plus intéressantes. Outre la plus grande flexibilité des réglages, avec cet utilitaire il est très simple d'écrire ses propres modules, et on peu prendre en compte les clics pour le comportement des modules.
Parmi tous les modules proposés, il y en a tant d'utiles que je n'avais pas la place au début dans ma barre. Heureusement que j'ai ensuite découvert qu'on avait droit à plusieurs barres dans la configuration i3. De plus, j'ai noté qu'il existe un pull request sur le dépôt de py3status qui permettrait de multiplier les configurations pour une seule barre, donc la possibilité de changer de modules à chaud.
Ma configuration i3 actuelle
Une petite description des modules affichés, de gauche à droite :
En haut :
- Informations sur le morceau en cours dans un lecteur compatible MPRIS.
- Mises à jour en attentes (la première valeurs représente le nombre de mises à jours des paquets binaires et la deuxième concerne les paquets AUR).
- Statut de mon mobile connecté via KDE Connect (peut s'utiliser sans autre composant KDE, grâce au ciel. Et oui, j'ai appelé mon mobile Philippe).
- Niveau du volume sonore, contrôlable au clic et à la molette. Grâce à ce module, je peux me passer de l'utilitaire
pa-systray. - Niveau de luminosité, contrôlable à la molette.
- État de l'extinction d'écran DKMS, contrôlable au clic.
- Sélectionneur de configuration pour écran externe, contrôlable au clic.
- Compteur d'articles non lus sur mon instance Tiny Tiny RSS.
- Compteur de mails non lus (le texte avant le nombre correspond au compte concerné).
- Date et heure.
- Icônes de notifications des programmes classiques (ici, NextCloud et nm-applet).
En bas :
- Bouton de capture d'écran avec envoi automatique sur un serveur choisi, contrôlable au clic.
- Vitesse du réseau.
- Indicateur de VPN.
- Indicateur de connexion à internet (affiche l'IP publique par défaut, masquée ici pour des raisons évidentes).
- Indicateur d'IPv6.
- Indicateur de connexion WiFi (encore ce Philippe...).
- Indicateur de connexion cablée.
- Espace libre sur le disque.
- Utilisation CPU.
- Mémoire utilisée.
- Température CPU.
- Charge CPU.
- État de la batterie.
L'écriture d'un module est vraiment simple, pour peu qu'on ait des bases de Python. Si vous le faites, je vous invite à en parler en commentaire ainsi qu'à contribuer au projet en proposant un pull request. Les mainteneurs sont sympas, et pour ceux qui débutent dans la contribution dans des projets open-source, il est très gratifiant de voir son travail en temps qu'amateur se faire valider par un projet qu'on utilise tous les jours.
Je souhaite également parler des symboles que vous pouvez voir dans mes barres d'information. Ceux qui font du frontend web reconnaîtront les glyphes du projet Font Awesome (pour le coup, rien à voir avec le gestionnaire de fenêtres Awesome). Il s'agit d'une police de caractère qui utilise une plage spéciale de la table unicode afin de mettre à disposition des symboles qu'il est pratique d'utiliser principalement pour des pages web, mais également, comme vous pouvez le voir, sur des interfaces un peu plus personnelles. Lorsque i3 tombe sur un caractère unicode que la police qu'il utilise ne peut pas afficher, il va alors utiliser la police Font Awesome en tant que police de substitution. Afin mettre ce procédé en œuvre, il est nécessaire d'installer la fonte (le paquet AUR otf-font-awesome sous Arch Linux) et de vérifier que le fichier de configuration d'i3 contienne la ligne suivante :
font pango:monospace 8Vous pouvez remplacer monospace par la fonte que vous préférez. Vous serez ensuite libres de choisir une icône Awesome en le précisant dans la configuration des modules py3status (le plus souvent, il faut se tourner vers la variable format).
J'avais oublié d'expliquer dans mon précédent article, lorsque j'ai parlé de touches de volume et de luminosité sur le clavier, comment utiliser les touches de contrôle des lecteurs de musique. C'était pourtant sur ma liste des choses importantes à dire, j'en suis confus. Laissez moi réparer ça.
Pour utiliser ces touches, comme pour les touches volume et luminosité, il vous faudra spécifier dans votre configuration i3 que vous souhaitez mapper ces touches médias à un appel de commande. Simplement, le problème est que par défaut, il n'existe pas de commande simple pour contrôler un lecteur MPRIS. Nous avons donc besoin d'installer playerctl, un petit programme en ligne de commande qui va se charger de fournir des commandes lisibles et succinctes. Ensuite, il nous faudra ajouter dans le fichier de configuration i3 les lignes suivantes :
bindsym XF86AudioPlay exec playerctl play-pause
bindsym XF86AudioPrev exec playerctl previous
bindsym XF86AudioNext exec playerctl nextNotez que si le lecteur que vous utilisez n'est pas compatible MPRIS, il vous faudra trouver une autre astuce. Notamment si vous utilisez cmus en version release et non en version git, vous aurez besoin de faire appel à la commande cmus-remote.
Enfin, pour terminer cet addendum, je vous parlerai du choix de la console. Entre la publication du dernier article et la rédaction de l'article que vous êtes en train de lire, j'ai fait le test d'une autre console qui s'appelle Termite. C'est une bonne console qui donne la même sensation qu'Urxvt, mais infiniment plus simple à configurer. Ça s'explique par le format du fichier de configuration : Termite se configure avec une syntaxe INI tandis qu'Urxvt se configure via un fichier Xresourses, qui suit une syntaxe vieillotte, pour ne pas dire franchement obsolète. De plus, Termite n'as pas besoin de patchs ésotériques quand on a besoin de fonctionnalités un peu spéciales, comme la prise en compte de la molette dans certains programmes pseudo-graphiques. Au fond, Urxvt n'est déjà rien d'autre qu'un patch du Rxvt original pour gérer les caractères unicodes...
Cependant, il paraît que Urxvt possède plus de fonctionnalités que Termite. Une vieille légende prétends même que Urxvt supporterait plusieurs polices de caractères à la fois, bien que jamais je n'aie réussi à faire fonctionner ce mécanisme que, j'imagine, seuls les âmes les plus téméraires et les plus courageuses peuvent activer.
De plus, et c'est ce qui m'a définitivement décidé à rester sur Urxvt, Termite nécessite un compositeur graphique (par exemple xcompmgr) pour gérer la transparence. Rien de très gênant là-dedans, les compositeurs graphiques minimalistes sont très légers, et il m'en coûte très peu d'ajouter une ligne pour en lancer un dans ma configuration i3. Mais malheureusement, i3 a un petit bug lorsqu'on utilise un compositeur graphique avec certaines positions de fenêtre : quelquefois, le fond d'un terminal sera non pas le fond d'écran comme on pourrait s'y attendre, mais le contenu du terminal qu'y s'y trouvait précédemment, ce qui n'empêche pas de travailler mais qui est assez gênant.
Urxvt, quant à lui, n'a pas besoin de compositeur graphique pour la transparence, car il utilise une "fausse transparence" : pour faire simple, au lieu de demander au serveur X ce qui se trouve derrière lui, il va directement remonter au niveau de l'image de fond et mettre en transparence la portion du fond d'écran qu'il cache. Bon, pour le coup il est impossible, si on a une console Urxvt flottante, de voir une autre fenêtre par transparence, mais personnellement je m'en rappe les marrons, sachant que j'utilise extrêmement rarement les fenêtres flottantes, et absolument jamais pour des consoles. Sinon, à quoi bon utiliser i3 ?
En espérant que ces commentaires vous seront utiles, je vous souhaite un joyeux Noël, et peut être une bonne année. Tchin tchin.
]]>Allez, on va dire que vous n'avez pas remarqué les quelques semaines mois de silence de notre part, je pourrais encore me ressortir des excuses moisies, mais je l'ai déjà fait dans quelques articles précédents. J'espère donc que vous ne m'en voudrez pas si je m'épargne cette peine.
Beaucoup de choses se sont passées dans l'actualité. Entre l’avènement du porte moumoute américain et le décret du vilain Cazeneuve sur le fichage de l'ensemble des français, les occasions de faire couler de l'encre n'ont pas manqué. Mais bon, je ne vais pas vous en parler ici. Pas encore, du moins.
Je vais plutôt vous parler de mon éternelle quête de l'environnement de bureau parfait. Vous savez, j'ai eu ma période GNOME, et elle a duré longtemps en plus. Ah, la jeunesse...
J'ai également entre temps acquis un nouveau laptop, un Dell Inspiron 15" 7548, qui a la particularité de planter au démarrage une fois sur deux d'avoir un écran HiDPI, donc des pixels deux fois plus petits que les écrans traditionnels (on peut trouver également le terme Retina). Et là, Sainte Mère de Dieu, j'ai appris un truc. Les écrans HiDPI et Linux, c'est coton. Dans beaucoup de cas, vous aurez besoin de vos lunettes de soudeur à nanotubes pour y voir clair. Tous les programmes GTK2 par exemple sont incompatibles avec la définition de votre écran. Ce qui choque aussi, c'est le manque de cohésion et la multitudes de réglages pour obtenir un truc correct : entre le scale factor de GTK3, celui de QT5, la taille des polices, la définition donnée à xrandr --dpi, ceux donnés au serveur X... vous allez très facilement manquer d'air et perdre les pédales.
Pour le coup, j'étais tombé sur la conclusion suivante : les seuls environnements de bureau possibles pour un écran HiDPI sont ceux basés sur GTK3, en l’occurrence GNOME et Cinnamon (je n'ai pas testé KDE, ma tolérance à la douleur a quand même ses limites). Comme j'ai fini par avoir horreur de GNOME avec sa terrible lourdeur et ses réglages atroces, j'ai tourné pendant des mois sur Cinnamon, qui est un fork de GNOME d'il y a quelques années maintenant, permettant de couper court à la plus grande partie de ses défaut.
Face à mon manque de solutions pour utiliser mon écran sans m'esquinter les yeux, j'ai fini par me dire : au diable les environnement de bureau. Au diable GTK et son manque diabolique de rétro-compatibilité, tout ça c'est pour les faibles.
Je me suis souvenu d'i3, un gestionnaire de fenêtre (et non un environnement de bureau) que j'avais décidé d'utiliser sur mon lieu de travail (et sur des écrans traditionnels pour le coup). On a beau dire ce qu'on veut, mais ce genre d'outil est très efficace : ça élimine le superflu et la fluidifie le travail. C'est pensé pour être totalement contrôlable au clavier, même si l'usage de la souris est possible.
La différence entre un environnement de bureau et un gestionnaire de fenêtre est d'ordre fonctionnel. En fait, un environnement de bureau inclut généralement un gestionnaire de fenêtre, ainsi que tout un tas de fonctionnalités, comme un navigateur de fichiers, un centre de configuration, divers menus pour changer rapidement les réglages courants (net, volume...), le montage automatique de volumes externes, et tout un tas de joyeusetés. Le gestionnaire de fenêtre se concentre sur la position de vos fenêtre. i3 s'arrange pour les redimensionner automatiquement en fonction de leur nombre et de l'importance que vous leur accordez. Pour les autres fonctionnalités, vous devez aller chercher ailleurs. Fort heureusement, ces outils existent et fonctionnent en synergie et sont en général suggérés par les mainteneurs de tels gestionnaires de fenêtre. Nous en parlerons dans cet article, pas d'inquiétude.
Sachez aussi que, de la même manière qu'il existe des conflits entre les utilisateurs de Vim et d'Emacs, ainsi que le conflit screen/tmux (je vous ai indiqué en gras ma position) qui font toujours rage sur les forums, les mailing-lists et les canaux IRC, et ce depuis décennies, il existe également un débat entre i3 et Awesome, un gestionnaire de fenêtre du même genre que j'ai également eu l'occasion de tester. Pour ne froisser personne, disons que chacun a ses bon côtés et ses défauts, même si au bout du compte, ça revient plus ou moins au même principe. Je tiens cependant à souligner la facilité de configuration et le minimalisme rafraîchissant d'i3 par rapport à Awesome.
Bon, ça fait 5 minutes que je vous parle de bureau élégant, mais toujours pas une seule image. Le mieux c'est que je vous montre maintenant.
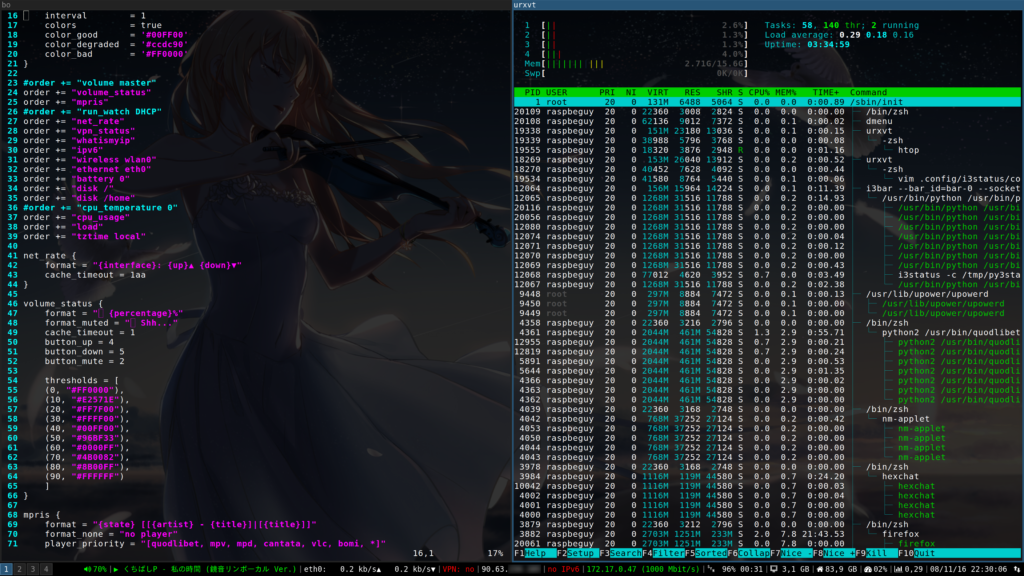
Mon bureau sous i3 sur écran HiDPI, avec vim à gauche et htop à droite
Sur cette exemple, je n'ai que deux fenêtres ouvertes, mais sachez que je peux en ouvrir bien plus, et je peux également scinder les espaces verticalement et horizontalement à la fois. Pour ceux qui s'affolent en voyant que je n'ai que des terminaux ouverts et qui voudraient continuer à utiliser leurs programmes GTK, sachez que rien ne les en empêche, c'est juste que je fais en ce moment une petite indigestion des programme à interface graphique, et je les évite le plus possible, ma tension s'en porte mieux et mes proches en souffrent moins.
Remarquer la barre du bas qui présente plein d'informations variées, comme mon espace disque, mes différentes IP (locales et publiques), mon état de batterie, la vitesse de mon réseau, et même le morceau en cours dans mon lecteur de musique. C'est encore un point qui me fait craquer pour i3, c'est à dire la simplicité pour configurer cette barre. Il est remarquable qu'i3 laisse à l'utilisateur le choix du programme à afficher dans cette barre, bien qu'il en propose un par défaut (i3status). Pour ma part, j'utilise py3status, un simple wrapper d'i3status, qui ajoute des possibilités de widgets et en réimplémente certains.
Bon, vous avez décidé d'adopter i3 ? C'est très bien, il s'agit du pas le plus dur à franchir. Une fois qu'on a la volonté, le reste suit sans trop tarder. Sur Archlinux, vous avez donc installé le groupe i3 qui vous fournit le gestionnaire de fenêtre i3, l'utilitaire i3status et le verrouilleur d'écran i3lock. Vous avez jeté un coup d’œil au fichier de configuration qui se trouve à l'emplacement ~/.config/i3/config. Vous remarquerez que la plupart des opérations que vous pouvez effectuer à travers i3 se font grâce à la touche définie dans la variable $mod. Par défaut, il s'agit de la touche logo (la fameuse touche "ouindoze"), mais vous pouvez changer ça. En fait, vous pouvez motifier l'intégralité des raccourcis claviers, et en ajouter à votre convenance, vous pouvez vous faire plaisir. Vous n'êtes pas obligé de tout comprendre dès le début, il s'agit uniquement de se faire une idée des fonctions de base et de voir comment vous pourrez y apporter votre touche personnelle.
Maintenant, comme j'en ai parlé plus tôt, il vous faut quelques utilitaires qui vont vous simplifier la vie pour effectuer les tâches les plus simples.
Un émulateur de console adapté
Bon, en vrai, un linux sans console, c'est comme une waifu sans rondeurs une Ferrari sans levier de vitesse, c'est du gâchis de potentiel et ça envoie pas du rêve. D'autre part, on a décidé de se passer le plus possible d'applications GTK/QT/portnawak, donc je ne vous conseille pas d'utiliser gnome-terminal, qui va alourdir inutilement votre interface. À la place, je vous conseille rxvt-unicode, parfois aussi appelé urvxt. Il s'agit d'un terminal puissant, avec une énorme personnalisation. Un autre choix aurait été xterm, qui dispose d'une grande compatibilité avec d'anciens systèmes le plus souvent désuets, qui commence à vieillir et dont même les développeurs ont désormais du mal à maîtriser. J'en veux pour preuve un extrait du fichier README accompagnant le dépôt d'xterm :
Abandon All Hope, Ye Who Enter Here
This is undoubtedly the most ugly program in the distribution. It was one of the first "serious" programs ported, and still has a lot of historical baggage. Ideally, there would be a general tty widget and then vt102 and tek4014 subwidgets so that they could be used in other programs. We are trying to clean things up as we go, but there is still a lot of work to do.
Ça se passe de commentaires.
Une fenêtre de terminal se lance par la combinaison $mod+enter. i3 est assez intelligent pour savoir que vous avez installé urxvt ou xterm, et il n'a pas besoin de configuration pour lancer l'un de ces programmes lorsque invoquez cette configuration. Néanmoins, si vous choisissez d'utiliser un autre terminal par défaut, il vous faudra le préciser dans ~/.config/i3/config à l'aide de la directive i3-sensible-terminal.
De même qu'i3, urxvt a besoin de sa configuration si vous voulez le modifier un tantinet (et vous allez sûrement le faire, car urxvt a une interface atroce par défaut). Ça se passe dans ~/.Xresources. Il s'agit d'un fichier utilisé par le serveur X, donc prudence, il est possible que vous y trouviez la configuration d'autres programmes. Je vous joins mes propres réglages, à vous de les modifier à votre convenance.
! Fonts {{{
Xft.antialias: true
Xft.hinting: true
Xft.rgba: rgb
Xft.hintstyle: hintfull
Xft.dpi: 220
! }}}
! General
urxvt\*termName: rxvt-256color
urxvt\*loginShell: true
urxvt\*scrollBar: false
urxvt\*secondaryScroll: true
urxvt\*saveLines: 65535
urxvt\*cursorBlink: true
urxvt\*urgentOnBell: true
!urxvt\*override-redirect:false
!urxvt\*borderLess: false
!urxvt\*internalBorder: 0
!urxvt\*externalBorder: 0
! Extensions
urxvt\*perl-lib: /usr/lib/urxvt/perl/
urxvt\*perl-ext-common: default,matcher
urxvt\*urlLauncher: /usr/bin/xdg-open
urxvt\*matcher.button: 1
URxvt.keysym.C-f: perl:url-picker
! - catch ugly URLs
urxvt.cutchars: \`()\*<>\[\]{|}
! Appearance
! - use a bitmap font
!urxvt\*font: -xos4-terminus-medium-\*-\*-\*-12-\*-\*-\*-\*-\*-\*-\*
!urxvt\*boldFont: -xos4-terminus-bold-\*-\*-\*-12-\*-\*-\*-\*-\*-\*-\*
! - use xft for drawing fonts
URxvt.font:xft:Monospace:size=10
!urxvt.letterSpace: -10
! - cursor
urxvt\*cursorColor: #FFFFFF
! - pseudo transparency
!urxvt\*shading: 50
!urxvt\*transparent:true
!
! - color scheme
urxvt.background: #000000
urxvt.foreground: #FFFFFF
URxvt.transparent: true
URxvt.shading: 30
! black + red
!urxvt\*color0: #3f3f3f
!urxvt\*color0: #000000
!urxvt\*color1: #e01010
! green + yellow
!urxvt\*color2: #00AA00
!urxvt\*color3: #FFFF00
! blue + purple
urxvt\*color4: #112037
!urxvt\*color5: #A020F0
! cyan + white
!urxvt\*color6: #5B5BC7
!urxvt\*color7: #fefefe
! bright-black + bright-red
!urxvt\*color8: #6a6a6a
!urxvt\*color9: #FF5555
! bright-green + bright-yellow
!urxvt\*color10: #90EE90
!urxvt\*color11: #ffff2f
! bright-blue + bright-purple
urxvt\*color12: #5B5BC7
!urxvt\*color13: #e628ba
! bright-cyan + bright-white
!urxvt\*color14: #7D7DFB
!urxvt\*color15: #ffffffDes volumes qui se montent tout seul
J'aime bien pouvoir brancher ma clef USB et qu'elle se monte toute seule dans mon système avec les droits qui vont bien, et ne pas avoir à taper ce genre de commande :
sudo mount /dev/sdX /home/raspbeguy/mntEt en plus, avec cette commande, vous n'avez même pas le droit d'écriture sur votre clef en simple utilisateur, c'était vraiment casse-pied, pour rester poli.
Heureusement, vous pouver installer udisk qui va le faire pour vous, puis udiskie, un wrapper qui va utiliser udisk plus simplement. Pour lancer udiskie automatiquement au démarrage d'i3, écrivez juste dans la configuration d'i3 :
exec udiskie -ans &et le tour est joué. Vous aurez vos volumes tout beaux qui se monteront comme des grands, des notifications à chaque branchement/débranchement de volume, et un menu dans la barre du bas permettant de démonter les volumes.
Le réseau à portée de clic
Il est pratique d'avoir un petit menu permettant d'avoir la main sur les interfaces réseau. Pour cela, on aura déjà besoin de network-manager, un démon système installé avec la plupart des environnements de bureau (je ne suis pas un grand fan, mais j'ai pas trouvé mieux pour le moment, sachant qu'il n'existe pas vraiment de menu simple pour netctl) et d'un programme appelé nm-applet permettant de disposer d'un tel menu.
Le contrôle du volume
Pour la gestion du volume sur votre machine, je vous conseille d'utiliser pulseaudio à la place d'alsa tout seul. Ça va en faire grincer des dents pour certains, mais bon, faut reconnaître que c'est quand même pratique pour changer rapidement de carte son par exemple. Pour avoir un menu dans la barre, on utilisera le paquet pasystray. Attention pour les utilisateurs d'Archlinux, au moment ou j'écris, le paquet AUR de nm-applet est mal foutu, il essaye d'installer deux version concurrentes de ce programme, et va par conséquent se bananer, vous aurez besoin de faire une installation manuelle.
Sinon, beaucoup de claviers ont des touches média, avec contrôle du volume et d'intensité lumineuse. Il est possible d'utiliser ces touches avec i3 moyennant les bonnes lignes de configuration i3. Je vous donne cet extrait de configuration :
# media keys
bindsym XF86AudioRaiseVolume exec pactl set-sink-volume 1 +5%
bindsym XF86AudioLowerVolume exec pactl set-sink-volume 1 -5%
bindsym XF86AudioMute exec pactl set-sink-mute 1 toggle
# backlight
bindsym XF86MonBrightnessUp exec xbacklight -inc 5
bindsym XF86MonBrightnessDown exec xbacklight -dec 5Notez que vous aurez peut-être à changer le "1" en "0" sur les lignes de volume, cela dépendra de votre configuration matérielle.
Le fond d'écran
Certains diront que c'est un réglage pas très important, mais j'estime que c'est quand même bien agréable. Personnellement, j'utilise le fond d'écran que j'ai configuré dans lightdm, ce qui m'évite de recourir à un autre utilitaire ou configuration. Si vous voulez utilisez un fond d'écran différent, vous pouvez utiliser nitrogen, qui dispose d'une interface GTK (yeurk...) pour choisir votre fond d'écran. Si vous optez pour cette solution, vous devrez ajouter cette ligne à votre configuration i3.
exec nitrogen --restoreJ'ai donc expliqué les bases pour utiliser i3 confortablement. Dans des articles à venir, je présenterai des solutions pour se passer de programmes graphiques pour la plupart des tâches courantes.
]]>Vous avez passé de bonnes vacances ? J'espère pour vous que vous avez un peu pris l'air et que vous êtes fin prêt à commencer une nouvelle année de travail du bon pied (quand j'y pense, c'est le genre de phrase que l'on peut sortir au moins deux fois par an, en janvier et en septembre).
En ce qui me concerne, et bien j'ai continué à travailler pendant l'été (stage, m'voyez), et je sais que c'est aussi le cas de motius, qui vous a publié récemment un article au sujet de l'une de ses missions. Finalement, depuis hier j'ai finalement pu clore ce chapitre et prendre de vraies vacances... pendant environ 5 jours. Mais attention, quand je parle de vraies vacances, j'entends une période de grâce pendant laquelle on attend absolument rien de moi et où je n'ai rien d'autre à faire que ce qu'il me plaît. Et ça, même pour 5 jours, c'est vraiment le pied, croyez-moi. Même si ça se passe dans la maison familiale, ce qui est une très bonne chose en soi, sauf que le débit y est plus que pourri, enfin, il s'agit d'un moindre mal.
Sinon, en parallèle, j'ai pris des weekends, je suis allé à quelques conventions, notamment ma première Japan Expo en juillet avec des amis, expérience qu'il faudra absolument renouveler.
Je me suis également bricolé un serveur pour chez moi. Enfin, ici, bricoler, ça veut dire prendre une tour de bureau d'occase que j'ai acheté à un ami pour une bouchée de pain (moins cher qu'un Raspberry Pi, c'est dire) ainsi que 16 Go de RAM et 3 disques de 3 To pour un RAID 5 (ça c'était un peu plus cher). L'habitude et la voix de la raison me poussaient à y installer Debian, histoire d'avoir une base sage et rock-solid, mais un excès de zèle et de goût du risque m'a finalement décidé d'y mettre Arch Linux, ma petite distribution chérie, ce qui m'a fait gagner, contre toute attente, beaucoup de confiance en moi et d'adrénaline (et bien sûr tout un tas de paquets à jour). Je me suis également décidé à prendre le taureau par les cornes, tant qu'à faire, et je me suis lancé dans la virtualisation, une technique qui m'a longtemps effrayé jusqu'à présent et que je tentais d'ignorer avec toute la force de mon esprit bare-metal. Enfin bon, ce sera décrit dans un article à venir. Je songe ainsi à migrer une grande partie de mes services personnels sur cet hôte, comme les mails, les proxy IRC, enfn ce genre de chose. Et pourquoi pas migrer Hashtagueule ? Quand on y réfléchit, ce serveur tel que je l'ai amélioré est meilleur que celui que je loue actuellement, tout ce qui me manque, c'est du bon débit...
Suite à du ménage dans un des datacentres du boulot, j'ai hérité d'un vieux Soekris net5501, un ordinateur monocarte avec plein de RJ-45. Le bidule était utilisé en production et pas mis à jour depuis un bon bout de temps. Va donc falloir que je m'en occupe (avec une console série, sinon c'est pas marrant) et décider de ce que je vais en faire, probablement une passerelle, duh, ça me permettra de manipuler de l'OpenBSD et ça me rappellera le bon vieux temps.
Nous sommes de retour, nous sommes détendus, reposés, nous avons le moral bon, la volonté d'acier et le pelage soyeux. Bon retour chez les Gentils.
]]>Un petit bilan est de bon ton en de telles occasions, je ne sais guère, c'est une première pour moi. Une année de rodage et d'échauffement je dirais. Motius et moi avons pas mal progressé, à la fois sur l'écriture, les connaissances et la technique. On a défini un flux de travail et on a aujourd'hui une machinerie qui marche à peu près.
Nous avons également connu des difficultés, des prises de bec, ainsi que certains espoirs mis entre parenthèses, notamment concernant la constitution de l'équipe et l'ergonomie du site.
Je pense parler au nom de l'équipe entière (bon, ça fait deux personnes) en disant que nous sommes fiers du travail accompli ainsi que du résultat et que bien sûr, nous ne regrettons rien. Bien sûr, nous sommes conscients que si nous devions tout recommencer à zéro, certaines choses auraient été faites différemment, mais dans l'ensemble, on s'en sort plutôt pas mal.
Une petite communauté d'habitués commence à se constituer, même si elle se voit beaucoup plus sur le canal IRC que dans les commentaires par exemples. Je suis satisfait de voir que nous pouvons venir en aide à certains, et même que les gens s'entraident tout seuls. Nous nous sommes nous-même enrichis de la richesse des rencontres que nous y faisons, et c'est exactement ce que nous recherchons à travers ce projet.
À présent, que voulons-nous pouvoir annoncer dans le bilan de l'année prochaine ? Nous avons quelques projets en magasin.
Premièrement, nous allons bien sûr continuer d'écrire. Nous aimerions également enrichir notre équipe de rédaction, afin de diversifier les sources et les domaines, ainsi que d'apporter un flot plus dense et plus continu d'informations. Nous avons décidé de nous ouvrir plus quant au recrutement de cette équipe, qui était jusqu'à présent basé sur les relations personnelles (traduire par IRL). Donc si vous êtes tentés de donner un peu de votre temps en vous engageant en tant que Gentil du Net, n'hésitez pas à nous contacter, le moyen le plus rapide et efficace de le faire est de passer, comme d'habitude, par IRC (je crois que je vais finir par gaver tout le monde à force de parler de ça).
Nous avons aussi le projet de créer une partie dédiée au news rapides / partage de news, qui serait à la fois utile à l'équipe pour partager des articles représentant des news pour lesquels nous n'avons pas forcément le temps de développer une vraie valeur ajoutée, mais aussi à la communauté entière, c'est à dire que n'importe qui serait en mesure de proposer du contenu dans cette rubrique (avec instauration d'une modération, bien entendu). Il faut que je compare encore les solutions existantes ou encore que je trouve quelqu'un pour nous développer ça, pourquoi pas, soyons fou. Il faut également prendre l'avis de la communauté en considération, alors dites nous votre avis.
En résumé, comme toujours, nous avons toujours besoin de vous, chère communauté. Nous avons envie que vous nous donniez des suggestions, que vous puissiez vous impliquer dans la vie du blog, que vous parliez de nous si le concept vous plaît, en bref que vous vous sentiez chez vous et que vous nous considériez comme des amis.
Nous sommes fiers de ce que nous faisons, notre credo n'a pas changé, même si la situation politique et sociale globale est quelque peu tendue. Ne nous arrêtons pas, gardons la tête haute et les idées claires, et plus que jamais, soyons gentils.
P.S. : J'ai été tenté de mettre une image du gâteau de Portal en couverture, mais je me suis rappelé que c'était devenu trop cliché, et que de toute façon on ne met jamais de couverture aux éditos. Tant pis.
]]>Aujourd'hui on va parler boulot, mais n'ayez pas peur, on parle du mien. Petite balade réseau et dev.
Ce que j'aime le plus avec mon stage courant, c'est les défis. J'ai 6 semaines pour réaliser un prototype et sa documentation, et je peux vous dire que c'est serré. À près de trois quarts du projet, faisons un point sur son avancement, ce qu'il reste à faire, les technos, etc.
Le cahier des charges
Le monitoring réseau c'est tout sauf un sujet original. Hyper intéressant, sa mise en pratique évolue au fur et à mesure que les outils, les pratiques, et les protocoles évoluent.
Vous vous demandez sûrement pourquoi je parle de développement dans ce cas. Il y a certes de nombreux programmes permettant de faire pas mal de choses. Voici pourquoi.
- La meilleure raison : je n'ai pas accès (question de contrat avec l'opérateur réseau) aux routeurs, et il faudrait que j'aie la main sur une centaine de routeurs ;
- la deuxième meilleure raison : on m'a demandé une tâche spécifique (du reporting quotidien, entre autres). Je ne dis pas que ce n'est pas possible avec un Nagios-Cacti ou un Munin, mais je n'aurais pas commencé ce qu'on m'a demandé (voir ce qui suit) dans le temps imparti ;
- une raison pratique : on ne change pas la configuration d'une centaine de routeurs à travers le monde en 40 jours. C'est à peine suffisant pour traverser un désert.
Que veut-on savoir ? La question initiale est "quand est-ce que ma ligne est saturée" ce qui est déjà visible sur les logs du FAI (Nagios-Cacti, exporté en petites images JPG) mais n'est pas suffisant pour plusieurs raisons :
- on n'a pas de système d'alerte (facile à mettre en œuvre) ;
- on n'a pas de données exploitables plus avant (l'image JPG, c'est pas beaucoup) ;
On veut donc savoir quand est-ce que la ligne est saturée. C'est-à-dire, a priori, quand est-ce que la ligne atteint sont débit maximal.
Le but suivant est de déterminer si une saturation est gênante. Cela comprend plusieurs facteurs :
- l'heure : une saturation entre 2h et 4h du mat' parce qu'on fait des backup, ça ne gêne personne (ça pourrait, mais pas dans ce cas) ;
- une saturation d'une seconde dans la journée n'est pas grave. De même, 250 saturations quasi-instantanées, réparties de 8h à 20h ne gênent pas le travail ;
Une fois qu'on a déterminé si une saturation est gênante, on veut savoir qui elle gêne et pourquoi, afin de voir si on peut faire quelque chose pour améliorer l'utilisation des ressources.
- Par exemple, lorsqu'un site est saturé, cela gêne-t-il 1 ou 50 personnes ? Dans le premier cas, la personne est peut-être trop gourmande en ressources, dans le second, le lien est peut-être mal dimensionné.
- Certains processus peuvent être automatisés la nuit, certaines pratiques changées : backup du travail pendant la pause de midi et la nuit, passer de FTP à rsync pour les backup, ou au moins un système incrémental plutôt que full
Implémentation
Comme je sens que vous êtes des warriors,

Un warrior, probablement.
je vous propose de rentrer dans le vif du sujet avec les détails techniques.
Unzip
Je pars avec une archive zip, gentiment déposée par mon FAI, dans laquelle il y a des logs au format nfcapd, défini par Cisco.
Nfdump
Nfcapd est un fichier binaire, pas très comestible pour l'œil humain. J'ai donc trouvé nfdump, un programme qui permet de transformer les logs binaires en texte ASCII. ça ressemble à peu près à ça :
2016-09-21 21:47:42.360 0.000 TCP 192.168.5.3:445 -> 192.168.5.249:56011 1 52 1csvify
C'est mieux, mais c'est toujours pas optimal. Il y a notamment trois problèmes :
- la taille du fichier ASCII par rapport au binaire nfcapd est importante, environ 9.5 fois plus ;
- le texte ASCII est très irrégulier, le nombre d'espaces est très variable ;
- sont inutiles :
- la flèche ;
- le protocole aussi dans la majorité des cas (si on fait des calculs de poids en octets) ;
- les ports, sauf éventuellement dans le cas d'un téléchargement, le port source pour déterminer le type de trafic (HTTP : 80, POP/IMAP, IRC : 6667/6697...) ;
- le "1" à la toute fin, qui désigne le nombre de flow, toujours à 1 dans mon cas, vu les options passées à nfdump.
J'ai donc créé un préparser en C (il s'agit en fait d'une spécification flex, puis flex génère le code C correspondant, à l'aide d'automates) (il y en a deux, l'un d'entre eux affiche des couleurs, utile pour visualiser, interdit pour l'utilisation en production, parce qu'il génère bien trop de caractères d'échappement).
En moyenne, mon préparser sort un fichier au format CSV qui fait 70% de la taille du fichier d'entrée, et est beaucoup plus normalisé. Il ne supprime cependant pas beaucoup d'informations (la flèche seulement).
Parse/Somme et plus si affinités
Maintenant qu'on s'est facilité la tâche, il ne reste plus qu'à analyser le tout.
C'est le but du programme C++ suivant, qui va itérer sur les entrées du CSV qu'on a produit, et ranger les paquets aux bons endroits.
Enfin, en théorie. Parce qu'on se retrouve devant quelques petits problèmes :
- Il y a des paquets qui on une durée de passage au travers du réseau nulle, et pour faire des graphs, c'est pas top. Il faut donc gérer cela.
- Même si le C/C++ est rapide, la partie lecture du fichier sur disque est très rapide, la partie traitement est lente, la partie écriture des résultats sur disque est rapide.
- On adopte donc l'architecture suivante pour le programme C++ :
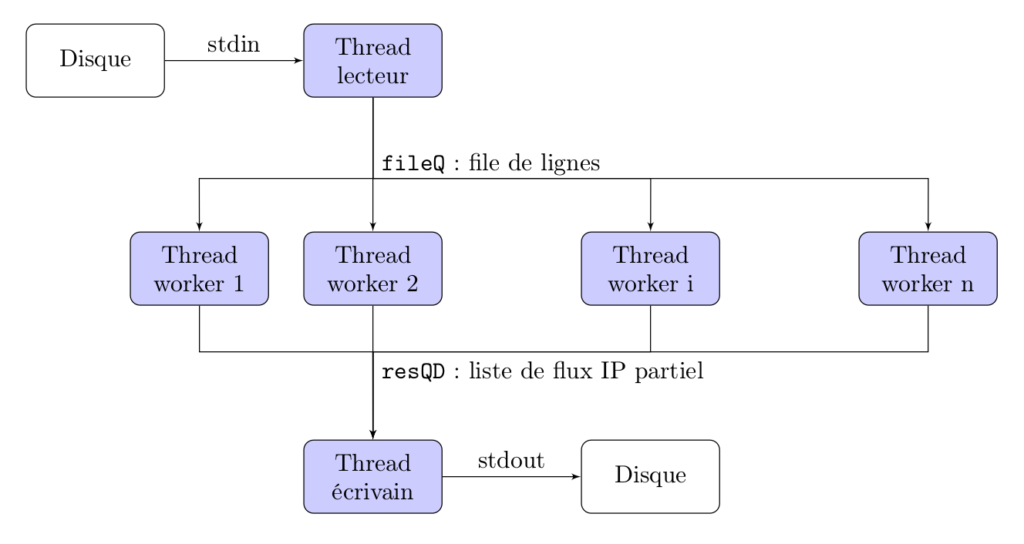
Architecture du programme C++
Le thread lecteur en haut lit depuis le disque à gauche, range les éléments dans la std::queue fileQ protégée par un mutex (fileQmutex, je suis d'une originalité à toute épreuve), tandis que les n threads workers vont travailler à générer la donnée, puis vont passer leur résultat à la liste de résultats resQD. Finalement le thread écrivain va réunir la liste de résultats, et l'écrire sur disque (à droite).
Comme vous le voyez, beaucoup de choses ont été faites, beaucoup de choix, et j'en passe de très nombreux (j'en mettrai en PS), et il reste beaucoup à accomplir, notamment :
- la doc : pour la contiuation du projet ;
- le manuel d'uilisation pour l'exploitation ;
- un How-to pour installer/améliorer le bidule ;
- utiliser la classe
Traffic()du programme C++ pour effectivement ranger les paquets dans des types deTraffic(par port pour le protocole, par IP source pour les utilisateurs les plus gourmands, par IP destination pour les serveurs les plus consultés/les plus consommateurs de ressource, et pour déterminer combien d'utilisateurs sont effectivement gênés lors d'une saturation).
Des graphs. For free.
Une fois que l'on a écrit le CSV, il ne reste qu'à faire le graph. le programme gnuplot peut faire ça très bien.
Un chef d'orchestre
Tout cela est opéré depuis un script bash.
Voilà, j'espère que ça vous a plu, si ça vous amuse, le projet est libre, disponible ici. Comme d'habitude n'hésitez pas à commenter et à bientôt !
Motius
PS : j'ai appris plein de choses, mais qui sont de l'ordre du détail pour ce projet, alors je vais en lister quelques unes ici :
- mes CPU aiment travailler de manière symétrique. quand je mets n workers, je gagne plus en pourcentage de vitesse en passant d'un nombre impair à un nombre pair. Les chiffres :
- de 1 à 2 CPU : 3.37 fois plus rapide (le programme n-multithread est plus lent que ne l'était le programme monothread équivalent si l'on ne met qu'un seul thread worker, n=1) ;
- de 2 à 3 CPU : 1.12 fois ;
- de 3 à 4 CPU : 1.67 fois ;
- les regex sont assez lentes, il y a potentiellement une bonne optimisation possible en bidouillant des C-strings au lieu des
std::stringdu C++ (le pré-parser C est beaucoup beaucoup plus rapide que le programme C++, aussi parce que son travail ne consiste qu'en des substitutions/suppressions), mais le temps de développement serait plus long, et le risque d'overflow/segfault possible.
À la suite d'une recherche infructueuse sur beaucoup de moteurs de recherche (Qwant, Google, Yahoo, et DuckDuckGo), j'ai remarqué que les résultats de mon mot-clef obscur que DDG me présentait étaient les mêmes que ceux de Yahoo.
Coïncidence ? Je ne crois pas !

Il y a déjà eu des histoires de résultats volés entre moteurs de recherche, mais ceci n'en est pas une : depuis "quelques années" DDG et Yahoo collaborent : cf. la déclaration de DDG ici et celle de Yahoo là.
Pas vraiment une nouvelle donc, mais une avancée dans l'univers DuckDuckGo (qui est vaste et probablement intéressant).
Bonne journée et à très bientôt !
Motius
]]>Par le fait, Let's Encrypt a gagné énormément d'utilisateurs en très peu de temps, au dépends d'autres autorités de certification, dont StartCom et son service StartSSL, qui fournit également des certificats gratuits reconnus par la plupart des navigateurs. Aujourd'hui, StartCom riposte avec un nouveau service automatisé.
StartCom a envoyé un mail à ses utilisateurs pour annoncer la nouvelle.
StartCom, a leading global Certificate Authority (CA) and provider of trusted identity and authentication services, announces a new service – StartEncrypt today, an automatic SSL certificate issuance and installation software for your web server.
StartEncrypt is based the StartAPI system to let you get SSL certificate and install the SSL certificate in your web server for free and automatically, no any coding, just one click to install it in your server.
Compare with Let’s Encrypt, StartEncrypt support Windows and Linux server for most popular web server software, and have many incomparable advantages as:
(1) Not just get the SSL certificate automatically, but install it automatically;
(2) Not just Encrypted, but also identity validated to display EV Green Bar and OV organization name in the certificate;
(3) Not just 90 days period certificate, but up to 39 months, more than 1180 days;
(4) Not just low assurance DV SSL certificate, but also high assurance OV SSL certificate and green bar EV SSL certificate;
(5) Not just for one domain, but up to 120 domains with wildcard support;
(6) All OV SSL certificate and EV SSL certificate are free, just make sure your StartSSL account is verified as Class 3 or Class 4 identity.
StartEncrypt together with StartSSL to let your website start to https without any pain, to let your website keep green bar that give more confident to your online customer and bring to online revenue to you. Let’s start to encrypt now.
Pour résumer, StartEncrypt supporte également les certificats plus "professionnels" (comprendre plus onéreux) dont les certificats EV, qui permettent d'avoir un témoin dans le navigateur indiquant la société qui possède le certificat (cette catégorie de certificats indique que la vérification d'identité est plus stricte, mais sur le plan algorithmique, la sécurité est la même), ainsi que les wildcard (nombre de sous-domaines illimités).
Du point de vue technique, l'utilitaire fourni par StartCom est un binaire opaque, en licence propriétaire, et il est donc impossible de vérifier les effet du programme, d'autant plus qu'il s'exécute en root et que l'une des fonctionnalités est de toucher directement aux configurations du serveur web, comme ce que propose Let's Encrypt, et donc les chances de casser une installation existent (que ce soit à cause de cochonneries volontaires ou de bugs d'innatention ce qui arrive plus souvent que ce que l'on veut bien croire).
Précisons que si on tient à rester sous StartSSL, il existe une API qui permettait d'automatiser ce travail bien avant StartEncrypt, et dont des implémentations par des tiers sont trouvables, même si je n'en ai pour le moment testé aucune.
]]>Un nouveau shell est né. C'est le genre de nouvelles qui, chez les sysadmins, fait pousser des hourras pour les uns et fait ricaner doucement les autres. Un petit points sur quelques unes de ses caractéristiques.
Nombreux sont les administrateurs frustrés par les efforts de frappe de texte lorsqu'il s'agit d'utiliser Bash, et qui préfèrent carrément se faire des scripts Python à la place. En effet, si vous vous souvenez de mon tutoriel Let's Encrypt, vous verrez des commandes Bash assez longues (et encore, ce n'est rien comparé à d'autres).
Xonsh promet d'allier la robustesse de Bash et l'aisance de Python. Car oui, en Python, on tape en une ligne ce que d'autres langages permettent de faire en 10, pour peu que l'on dispose des bonnes bibliothèques. Xonsh dispose apparemment de plus de commandes internes, ce qui lui permet par exemple d'effectuer des calculs tout simplement en les tapant dans le prompt, sans autre forme de procès, par exemple :
root@marvin ~ # 1 + 2 \* 3
7On retrouve aussi une grande prise en charge des expressions régulières, utiles pour le glob des noms de fichiers par exemple. De quoi mettre les bons vieux utilitaires comme grep, sed, cut et awk à la retraite...
Je vous laisse découvrir ci-dessous une démonstration de l'utilisation de Xonsh.
On ne pourra s'empêcher de se rappeler, et les contributeurs de Xonsh le citent eux-même, le shell Fish, censé être beaucoup plus amusant à utiliser à grand coup de couleurs et d'auto-complétion à tout-va. Même si ce shell est très agréable à utiliser, son seul point fort est sa dorure extérieure. Pour ce qui était du scripting, il utilise des standards pas franchement catholiques, dans le sens qu'ils étaient fondamentalement opposés à ceux de Bash, et qu'il n'a pas réussi à imposer. Car dans le domaine des outils très fréquemment utilisés comme le shell, il n'y a que deux solutions : soit réussir à instaurer ses standards, soit se soumettre à ceux existants. Vous savez, les standards sont des choses très délicates, car par définitions, ils doivent rester très peu nombreux...

Enfin bon, ici, il s'agit de Python, quand même, une technologie qui a fait ses preuves...
]]>Depuis quelques semaines, je m'intègre au sein de l'activité de ces ateliers communautaires. J'ai pris connaissances des enjeux de chaque parti, j'ai noté les tensions qui peuvent les opposer, et dans chacun deux, il y a des ensembles d'éléments qui me plaisent et d'autres qui me déplaisent.
Avant que vous ne continuiez la lecture de cet article, un avertissement. Une petite partie de ce texte reflétera ma prise de position et mon expérience personnelle. Je préfère personnellement les hackerspaces, mais si vous êtes partisan de l'autre école, s'il vous plaît, n'en soyez pas vexé. Comme toujours, si vous estimez que j'ai tort, vous pouvez toujours commenter ou venir nous en parler autour d'une bière virtuelle sur IRC.

Le Fablab, un espace rangé, discipliné.
Fablabs : la pointe du matériel au service de l'individu
C'est probablement le type d'atelier communautaire le plus médiatisé. Probablement parce qu'il promeut un modèle industriel original.
On y fait quoi ?
Avant tout, un Fablab est un atelier. Sa vocation est de permettre à n'importe quel bricoleur de réaliser son projet matériel. En gros vous arrivez avec votre idée, et vous ressortez avec sous le bras.
Un Fablab est parfois amené à effectuer des prestations pour des entreprises, contre espèces sonnantes et trébuchantes. Il arrive même que le Fablab ait des horaires d'ouverture dédiés aux entreprises, et donc fermé à tous les autres utilisateurs.
Quel statut ?
Un Fablab, pour être considéré comme tel, doit se plier à la charte commune des fablabs du monde entier, charte mise au point par un éminent professeur du MIT. En contrepartie, le Fablab bénéficie de la reconnaissance des autres Fablabs et dispose de la base de conaissance du grand réseau commun mondial des Fablabs.
Quelles conditions ?
Le Fablab dispose en général de matériel relativement neuf et de bonne qualité, ce qui implique généralement des frais à l'utilisation pour l'utilisateur ; selon moi, ces utilisateurs sont des clients plus que des contributeurs du Fablab.

Le Hackerspace : un fouilli sans nom, un nid humain.
Hackerspaces : bienvenue à bord, matelot.
Les Hackerspaces ont une définition volontairement plus floue et plus libre.
On y fait quoi ?
Au Hackerspace, on peut y faire absolument toute activité constructive, dans une multitude de domaines : informatique et électronique bien sûr, mais également mécanique, menuiserie, art, musique, parfois même jardinage, cuisine... Certains Hackerspaces sont un peu spécialisés dans certains domaines. L'idée étant que si vous savez faire un truc, vous êtes cordialement invité à mener un atelier ponctuel ou récurrent, afin d'initier des nouvelles personnes.
On y aide également des personnes extérieures et d'autres associations, notamment en organisant des install party, en construisant des meubles et des installations diverses.
L'activité d'un Hackerspace est aussi militante : outre la tendance des membres d'un hackerspace à favoriser et inciter à l'usage du libre (ce qui est une très bonne habitude), il peut aussi avoir une conviction politique en son sein. Comprenez-moi bien, un Hackerspace accueille les gens de tout bord politique avec le même intérêt. Il arrive que la question de la politisation de l'association se pose, en particulier pour son fonctionnement interne.
Quel statut ?
Un Hackerspace est avant tout une association, et les personnes qui le fréquentent en sont des membres, qui ont donc un pouvoir de décision au sein de la communauté. Il existe des rassemblement de Hackerspaces, sans empêcher chaque Hackerspace d'être autonome.
Quelles conditions ?
Dans un Hackerspace, si la bière peut couler à flot, ce n'est pas le cas de l'argent. Ici, toutes les actions sont bénévoles, l'intégralité du budget vient des (très maigres) cotisations des membres et des éventuels dons, financiers ou matériels. En général, les ustensiles utilisés sont vieux, récupérés et recyclés. La mentalité du Hackerspace est donc de faire du neuf avec du vieux plutôt que d'avoir des outils derniers cris pour être plus efficace.

Exemple de récup : un réflecteur de lampe bricolé à partir du capot d'un vieux PC
Alors, dois-je aller au Fablab ou au Hackerspace ?
Si vous cherchez un endroit ou bricoler, si vous avez dans votre ville accès "uniquement" à l'un ou l'autre, alors allez-y sans vous poser de question, car vous êtes chanceux ! Il existe encore de nombreux endroits, notamment en campagne, ou il n'y a ni l'un ni l'autre. Si vous avez le choix entre un Fablab ou un Hackerspace à l'endroit ou vous êtes, cela dépend de votre besoin. Voici un récapitulatif des orientations des uns et des autres si on devait résumer grossièrement leurs motivations :
- Le Fablab incite à l'innovation, tandis que le Hackerspace vise à lutter contre l'obsolescence programmée.
- Le Fablab pousse à rendre les gens autonomes, tandis que le Hackerspace croit plutôt à l'entraide au sein d'une communauté.
- Le Fablab vise le domaine de l'industrie, tandis que le Hackerspace préfère le bricolage amateur.
Happy hacking !
]]>David Revoy est un artiste et informaticien français. Il a à son actif plusieurs projets déjà bien connus, comme la direction artistique du court-métrage Sintel, un des splendides projets Blender. Il a également travaillé sur des jeux vidéos, et il a notamment eu l'occasion de travailler pour Valve.

Sintel, sorti en 2010
La raison qui me pousse à parler de lui, outre le fait toujours appréciable qu'il publie toutes les œuvres dont il a la propriété morale en licence Creative Common, c'est le projet dans lequel il se concentre le plus en ce moment, c'est à dire son webcomic Pepper & Carrot, prenant place dans un univers fantasy remarquable, et racontant les aventure rafraîchissantes de la jeune et gentille sorcière Pepper et de son chat Carrot.

Extrait d'une planche de Pepper & Carrot.
L'univers dispose d'un magnétisme rarement atteint à mon sens. On sent l'influence manga dans le style, ce qui en fait assurément une œuvre fort intéressante. L'héroïne est tout-à-fait attachante, même si je ne suis peut être pas objectif, j'ai toujours eu un coup de cœur pour les petites sorcières.
Pour cette bande dessinée, David n'a utilisé que des outils libres sous GNU/Linux, notamment Krita, Inkscape et Gmic. Krita permet de faire du dessin bitmap, Inkscape pour le dessin vectoriel et Gmic pour la post-production.
Si vous êtes comme moi sous le charme de cette sympathique petite sorcière, je vous invite à rétribuer l'artiste via sa page Patreon (j'aimerais qu'il existe un moyen plus orthodoxe librement parlant, mais bon, Rome ne s'est pas construite en un jour).
À bientôt pour d'autres découvertes, et n'hésitez pas à partagez vos propres coups de cœur en commentaires ou sur IRC.
]]>Mesdames, mesdemoiselles, messieurs, voici l'occasion de vous dévoiler une nouvelle récompense créée par Hashtagueule afin de mettre en valeur les pires erreurs/aberrations de l'informatique. Sans plus attendre, voici la première remise du Groin d'Or.
Aujourd'hui, le lauréat du Groin d'Or est Marco Marsala. Cet homme tenait une entreprise d'hébergement italienne appelée Network Solution slr, et possédait environs 1500 clients. Je parle au passé, parce qu'hélas, cette entreprise n'existe plus aujourd'hui, à cause de circonstances tragiques que nous allons expliquer.
Ce brave homme utilisait l'outil de déploiement massif de configuration Ansible. Pour faire simple, il s'agit d'un programme qui permet d'automatiser des opérations de maintenance et de déploiement sur un grand nombre de serveurs à la fois. L'usage d'un tel logiciel est parfaitement adapté à sa configuration, il a donc raison de le faire. Malheureusement, il l'a très mal utilisé. Je ne veux pas dire qu'il n'a pas su se servir d'Ansible en particulier, mais il a transgressé les lois de sécurité du royaume de la production.
Dimanche dernier, Marco a posté une question sur le site bien connu de question/réponse pour les experts en administration système Server Fault. Voici sa question traduite en français :
Je dirige une petite société d'hébergement avec plus ou moins 1535 clients et j'utilise Ansible pour automatiser certaines opérations devant être exécutées sur tous les serveurs. La nuit dernière, j'ai exécuté par mégarde, sur tous les serveurs, un script Bash contenant
rm -rf {foo}/{bar}, ces variables n'étant pas définies suite à un bug en amont de cette ligne.Tous les serveurs ont été effacés, ainsi que les sauvegardes externes, vu que les volumes distants ont été montés juste avant par le même script (il s'agit d'un script de maintenance des sauvegardes).
Comment puis-je maintenant me rétablir d'un
rm -rf /aussi vite que possible ?
Il s'agit d'une très bonne question, Marco. Si bonne que les seules solutions existantes sont si complexes, donc si chères, que tu ne pourra pas te les offrir.
La situation semble si irréaliste, du fait de la négligence de cet administrateur système de pacotille, que la question a été prise par beaucoup pour un troll. Comme il aurait pu s'y attendre, Marco s'est pris des réponses cinglantes et acérées dans la figure :
Pas besoin de conseils techniques, trouve toi un avocat.
Tu viens d'atomiser ta société.
Désolé de te le dire, mais ta boîte est morte en pratique.
Il en résulte que Marco a bel et bien fait couler sa boîte, et il va vraisemblablement se retrouver avec un gros paquets d'ennuis financiers et juridiques, de la part de ses clients, qui se retrouvent le bec dans l'eau, avec leurs données perdues, leurs sites de vente hors ligne, ce qui peut également entraîner leurs propres entreprises dans le naufrage.
Ce premier Groin d'Or est amplement mérité.
Maintenant les enfants, que peut-on retenir de cette étude de cas ? Eh bien, il faut retenir ces quelques préceptes de la production :
- Faites des sauvegardes : beaucoup, dupliquées, isolées. Ne vous amusez pas à placer tous vos œufs dans le même panier. Copiez vos sauvegardes sur des serveurs différents, et si possible, à des endroit géographiques différents. Limitez les communications avec ces serveurs de sauvegardes au strict minimum.
- N'utilisez jamais en production quelque chose qui n'a pas été testé avec rigueur. Vous ne pouvez vous permettre aucun bug sur vos serveurs de production, c'est pour ça que l'on a inventé les stades de développement et de pré-production.
- Un grand pouvoir implique de grandes responsabilités. Ici, plus vous avez de clients, plus vous aurez d'ennuis quand la situation sera intenable.
La remise du Groin d'Or est maintenant terminée, à plus tard pour découvrir le prochain lauréat.
EDIT 2 : Les clients de Marco Marsala ont du quand même faire une tête bizarre en voyant apparaître la nouvelle dans la presse.
]]>Le français Jean-Michel Jarre, compositeur de musique électronique français, un dinosaure de la musique électronique (67 ans, premier single sorti en 1971) a réussi à obtenir un contact avec Edward Snowden via le journal The Guardian afin de lui proposer une collaboration pour un morceau de son nouvel album. Et le plus amusant dans l'histoire, c'est que Snowden a accepté.
Jarre s'est dit sensible à ressemblance entre le combat de Snowden et la résistance pendant la Seconde Guerre mondiale, dans laquelle sa propre mère s'était engagée. Snowden, quant à lui, s'est dit grand amateur de musique électronique.
Voilà, pas grand chose à dire d'autre à part l'étonnement de l'affaire. Bien entendu, les détails des rendez-vous entre Jarre et Snowden sont gardés secrets, pour des raisons qu'il n'est plus à préciser.
On attendra donc avec impatience la sortie de ce morceau Exit qui fera partie de l'album Electronica volume II: The Heart Of Noise le 6 mai prochain. Bien sûr, achetez cet album dans une boutique sans DRM et sans empreinte audio, cela va de soi.
]]>Oui, j'ai mis cet article dans la catégorie Art. Ce que je vais vous présenter est bel et bien de l'art.
Simone Giertz est une nouvelle youtubeuse suédoise. Sa première vidéo date d'il y a environ 1 an, mais sa popularité décolle seulement depuis quelques mois, ce qui fait que je peux encore en parler en tant que découverte sans sembler trop mainstream.
Youtube + Suède, vous allez me dire que ça s'annonce mal, hein ? Bonne surprise, sa chaîne est pour le moins originale.
Touche à tout notable, la jeune vidéaste de 25 ans est tombée dans le merveilleux domaine de la construction de robots, principalement à base d'Arduino et de ruban adhésif. La particularité de ses robots est, selon la conceptrice elle-même, que ce sont des robots "merdiques". C'est ici que cela devient intéressant. La jeune femme prend tellement de plaisir et met tant de bonne humeur dans la construction de ses robots qui ne servent à rien que cela en devient artistique.
Voyez plutôt par exemple sa machine à rouge à lèvre :
Simone exerce une activité créatrice dans laquelle elle éprouve du bonheur et provoque des réactions sur les autres. C'est ma définition de l'art.
Je vous invite également à jeter un œil à sa page Github, peuplée de quelques projets farfelus, que je vous laisse découvrir.
À très vite !
]]>On va donc aujourd'hui parler mobile, plus particulièrement du domaine Android, cet OS grand public accordant le plus, à mon sens et celui de beaucoup d'autres, de pouvoir à l'utilisateur. Les esclaves propriétaires de téléphones Apple, désolé, nous compatissons, mais nous ne pouvons pas pour le moment vous fournir d'astuces significatives dans le domaine.
Android est développé par AOSP, un projet dans lequel Google est amplement majoritaire en implication. C'est un fait. Cependant, une partie de cet OS est en licence libre, ce qui permet à des OS basés sur Android (dites ROMs alternatives) de voir le jour. La version Google, quant à elle, est servie avec un ensemble de programmes destinés à se connecter aux services Google, afin de vous prodiguer un accès facile à votre compte Google et les services associés, pour masquer son vrai but, qui est de ramasser de la donnée sur vous. Pour des personnes aimant leurs services auto-hébergés ou qui ne souhaitent pas utiliser ces services, il est possible d'utiliser une ROM alternative pour supprimer les services Google.
Cependant, si on élimine les services Google, on se prive également de la boutique Google Play, ce qui peut en pénaliser plus d'un. Vous avez toujours la possibilité d'utiliser les dépôts standards F-Droid, mais cela reste un peu pauvre. Une autre solution serait d'installer le store d'Amazon, mais outre le fait que vous vous jetez vous même de Charybde en Scylla, ce n'est pas très conseillé car il y a plus d'applications piégées sur ce store, et moins de "bonnes" applications. Enfin, la solution la plus dangereuse serait de télécharger les apps à partir de sources non vérifiées comme il y en a des centaines sur Internet, ce qui est légalement douteux et catastrophique niveau sécurité, sans parler de l'absence de système de mise à jour. Point n'est besoin d'en dire plus, nous allons voir comment installer des applications du Google Play sans les services Google Play.
Niveau 0 : Installer une ROM alternative
Ce n'est pas le but de ce tutoriel, peut être pour une prochaine fois. La description de cette étape sera donc très sommaire, en attendant vous pourrez trouvez de très nombreux tutoriels pour le faire, ici on se concentrera en priorité sur la valeur ajoutée Hashtagueule.
Il vous faut d'abord choisir une ROM. Il y en a des dizaines, plus ou moins spécialisées. L'une des ROMs alternatives est CyanogenMod. Pour le moment, ma ROM de prédilection reste Dirty Unicorn, qui a un développement assez actif, qui intègre relativement rapidement des dernères nouveautés de la version Google d'Android, et qui a beaucoup de possibilités faciles d'accès de personnalisation d'interface. Pour information, cette ROM tourne impeccablement sur mon Nexus 5.
En partant d'un mobile sous Android Google, les étapes sont toujours les même :
- rootage de l'appareil ;
- installation d'un bootloader ;
- copie de la ROM dans la mémoire de l'appareil ;
- flash de la ROM.
Avant ces étapes, assurez vous de sauvegarder tout ce qu'il y a à sauvegarder, et notez votre identifiant Android, vous en aurez besoin plus tard. Pour ce faire, vous pouvez taper la combinaison *#*#8255#*#* sur le clavier du téléphone. Un texte va s'afficher, votre identifiant Android est à la ligne "Device ID", écrit sous la forme "android-votreidentifiant" (ce qui compte est après le tiret).
Vous pouvez également obtenir cet identifiant avec l'application Device ID. À télécharger sur le Google Play Store. Amusant quand on sait qu'on a besoin de ce numéro principalement pour éviter d'utiliser ce store.
Une fois votre ROM flashée, installez l'application F-Droid sur votre mobile. Cela vous permettra d'obtenir des applications libres, mais également de vous faire votre propre dépôt d'applications.
Niveau 1 : Télécharger les apps sur l'ordinateur
À ce niveau, l'important est de comprendre que vous téléchargerez les applications qui vous intéressent sur votre ordinateur en le faisant passer pour un appareil Android auprès de Google. Il y a plusieurs solutions pour y arriver. Personnellement, j'utilise l'extension Firefox APK Downloader dont le rôle est d'ajouter un bouton sur chaque page web du Google Play Store. Vous aurez besoin de configurer l'application en renseignant votre adresse de compte Google, votre mot de passe, et l'identifiant Android que vous avez noté plus tôt.
Notez le bouton "Download APK" permettant de télécharger directement l'application sur votre PC.
À partir de là, vous pouvez si vous le souhaitez installer directement l'application sur votre appareil à l'aide de la commande de débug d'Android :
adb install /chemin/vers/l/application/téléchargée.apkMais ce serait passer à côté de fonctionnalités intéressantes :
- En faisant ainsi, vous êtes obligé de brancher votre téléphone à chaque fois que vous voulez installer une application, ce qui implique d'avoir son câble et de ne pas avoir peur de ruiner le cycle de la batterie de votre appareil. Ou alors vous autorisez le débug par réseau, ce qui est vivement déconseillé car très peu sécurisé (il suffit de connaître l'IP de votre appareil pour que n'importe qui puisse installer n'importe quoi).
- Pas de système de mise à jour OTA : vous ne serez pas informé des mises à jour pouvant être cruciales, et vous devrez réinstaller manuellement chaque application en passant par l'ordinateur.
Niveau 2 : Mettre en place votre dépôt
Il est alors intéressant d'avoir un serveur sur lequel vous allez constituer votre dépôt privé. Pour cela, vous allez avoir besoin des programmes suivants :
- le gestionnaire de dépôt F-Droid (paquet
fdroidserverdisponible dans les dépôts Debian) qui va permettre au client F-Droid de se synchroniser sur votre serveur ; - googleplayupdater, un petit outil bien pratique qui permet de mettre à jour toutes les applications APK dans un dossier donné ;
- un serveur web, Nginx est tout indiqué pour ce genre de tâches, sachant que l'on va servir uniquement du contenu statique.
Sur votre serveur, créez le dossier du dépôt, chez moi il s'agit du dossier /var/apk. Placez-vous dans ce répertoire et effectuez la commande suivante :
fdroid initCette commande va créer un certain nombre d'éléments, dont le dossier repo et le fichier config.py.
Intéressons-nous au fichier de configuration. Normalement les commentaires sont assez explicites. Voici à quoi peut ressembler votre fichier de configuration :
#!/usr/bin/env python2
mvn3 = "mvn"
gradle = "gradle"
repo_maxage = 0
repo_url = "http://bidule.machin.truc"
repo_name = "Repo perso de Raspbeguy"
repo_icon = "fdroid-icon.png"
repo_description = """
Comme j'utilise Dirty Unicorn tout nu sans les services Google play,
ben je suis dans l'obligation de magouiller...
"""
archive_older = 3
archive_url = "https://f-droid.org/archive"
archive_name = "My First FDroid Archive Demo"
archive_icon = "fdroid-icon.png"
archive_description = """
The repository of older versions of applications from the main demo repository.
"""
keydname = "CN=bidule.machin.truc, OU=F-Droid"
keyaliases['com.example.another.plugin'] = '@com.example.another'
# Wiki details
wiki_protocol = "http"
wiki_server = "server"
wiki_path = "/wiki/"
wiki_user = "login"
wiki_password = "1234"
update_stats = False
stats_to_carbon = False
carbon_host = '0.0.0.0'
carbon_port = 2003
build_server_always = False
char_limits = {
'Summary': 50,
'Description': 1500
}Les lignes 9 à 15 de cet exemple sont les plus importantes. En fait, normalement, vous n'aurez pas à modifier les autres lignes pour que le dépôt fonctionne bien.
Il vous faut ensuite copier vos APK directement dans le dossier repo. Ensuite, à partir du dossier du dépôt (dans notre cas /var/apk), effectuez la commande suivante, que vous devrez refaire après chaque ajout d'application au dépôt :
fdroid update --create-metadataIl faut maintenant mettre en place le serveur web afin que le dépôt soit accessible depuis votre appareil par le réseau. Créez donc un server block pour Nginx ressemblant à cela, dans le cas de l'utilisation de SSL/TLS, ce que je ne peux que vous recommander :
server{
listen 80;
listen [::]:80;
server_name bidule.machin.truc;
location ~ ^/.well-known/acme-challenge(/.*)?$ {
root /etc/letsencrypt/webrootauth;
default_type text/plain;
}
return 301 https://$server_name$request_uri;
}
server {
listen 443;
listen [::]:443;
server_name bidule.machin.truc;
access_log /var/log/nginx/fdroid.access.log;
error_log /var/log/nginx/fdroid.error.log;
ssl on;
ssl_certificate /etc/letsencrypt/live/machin.truc/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/machin.truc/privkey.pem;
server_name_in_redirect off;
root /var/apk;
location ~ ^/.well-known/acme-challenge(/.*)?$ {
root /etc/letsencrypt/webrootauth;
default_type text/plain;
}
location / {
try_files $uri $uri/ =404;
}
}Les lignes 1 à 9 concernent la redirection de HTTP vers HTTPS. Vous reconnaîtrez certainement aux lignes 6 à 9 et 29 à 32 les instructions qu'on a introduites pour l'automatisation des renouvellements de certificats Let's Encrypt. Si ça ne vous dit rien, vous pouvez faire une cure de rappel par ici, c'est gratuit et ça vous met plein de belles choses dans la tête.
Rechargez Nginx, puis il faut maintenant tester sur votre appareil. Dans F-Droid, dans le menu en haut à droite, rendez vous dans la Gestion des dépôts, puis tapez le "+" pour ajouter un dépôt (duh...). Entrez https://bidule.machin.truc/repo en adresse de dépôt et rien pour l'empreinte (vous êtes le seul utilisateur de votre propre dépôt, vous savez déjà la provenance de ce qu'il y a dessus, de plus comme vous êtes déjà en connexion sécurisée, il n'y a plus beaucoup de risques).
Laissez mouliner quelques secondes, et paf, normalement vous avez un dépôt fonctionnel.
Le dépôt a bien été ajouté.
Exemple d'app ajoutée dans mon dépôt.
Une fois cette victoire confirmée, rappelez-vous le but initial de la manœuvre : avoir des applications qui se mettent à jour toutes seules comme des grandes.
Niveau 3 : Automatiser la mise à jour des apps
C'est ici que googleplayupdater entre en scène.
Pour disposer de cet outil, clonez le dépôt quelque part sur votre serveur (on se fiche de l’endroit, le programme sera installé ailleurs).
Installez le programme par la commande :
python setup.py installNotez que vous aurez peut-être à installer au préalable l'outil de déploiement python-setuptools :
apt install python-setuptools # si vous utilisez python2
apt install python3-setuptools # si vous utilisez python3Attention, si vous utilisez Python 3 (c'est toujours recommandé de l'utiliser si possible et pas trop enquiquinant), vous devez installer manuellement une dépendance par la commande :
pip install https://pypi.python.org/packages/source/p/protobuf/protobuf-3.0.0a3.tar.gz#md5=6674fa7452ebf066b767075db96a7ee0Ensuite, copiez et renommez le fichier config_example.py dans un endroit adéquat (par exemple /etc/googleplayupdater/config.py) et modifiez-le afin qu'il ressemble à ceci :
from __future__ import unicode_literals
LANG = "en_US" # can be en_US, fr_FR, ...
ANDROID_ID = "votre_identifiant_android"
GOOGLE_LOGIN = '[email protected]'
GOOGLE_PASSWORD = 'mdp_compte_google'
AUTH_TOKEN = None
# force the user to edit this file
if ANDROID_ID == None or all([each == None for each in [GOOGLE_LOGIN, GOOGLE_PASSWORD]]):
raise Exception("config.py not updated")Bien sûr, adaptez les variables ANDROID_ID, GOOGLE_LOGIN et GOOGLE_PASSWORD avec ce que vous avez mis dans la configuration de votre extension Firefox...
Vous pouvez tester la configuration avec la commande suivante :
/usr/local/bin/googleplayupdater -c /etc/googleplayupdater/config.py -v /var/apk/repo
Si vous constatez que tout se passe bien, vous pouvez alors finaliser en créant un script cron update_apk que vous placerez dans /etc/cron.daily/ contenant ce code :
#!/bin/bash
GPUPD=/usr/local/bin/googleplayupdater
CONFIG=/etc/googleplayupdater/config.py
REPO=/var/apk
LOG_GPU=/var/log/gpupd.log
LOG_FDROID=/var/log/fdroid.log
echo -e "\n********** $(date)\n" >> $LOG_GPU
$GPUPD -c $CONFIG -v $REPO/repo >> $LOG_GPU 2>&1
cd $REPO
echo -e "\n********** $(date)\n" >> $LOG_FDROID
fdroid update --create-metadata >> $LOG_FDROID 2>&1Ainsi, votre dépôt se mettra à jour tous les jours. Et votre appareil vous notifiera dès qu'une mise à jour sera disponible. Et vous n'avez rien de Google sur votre téléphone, c'est magnifique.
Inconvénients / améliorations possibles
Certaines application sont butées et requièrent la présence des services Google Play pour fonctionner, le cas le plus décevant étant Signal, que j'ai dû renoncer à utiliser. Peut-être que je trouverai un moyen de le compiler à ma sauce sans les dépendances qui m'embêtent.
Sinon, on pourrait travailler à trouver un moyen de télécharger les apps directement par le serveur, et ne pas être obligé de passer par Firefox. Ça pourra être l'objet d'un article ultérieur, si je trouve un moyen convainquant de le faire.
]]>Je souhaite vous présenter un système d'exploitation à la fois ergonomique, fiable et efficace, pour changer. En effet, on vous parle toujours de systèmes libres, en constante évolution, et donc perpétuellement truffés d'erreurs.
Aujourd'hui, nous partons donc à la découverte d'un OS qui nous est proposé par nos amis nord-coréens, un OS conçu pour la sécurité et le bonheur de la population : il s'agit de Red Star OS.

Kim Jong-un qui se rend sur Hashtagueule depuis son ordinateur sous Red Star OS.
Parlons tout d'abord de l'intelligence esthétique. Admirons le charme de ce fond d'écran, symbole de l'unité du Pays des Matins Calmes, de sa prospérité, de son ouverture diplomatique et de sa paisible atmosphère.
Les canons de beautés de Corée du Nord
Notez également cette touche d'élégance que représente le drapeau animé du pays, dans lequel souffle le vent du progès et du patriotisme.  J'en ai un pincement au cœur et la larme à l'œil.
J'en ai un pincement au cœur et la larme à l'œil.
Constatons qu'il s'agit d'un système Linux basé sur la branche Red Hat, comme en témoigne l'analyse des fichiers de configurations.
L'interface de la mouture 3.0 de Red Star OS est en QT et reprend copie les codes esthétiques d'OS X. La version 2 s'orientait plutôt sur l'interface de Windows. Mais à l'évidence, ces OS n'arrivent même pas à la plante des pieds de Red Star OS.
Tout pareil.
J'ai réussi à passer l'interface en anglais avec quelques difficultés, sachant que je ne parle ni lis absolument pas le coréen, et que de toute façon il n'existe aucun réglage en interface graphique permettant de changer la langue. Quelle sage décision de la part des concepteurs ! Il s'agit en effet d'une option superflue, et il est inutile de surcharger l'utilisateur d'options superflues.
On peut uniquement changer le clavier.
Il m'a été impossible de configurer correctement la connexion de l'OS, car Red Star OS étant le fruit de nombreuses années de recherche des studios de Corée du Nord, la sécurité est primordiale, donc la connexion doit obligatoirement passer par une passerelle coréenne, et uniquement accessible depuis ce pays, et cette passerelle est hard-codée (enfin, c'est ce que j'ai supposé). Du coup, il me sera impossible de vous parler des performances du navigateur Naenara ("Mon Pays" en coréen), basé une version presque aussi récente de Firefox que celle utilisée pour Iceweasel sur Debian. C'est dire !
Pour conclure ce test, disons qu'il s'agit probablement de l'OS le plus sûr qu'il m'ait été donné de voir. Comment je peux en être sûr ? Eh bien c'est très simple, cet OS a été approuvé, et même recommandé, par le gouvernement de l'un des pays les plus influents du monde. Il s'agit du plus grand témoin de confiance.
Alors n'hésitez plus et installez Red Star OS dès maintenant !
]]>Le titre est assez explicite : on rempile sur d'autres points de vue sur le chiffrement, ce qui a été dit, les argumentaires etc.
Le chiffrement est un thème complexe en général, et avant d'en avoir fait le tour, il est nécessaire d'avoir beaucoup lu, réfléchi, etc. Et encore, notre réflexion ne s'attaque aux algorithmes que superficiellement, histoire d'en connaître leur structure et leur utilité, pas les détails d'implémentation. Vous l'avez compris, on reprend là où on s'était arrêtés.
L'EFF
On va commencer par l'argumentaire de l'EFF --- l'Electronic Frontier Foundation, une ONG composée de geeks et d'avocats, à ce que je vois, pour défendre bien des idéaux sur le net --- qui a publié un amicus curiæ --- ami de la cour en latin, désigne par métonymie un document qui servait à éclairer les décisions du souverain à l'époque, et à proposer un point de vue au gouvernement. Et vous n'imaginez pas ma surprise en le lisant. Je pensais --- sans être exhaustif, bien sûr --- avoir abordé la majorité des points importants à soulever dans ce débat, même brièvement. Eh bah non. l'amicus curiæ de l'EFF se trouve ici, et commence sur un ton très différent de mes articles sur le chiffrement. Merci internet, j'adore. Ça commence p.9 à la ligne 7.5 (si, si, allez voir le document vous dis-je) :
Amici curiae submitting this brief have a special interest in helping this Court understand that its Order places a significant burden on the free speech rights of Apple and its programmers by compelling them to write code and then to use their digital signature to endorse that code to the FBI, their customers and the world.
Si j'essaie de traduire pour les anglophobes/angloagnostiques, ça donne quelque chose comme :
Les Amis de la cour qui soumettent ce dossier ont un intérêt particulier à faire comprendre à la Cour que cet Arrêt (la demande de backdoor du chiffrement par un juge, NDT) pèse contre la liberté d'expression d'Apple et de ses programmeurs, puisque cet Arrêt les oblige à écrire du code et le signer numériquement et prendre la responsabilité de ce code devant le FBI, ses clients (Apple) et le monde.
En gros, et en français moins littéral, l'EFF soutien que :
- le premier amendement des États-Unis s'applique au code écrit par Apple (cf. la suite de l'amicus, où p.11 ils défendent le fait que le premier amendement est applicable) ;
- "par conséquent" --- tout l'intérêt de l'argumentation de l'amicus --- imposer à Apple d'écrire du code qui n'est pas le leur, puis de le signer constitue une violation du premier amendement du Bill of Rights.
On remarque qu'il y a un abîme culturel entre mon mode de pensée et celui des juristes américains, très pragmatiques, qui savent quels sont les outils à leur disposition, en l'occurence leur Constitution.
Il faut savoir qu'aux États-Unis, les principes énoncés dans le Bill of Rights ont une valeur beaucoup plus forte que dans notre France et son droit romain. C'est justement lié au type de droit en vigueur, notamment l'opposition droit romain/droit anglosaxon. Typiquement, le droit romain essaie à l'avance de prévoir tous les cas, et de définir les peines associées si nécessaire. Ce n'est pas le cas du droit anglosaxon où la jurisprudence et le lien entre les affaires est beaucoup plus important. Ainsi aux États-Unis, le premier amendement est quasi-absolu : il garantit la possibilité de pouvoir tout dire, mais dans le cas où une personne tient un discours haineux, à teneur racial où je ne sais quoi, elle risque de se retrouver devant les tribunaux s'il y a quelqu'un pour dire : "Ce que tu as dit là me porte préjudice".
Analyse
Vous comprenez la force de cet argumentaire : un juge ne peut pas décemment aller contre la constitution des États-Unis, de même le FBI ne peut pas obtenir une ordonance d'un juge pour forcer Apple à écrire du code qui n'est pas de lui. C'est sur cette base que l'amicus attaque l'ordonance qui contraint Apple (beaucoup de boîtes par extension).
À mon avis, ce type d'argumentaire a quand même une faiblesse si on regarde ce qui se passe en France : des députés menés par le Républicain Éric Ciotti ont essayé d'interdire le chiffrement fort en rendant illégal le refus de transférer des données chiffrées, applicable pour les vendeurs de logiciel, les opérateurs de télécommunications, et probablement de matériel (pas écrit mais on peut discuter la nature du chiffrement matériel à mon avis).
Les conséquences de ce type d'amendement qui interdit "les entreprises qui fournissent du chiffrement fort" de facto empêcherait des entreprises comme Apple de fournir du chiffrement fort pour la simple et bonne raison qu'Apple ne peut pas se permettre de perdre un à un des marchés aussi importants.
En conclusion de cette première partie, on peut dire que sauf si les États s'amusent à changer les règles du marché, ce qui est complètement possible, l'argumentaire de l'EFF est très fort aux États-Unis et très intéressant.
John Oliver hôte de Last Week Tonight : encryption
Vous le savez, Hashtagueule a une longueur d'avance sur tout dans ce monde --- ou presque ! Bon, d'accord, ce n'est pas vrai, sauf parfois, et en ce qui concerne le chiffrement, on est plutôt à l'heure. Donc, entre mon précédent article sur le chiffrement et celui-ci, un comédien britannique nommé John Oliver et émigré aux États-Unis a décidé que le thème de son seul-en-scène quasi-hebdomadaire à la télévision serait sur le chiffrement. Voici la vidéo sur DailyMotion et la même sur YouTube (pas disponible partout).
Je vous encourage à la regarder, puisque c'est fait sur un ton humoristique, et qu'une partie de ce qui suit commente la vidéo.
- À 2:18/6:10, John Oliver parle de l'iPhone de Syed Farook, et dit que le FBI ne peut pas rentrer dedans, ce qui n'est que la moitié de l'histoire : Apple a fourni la backup iCloud de cet iPhone. De plus la NSA a des accès aux iPhones probablement via des malwares et autres chevaux de troie, cf. ce qu'en dit Snowden, conséquence du fait qu'il n'existe pas de machine de Turing (donc d'ordinateur) absolument sécurisée contre toutes les attaques.
- À 4:26 : en effet, beaucoup pensent de manière trop simpliste au chiffrement. Pas de sécurité sur internet sans. Et c'est pas parce qu'on veut quelque chose qu'on l'obtient. En l'occurrence, les maths disent le contraire : si je chiffre des données avec un algorithme puissant, il va parfois être nécessaire d'utiliser des centaines de machines pendant des milliers d'heures pour décrypter ce qui a été chiffré. D'où l'utilisation d'une backdoor dans le logiciel comme solution alternative.
- À 8:00 : 175 iPhones état de NY seul. Cela conforte mon opinion que l'essentiel de cette affaire est le côté légal, cf. les autres arguments de La guerre sur le chiffrement 1.
- À 8:39 : All Writs Act : déjà cité dans l'amicus de l'EFF : selon l'EFF cet argument de type légal ne peut pas aller contre la constitution, cf. p.32 de l'amicus. Le texte de la loi énonce :
(a) The Supreme Court and all courts established by Act of Congress may issue all writs necessary or appropriate in aid of their respective jurisdictions and agreeable to the usages and principles of law.
En gros les juridictions peuvent faire les décrets pour faire appliquer des lois en vigueur, dans les limites de la loi.
Une brêve histoire de la guerre contre le chiffrement
- À 8:50--9:55 : John parle rapidement de l'histoire sur la guerre contre le chiffrement. Eh oui. C'est pas nouveau sous le soleil, tout ça, loin de là ! J'en profite pour faire un exposé un peu plus approfondi sur le sujet.
Dans les années 90, le chiffrement était encore classé comme arme de guerre aux États-Unis, avec les avantages et les inconvénients que ça comporte (le droit de porter une arme, par exemple) :

Legal Hacks @xkcd.com/504
Les inconvénients étant que l'export d'armes depuis les États-Unis était limité --- interdit aux civils.
N'en faisant qu'à sa tête --- et on le remercie --- Philip Zimmermann publie sur son FTP (public) le code source de sa première version de PGP (Pretty Good Privacy) un logiciel de chiffrement destiné aux mails (puis il publiera le code source dans un livre, de mémoire, qui sera publié à l'étranger :)).
Le résultat, c'est qu'il a eu des problèmes pendant à peu près trois grosses années pour avoir fait ça, et qu'un peu avant il a été repéré par un type super du nom de Eben Moglen --- un socle en ce qui concerne le droit dans le logiciel libre --- ce qu'il raconte dans cette vidéo YouTube de 10 min (le lien envoie directement à la partie sur le chiffrement), et aussi dans ce plus long PDF.
Pour faire court jusqu'en 1995 il aura des soucis avec la justice, jusqu'à ce que l'affaire tombe, lorsque les banques et commerces se sont rendus compte qu'il ne pouvait pas y avoir de transactions sur internet sans chiffrement pour la confidentialité, et signature pour la sécurité des échanges.
John Oliver ne parle pas énormément du problème qu'aurait été le fameux "Clipper Chip" permettant aux gouvernements une backdoor généralisée dans les ordinateurs : peut-être la majorité fait-elle confiance au gouvernement états-unien pour ne pas être dangereux, autant d'autres gouvernements sur la planète ne sont pas si agréables.
Qui plus est, on a appris que la NSA avait des programmes pour faire de l'espionnage industriel ce qui veut dire que même du gouvernement états-unien, beaucoup ont intérêt à se protéger, au moins un minimum.
- À 12:21 : "most agree" : cf les 46 grands noms de l'informatique qui signent l'amicus de l'EFF. Au hasard, il y a des cryptographes renommés (Zimmermann, Martin Hellman, Ron Rivest et j'en passe...), le créateur du langage Python, un des professeurs de Donald Knuth (impressionant !) et beaucoup trop pour une toute petite liste, allez lire la fin de l'amicus.
- À 12:55--13:34 : Le chiffrement est disponible et amélioré souvent en open source ou logiciel libre, ou les algorithmes sont ouverts et disponibles sur internet. Personnellement je préfère utiliser Signal que Telegram, et Snowden aussi (et cette fois c'est pas du bullshit contrairement à la case "Le saviez-vous" de Hashtagueule, où l'une des citations est "Je tiens mes infos de Hashtagueule --- Snowden")
- À 15:00 : "until i started getting briefed by people in the intel community." Je pense que la conclusion la plus objective concernant la guerre sur le chiffrement est "it's possible. but not that simple".
De nouvelles perspectives ?
Le dernier point que je vais aborder est la confiance. Je l'ai déjà évoquée, mais je refais une couche pour illustrer. Si l'on avait plus confiance dans son smartphone, de nouveaux services pourraient voir le jour, de nouvelles utilisation exister. Par exemple peu de gens utilisent leur téléphone pour parler à leur avocat ou leur notaire (je sais qu'il s'agit d'actes rares, mais surtout d'un endroit où il faut avoir pleinement confiance dans l'identité de la personne à qui l'on parle, les données échangées).
Pour illustrer mon propos, je vais faire simple : avec du chiffrement, les écoutes entre le téléphone portable de Sarkozy et son avocat auraient été plus difficilles. Il aurait fallu compromettre le téléphone et non pas seulement le mettre sur écoute. Qu'on l'aime ou qu'on trouve que c'est une ordure, je ne peux pas le plaindre étant donné qu'il a le premier renforcé discrètement le renseignement, et que sans son décret de 2008, il n'aurait peut-être pas été mis sur écoute, et qu'avec du chiffrement fort, il aurait très probablement eu la paix.
Merci de m'avoir suivi jusqu'ici, je vous souhaite une très bonne journée, j'espère que vous commenterez l'article, donnerez votre opinion sur le chiffrement, que ça nourira votre pensée itout. À très vite !
Motius
PS : tl;dr :
- l'EFF utilise le premier amendement pour défendre le droit d'Apple d'écrire du code, et par extension des logiciels de chiffrement fort.
- John Oliver traite du chiffrement dans son seul-en-scène.
GLaDOS a été notre serveur pendant presque 6 mois. D'aucuns dirons que 6 mois ne représentent pas un grand intervalle de temps pour un serveur. Et bien figurez-vous que ces 6 mois ont été, et seront probablement les mois les plus déterminants, tant pour le blog et l'établissement de son régime de croisière que pour l'épanouissement de ses chroniqueurs. D'ailleurs, cette migration en est le symbole : nous avons tellement appris, fait tellement d'expériences, ajouté tellement de services à notre cher serveur que nous avons dépassé ses limites de performances.
GLaDOS a été notre premier serveur à nous. C'est grâce à lui que nous avons acquis nos habitudes et forgé notre volonté. C'est donc non sans une certaine pointe de tristesse que nous quittons ce partenaire, et c'est pourquoi nous tenions à lui rendre ce petit hommage.
Mon cœur s'emplit de nostalgie et d'émotion lorsque je me remémore ce générique de fin, dernier message de notre ancien serveur.
Ne vous inquiétez pas, le meilleur reste devant nous, nous continuerons notre combat pour vous et avec vous.
Restez à l'écoute, séchez vos larmes, et restez gentils.
]]>Cela ne s'arrête pas à l'interface graphique. Si vous pratiquez la ligne de commande à haute dose, vous aurez sûrement envie de mettre un peu de fantaisie dans votre quotidien en personnalisant votre prompt, ce petit en-tête à chaque début de commande, montrant souvent votre nom d'utilisateur et le nom de votre machine, parfois d'autres éléments. Pour les "power-users", la personnalisation du prompt est au moins aussi importante que celle du fond d'écran par exemple.
Malheureusement, la personnalisation du prompt n'est pas chose aisée : elle fait intervenir des variables pas toujours évidentes à connaître, la gestion des couleurs est pour le moins complexe quand on a l'habitude de cliquer sur une interface graphique, et encore...
N'ayez crainte, des outils sont là pour vous aider. Par exemple pour bash, ce site vous facilite considérablement la tâche en vous proposant des modèles et en vous permettant de les personnaliser par un système de menus assez intuitifs.
Une fois que vous avez défini votre prompt, tout ce qu'il vous reste à faire est de copier la ligne générée dans la variable PS1 de votre fichier ~/.bashrc.
Bonne journée !
]]>Le Raspberry Pi original date de février 2012, conçu par la fondation du même nom. Les appareils Raspberry Pi sont des ordinateurs minimalistes monocartes, à l'origine développés dans le but d'enseigner l'informatique et d'équiper informatiquement les pays les plus pauvres. Il s'agit donc d'un PC à moins de 40$. Cependant, grâce à sa simplicité d'architecture, son ouverture et son très faible coup, cet appareil connaît un grand succès et est devenu une icône du DIY et des bricolos en tout genre. Beaucoup de projets nécessitant un composant de computation se sont construits autour de cet appareil, qui peut répondre à une multitude de besoins.
Au moment ou je vous parle, le troisième grand modèle (quatrième en comptant le RPi Zero) est disponible depuis le mois dernier.
Le RPi 3 est n'est pour le moment décliné qu'en modèle B, ce qui correspond à 4 ports USB et la présence d'un port Ethernet. L'évolution qu'il apporte par rapport au RPi 2 modèle B tient en un processeur un peu plus puissant (1,2 GHz 64 bits contre 900 MHz 32 bits, toujours en ARMv7) et la présence de communicateurs Wifi et Bluetooth intégrés. Si vous avez déjà un RPi 2 modèle B sans besoin de communication sans fil, ou que vous avez déjà acheté des dongles pour ajouter ces fonctions, il n'est donc pas très utile de changer votre gâteau à la fraise préféré.
Par contre, comme d'habitude, les prix sont translatés, donc un RPi 3 reste aussi abordable que ces prédécesseurs à leurs périodes de gloire, qui deviennent quant à eux encore meilleur marché. À bon entendeur...
À ce propos, vous pouvez répondre à notre nouveau sondage (dans la barre de gauche) à propos de votre préférence quant à la nature des tutoriels à venir. Bien sûr, celà ne vous empêche pas de nous le faire savoir en commentaire ou en nous parlant directement ;)
]]>Ça va peut-être vous paraître bizarre, mais je pense qu'il est grand temps de reparler de chiffrement, un dada chez moi me direz-vous. En effet, ça fait depuis mi-novembre (à cause des attentats du 13, en fait) que les choses ont commencé à s'agiter,
Revenons sur l'actualité récente. Depuis dix jours, Apple s'est relancé dans la guerre pour le chiffrement, face au FBI et à la NSA. Suivit par le PDG de Whatsapp (et Mark Zucherberg) et celui de Google.
Si on s'arrête un moment, il est très curieux que ce soient des entreprises qui défendent des droits des utilisateurs — en l'occurrence celui d'avoir une vie privée — contre leur gouvernement. On s'attent plus typiquement au schéma inverse, mais là, non.

Si l'on se replonge dans l'actualité moins récente, ce n'est pas la première fois que ce débat prend une si grande importance dans les médias. Je pourrais citer des dizaines d'articles, mais ce qui me paraît essentiel, c'est de partir de la source, c'est-à-dire qu'il s'agit-là d'une demi-victoire pour Edward Snowden. En effet, cela fait trois ans (juin 2013, mais Edward Snowden était prêt depuis 6 mois, le temps que Glenn Greewald prenne en main Tails et des moyens pour communiquer avec du chiffrement fort, GPG, OTR et via Tor) que Snowden veut que nous ayons ce débat. Demi-victoire, puisque l'autre aspect important est le respect de la vie privée, pour lequel le chiffrement est nécessaire, mais pas suffisant, mais c'est un autre débat.
Du coup, cela fait depuis mi-novembre, comme je vous disais, que beaucoup d'articles prennent position en faveur ou contre le chiffrement. Au hasard celui-ci (et là) où le directeur de la NSA ment en affirmant que sans le chiffrement, les attentats de novembres auraient pu être évités (cf. ceci, téléphone non chiffré, communication via SMS), ou celui-là sur lequel je suis tombé récemment --- et dont on va reparler.
Ce qu'il y a de remarquable, c'est leur tonalité. Ils ne sont pas objectifs, puisqu'ils refusent d'aborder toutes les parties du débat. Du coup je vais me faire "avocat de la défense", vu qu'il y a déjà beaucoup de "procureurs" ayant fait des réquisitoires contre.
L'article titre "Un Terroriste est-il un client Apple comme les autres ?", à laquelle la réponse évidente semble être "non". Mais l'article aurait tout aussi bien pu titrer : "Faut-il forcer Apple à fournir une backdoor au gouvernement états-unien, au risque que la Chine en demande une, et s'en serve contre des dissidents de Hong-Kong ?", un titre un peu long, mais au moins aussi pertinent.
En effet, il y a deux côtés à cette histoire. Le fait qu'effectivement, le chiffrement permet de cacher de l'information. Et le fait qu'il est parfois nécessaire de cacher de l'information. Soit parce que c'est votre droit (comme par exemple celui de ne pas participer à sa propre incrimination) soit parce que votre pays a un régime fort au pouvoir. En effet, la notion de terroriste est très arbitraire. Il faut se rappeler que les résistants au régime de Vichy étaient appelés terroristes (aussi là).
Du coup pourquoi cette bataille a-t-elle lieu ? Deux arguments me font penser qu'il s'agit d'abord d'une bataille juridique, et d'une façon de faciliter le renseignement pour le FBI ensuite (& la NSA, mais elle a plus de moyens).
- Premièrement, les services de renseignement de la Grande-Bretagne (leur GCHQ), l'Allemagne, et les États-Unis (via le PATRIOT ACT) ont le droit de créer des malwares et autres chevaux de troie pour accéder aux ordinateurs de suspects de crimes graves (au moins terrorisme, peut-être pédophilie, mais je ne sais pas), la France en fabrique aussi, mais je ne sais pas si elle le fait déjà dans les affaires de terrorisme. Du coup, ces pays ont les moyens d'accéder a des iPhones, tant qu'ils ne s'y prennent pas mal.
- Deuxièmement, la NSA a été forcée de supprimer une base de données de conversations téléphoniques concernant des appels intra-États-Unis. D'où la nécessité pour eux d'obtenir un base de droit (jurisprudence ou autre) sur laquelle reposer.
- L'obtention d'une backdoor pour exploitation est donc importante, mais secondaire à mon avis.
L'enjeu est de taille comme je l'ai souligné un peu rudement tout à l'heure en proposant un autre titre à l'article contre le chiffrement. Si le gouvernement états-unien obtient une backdoor dans l'iPhone, il y a tout d'abord un problème de sécurité, celui de la garder inexploitable pour quiconque, mais il est aussi clair que d'autres gouvernements vont faire pression pour obtenir des backdoors dans iOS. Clairement, je vois bien la France, la Chine, l'Iran, l'Allemagne en obtenir. Ça pose deux problèmes.
- Premièrement on peut imaginer que plusieurs gouvernements distincts aient accès au téléphones d'une seule personne. En ce qui me concerne, déjà que je n'ai pas très envie que le gouvernement français mette ses pattes dans mon smartphone, vous imaginez un gouvernement moins tolérant.
- Deuxièmement, il faut se mettre en tête que ce ne sera pas la faute d'Apple si un ressortissant de Hong Kong se fait dézinguer par le gouvernement chinois (au hasard) pour résistance. Parce qu'Apple aura fait son possible pour fournir du chiffrement.
Les autres aspects sont des questions de principe. Le vulgum pecus a-t-il le droit à du chiffrement de haute qualité ? C'est important parce que le chiffrement ne sert pas seulement à cacher des données, il comporte une partie authentification très importante. Par exemple votre navigateur reçoit des scripts JavaScript qu'il exécute. Il s'agit donc de code distant exécuté sur votre ordinateur. Il faut faire vraiment confiance à un tiers pour le laisser exécuter un programme dans votre ordinateur. Parce qu'il pourrait l'endommager, supprimer vos fichier, mettre un malware etc. Du coup le HTTPS des sites webs empêchent la modification d'une page web lors du trajet vers votre ordinateur, en authentifiant la page. Ainsi sans chiffrement fort, on se retrouve à poil.
Le dernier argument est celui de la prospective : le chiffrement fort sur un système GNU/Linux est plus facile que sous Android/iOS à mon avis (même si j'utilise APG, qu'il y a CyanogenMod, etc., mais ce n'est pas très répandu), du coup savoir si la majorité a droit au chiffrement sur mobile est une décision importante maintenant, mais sur le long terme, je doute que l'interdiction du chiffrement soit viable, tout simplement parce que beaucoup d'algorithmes de chiffrement sont librement disponibles et améliorable sur internet.
On vit dans un monde avec du chiffrement. Le refuser ne peut donc qu'être une solution temporaire, qui nuirait pas mal à l'utilisateur.
Sur ce, je vous laisse méditer, mettre des questions ou remarques en commentaire, et aller vous faire votre propre opinion sur ce débat. Il me paraît essentiel qu'on ait ce débat, et qu'on n'ait pas la naïveté de cette image :

parce que si on ne fait rien, une décision sera prise, sans nous.
Bonne journée !
Motius
PS : toute dernière remarque : Apple peut vouloir viser un marché aimant avoir de la vie privée, au contraire de ce que Microsoft fait actuellement...
PPS : merci à Nyx qui m'a fourni l'image de couverture !
]]>Juste une petite astuce que des collègues m'ont montré. Ça vous sauvera pas forcément la vie mais c'est assez cool pour en faire un petit billet.
Il s'agit de la possibilité d'afficher la météo dans son terminal comme un patron. Il s'agit d'un site web qui se charge de ça : wttr.in qui affiche une page en ascii art.
Pour l'avoir directement dans votre terminal, utilisez tout simplement le programme curl :
curl wttr.inEt voilà le résultat :
La localisation est trouvée automatiquement à l'aide de l'IP. Si vous souhaitez voir la météo d'une ville, par exemple Paris, procédez comme il suit :
curl wttr.in/parisEt si vous aimez vraiment, vous pouvez l'ajouter à votre fichier .bashrc afin d'avoir la météo à chaque nouveau terminal.
Voilà, bonne journée !
]]>J'estime qu'il est temps de faire un petit point sur la situation à Hashtagueule, d'autant que cela fait une éternité qu'on avait pas publié d'édito.
Commençons par les choses un peu moins gaies. Vous avez du vous rendre compte du peu de billets qui ont été publiés depuis quelques mois. Je n'ai même pas publié d'édito pour vous souhaiter une bonne année (que je vous souhaite donc maintenant). Il y a deux explications à cela. La première est celle d'usage, celle que nous avançons tout le temps : moi et motius avons tous les deux beaucoup de travail en dehors de notre activité sur le blog. Mais ce serait vous mentir que de vous dire que ce n'est que ça.
La seconde explication est tout simplement la baisse de l'enthousiasme de l'équipe, qui n'est pour le moment constituée que de deux personnes. Je ne vais pas rentrer dans les affaires internes, mais disons que nous attendions beaucoup de nos amis pour venir prendre part avec nous à l'aventure, et beaucoup se sont montrés intéressés et n'ont par la suite donné aucune nouvelle. Nous avons également parfois l'impression d'écrire nos articles dans le vent, nous avons très peu de retour de votre part, vous les lecteurs.
Cependant, nous savons que le site est de temps en temps visité, comme en témoigne l’anecdote suivante : Dans mon tutoriel Let's Encrypt, j'avais fourni un script qui envoyait automatiquement un mail à l'administrateur du succès de l'opération, et j'avais laissé ma propre adresse. J'ai ainsi reçu avec amusement une série de mails de notifications émanant de serveurs dont les administrateurs avaient oublié de modifier cette adresse. Je n'en veux bien sûr à personne, cela rassure un peu sur la fréquentation du site.
Mais pour le reste, dans l'ensemble, nous avons souvent l'impression de nous entêter à nous donner beaucoup de mal pour finalement pas grand chose. Nous nous investissons énormément, intellectuellement et même un peu financièrement, pour essayer de fournir une expérience certes pas parfaite ni professionnelle, mais la meilleure que nous pouvons. Je pense d'ailleurs qu'il s'agit de l'originalité du blog, si tant est qu'elle existe, car même si nous avons une certaine connaissance préliminaire du terrain et avons quelques prédispositions, nous découvrons le monde, aussi dur soit-il, et ses nouveautés, nous nous y adaptons, nous y faisons face et nous apprenons en même temps et au même niveau que vous, chers lecteurs, car nous savons que nous sommes logés à la même enseigne. Nous avons donc beaucoup misé sur l'interaction du site avec ses lecteurs, car nous n'aspirons pas à être meilleurs que vous. Nous savons que des gens beaucoup plus doués que nous sont amenés (avec un peu de chance) à tomber sur ce site. Nous voulons simplement partager notre vécu et que vous partagiez le votre entre vous. C'est en partageant et en nous entraidant que nous parviendrons à changer le monde.
Vous pouvez nous être d'une grande aide en nous faisant voir que vous êtes présents. Nous ne pouvons que vous encourager à parler de nous aux alentours, spécialement aux personnes à qui nous pourrions être utiles. Si vous aimez notre contenu, si vous ne l'aimez pas, si vous estimez que nous faisons des erreurs ou si vous voulez simplement passer dire bonjour, nous adorerions avoir de vos nouvelles, que ce soit dans les commentaires, sur IRC ou sur notre nouveau pod Diaspora, dont je parlerai dans la suite. N'hésitez pas à venir nous parler, nous féliciter, nous enguirlander, débattre, discuter. Nous serons à votre écoute et il s'agit de notre unique motivation.
Au fait, motius me dit dans l'oreillette qu'il a une multitude d'articles en préparation dans sa besace :)
Maintenant, parlons des nouveautés. Nous hébergeons plusieurs nouveaux services, dont un raccourcisseur de liens (basé sur LSTU), une forge git (instance de Gogs) ainsi que, comme évoqué plus haut, un pod diaspora, un réseau social décentralisé. Vous êtes tous invités à utiliser ces services, tout le monde peut s'y inscrire.
En parlant de ça, GLaDOS, notre serveur nommé par nos soins, commence à tomber à genoux face à tant de services, il faut dire que nous avions choisi une dédibox d'entrée de gamme, chez la compagnie Online.net. Nous allons donc dans les jours qui suivent procéder à une migration (encore une) vers Marvin, un serveur plus puissant (et aussi plus cher), chez Kimsufi (par OVH), situé à Montréal au Québéc. Donc moins de soucis quant à la surveillance de masse :)
Voilà, c'est tout pour cet édito. Partagez votre savoir, faites des retours sur votre ressenti, et bien sûr, restez gentils.
]]>Le partage c'est quand même vachement utile, et grâce à notre despote adminsys en chef raspbeguy, on va pouvoir le faire ici ! En effet comme Hashtagueule dispose de son propre serveur git + interface web Gogs, on peut y mettre du code.
C'est ce que j'ai fait là, qui sera un dépôt public de codes en tout genre. À ce jour, il y a :
- mon fichier /etc/hosts des serveurs auxquels je ne veux pas que mon ordinateur puisse se connecter. Sous windows, il s'agit du fichier %SystemRoot%\System32\drivers\etc\host.
- Un template pour mes rapports en LaTeX (et bientôt un autre pour les présentations, j'espère).
- Le fichier source Lilypond du premier mouvement du concerto italien de JS Bach, prêt à compiler avec la commande lilypond.
Petite explication avant de vous laisser : le fichier hosts est un fichier de résolution DNS statique. Par exemple si votre ordinateur veut se connecter à www.example.org, il faut en obtenir l'adresse IP. Cela passe par un mécanisme simple :
- résolution statique : mon ordinateur sait-il quelle est l'IP du serveur ?
- Est-ce dans le cache ?
- Est-ce dans le fichier hosts ?
- résolution dynamique : l'ordinateur va lancer des requêtes DNS :
- avec son propre serveur s'il en a un, et qu'il est prioritaire ;
- le serveur va effectuer les requêtes (où se trouvent les serveurs qui font autorité pour la zone org., où se trouve example.org., où se trouve www.example.org.).
- en demandant à un serveur DNS tiers (généralement celui de votre FAI, mais vous pouvez changer.)
- avec son propre serveur s'il en a un, et qu'il est prioritaire ;
Seulement voilà : si vous remplissez vous-même le fichier hosts avec des fausses info, ça ne va plus marcher très bien. Ici mon fichier hosts prétend connaître l'adresse d'environ 31000 serveurs sur "internet", et affirme que leur adresse est 0.0.0.0 (ou 127.0.0.1 en IPv4, ::1 ou ::0 en IPv6), qui n'est pas valide (au sens routage du terme, il s'agit d'une IP valide sans cela). Du coup votre ordinateur ne va tout simplement pas rechercher le bout de page web/service demandé. S'il s'agit d'une ressource que vous voulez, c'est dommage, mais s'il s'agit d'un site hébergeant --- au hasard --- des malwares/de la pub/des trackers ? Ça allège la navigation.
N'hésitez pas à commenter, à linker vers des ressources utiles, à vous abonner à notre flux RSS (on ne polluposte pas trop, vous le voyez). À bientôt !
Motius
]]>Framasoft est connue pour sa campagne Dégooglisons Internet et les outils alternatifs qu'elle promeut face aux grandes sociétés centralisatrices, le fameux GAFAM (Google Apple Facebook Amazon Microsoft). On peut ainsi utiliser Framapad et Framacalc à la place des Google Docs, Framasphère à la place de Facebook (à ce propos, vous pouvez vous inscrire sur notre pod Diaspora, la même plateforme utilisée par Framasphère, et vous pouvez m'y suivre).
Une nouvelle aire
Framasoft est passée à la vitesse supérieure. J'entends par là que Framasoft prend du recul et se remet elle-même en question, refusant de devenir une grande usine à gaz centralisatrice comme celles qu'elle combat depuis sa création. En effet, c'est ce qui arriverait si les services hébergés par Framasoft avaient "trop" de succès, c'est à dire s'ils devenaient des incontournable d'internet, en dépit des tentatives d'essaimage prôné par l'association.
Ainsi, CHATONS serait un regroupement d'hébergeurs indépendants adhérant à un manifeste et obéissant à une charte communes, basées sur la transparence, la communauté et la solidarité. Tout cela afin de maintenir la décentralisation, mutualiser le savoir et promouvoir ce genre d'initiative.
Framasoft tient à montrer sa volonté de rester un organisme parmi tant d'autres.
Précisons tout de suite qu’il ne s’agit pas d’un projet interne à Framasoft, même si c’est Framasoft qui l’impulse. Nous serons à terme un chaton parmi les autres.
Un chaton parmi les autres, c'est à dire les entreprises qui acceptent de se soumettre à des contraintes qui ne découlent pas forcément de source.
Tout le monde pourra être un chaton ?
Déjà, par "tout le monde", j'entends les hébergeurs manifestant un intérêt pour la décentralisation, la liberté des logiciels et/ou l'économie solidaire. Les potentiels intéressés se limitent à un ensemble assez restreint, et les particuliers ne pourront pas directement aspirer à devenir des chatons.
Certains points de la charte (encore largement en construction) de cet organisme peuvent mettre un frein à l'enthousiasme de certaines entreprises/association de l'hébergement informatique. Même si on peut avoir d'autres points de vue que lui, je vous invite à lire les remarques de Philippe Scoffoni à ce sujet, qui contiennent beaucoup de points intéressants et qui ne manqueront pas d'être abordés lors des négociations ultérieures. Soulignons les obligations imposées par la charte sur la transparence des comptes financiers, la participation de la communauté au maintiens des services. Certains organismes peuvent être amenés à dissimuler le plus possible leurs stratégies financières pour des raisons de compétitivité, et il est difficilement envisageable que n'importe quel client/adhérent d'une société/association puisse avoir des responsabilités dans des domaines sensibles et capitaux qui nécessitent le plus souvent au moins un minimum d'expertise et de confiance.
Cependant il s'agit d'un idéal (je n'emploie volontairement pas le terme "utopie"), un but vers lequel il nous faut tendre à défaut de jamais l'atteindre un jour. Même si ce collectif reste rachitique ou si des concessions sont accordées, à choisir, ce collectif mérite d'être tenté plutôt que de ne jamais voir le jour.
Saluons donc ce genre d'initiative et prenons exemple sur Framasoft. Et de conclure sur le slogan de l'association particulièrement judicieux : "la route est longue, mais la voie est libre".
]]>Je vous propose de continuer la série de tutoriels commencés ici et là sur le logiciel de partitions de musique Lilypond.
Clairement le but sera moins les bases de Lilypond, que je crois avoir pas mal abordé, mais plutôt tous les petits bidouillages que j'ai fait pour améliorer la disposition des notes sur une partition lorsque la configuration par défaut était imparfaite. Ça vous permettra de commencer à faire des recherches sur la documentation et les exemples de Lilypond.
On va tout d'abord commencer en parlant de la structure d'une partition, je serai assez bref là-dessus, puisque Lilypond permet de faire une quantité de partitions invraisemblables, et que je n'écris pratiquement que des partitions pour piano, ou presque.
Des structures Lilypond
Vous vous rappelez surement le début où l'on faisait des fichiers ly aussi petits que ça :
{
a c e
}eh bien c'était non seulement grâce aux très nombreuses valeurs par défaut de Lilypond, mais aussi parce que Lilypond voit une unique chaîne de musique et sait "dans quel ordre" la traiter, et "où" la placer. En effet si vous voulez écrire une partita à 6 mouvements et deux portées, il n'est plus possible de savoir quoi mettre où. Donc il va falloir l'expliquer à Lilypond. Et pour ça, il y a plusieurs solutions.
- Utiliser des templates.
- Bidouiller justqu'à ce que "ça marche".
- Utiliser l'assistant de création de partition de Frescobaldi.
Prenons un exemple créé avec Frescobaldi :
\version "2.18.2" % header version
\header {
dedication = "ma dédicace"
title = "le Titre"
subtitle = "ss titre"
subsubtitle = "le ssss titre"
instrument = "l'instrument"
composer = "le compositeur"
arranger = "l'arrangeur"
poet = "le parolier"
meter = "Symphonia"
piece = "Andantino"
opus = "D959"
copyright = "GNU GPLv3"
tagline = "Le site des gentis du net"
} % header global
global = {
\key f \minor
\time 2/2
\partial 8.
\tempo "Andante"
} % header pour les trois portées
right = \relative c'' {
\global
% En avant la musique !
} % portée supérieure piano
left = \relative c' {
\global
% En avant la musique !
} % portée inférieure piano
sopranoVoice = \relative c'' {
\global
\dynamicUp
% En avant la musique !
} % voix de soprane
verse = \lyricmode {
% Ajouter ici des paroles.
} % paroles pour la soprane
pianoPart = \new PianoStaff \with {
instrumentName = "Piano"
} << \new Staff = "right" \with { midiInstrument = "acoustic grand" } \right \new Staff = "left" \with { midiInstrument = "acoustic grand" } { \clef bass \left } >>
% utilisation des variables \right et \left pour créer la ligne piano
sopranoVoicePart = \new Staff \with {
instrumentName = "Soprano"
midiInstrument = "choir aahs"
} { \sopranoVoice }
\addlyrics { \verse }
% utilisation des variables \sopranoVoice et \verse pour créer la ligne de la soprane
\score {
<< \pianoPart \sopranoVoicePart >> % assemblage dans la partition score
\layout { }
\midi {
\context {
\Score
tempoWholesPerMinute = #(ly:make-moment 81 2)
}
}
}En rajoutant des notes et des paroles on obtient :

Partition exemple. Piano et voix de Soprane.
Problèmes rencontrés et leurs solutions
Forcer le retour à la ligne
Il suffit d'utiliser la commande \break au niveau d'une barre de mesure.
Je vous recommande d'écrire les barre de mesures de manière explicite (elles existent de manière implicite) car ça permet de corriger beaucoup d'erreur --- grâce au "barcheck", et permet de relire son code plus facilement.
Hampe (Stem)
La hampe est généralement liée à la voix s'il y en a plusieurs, voiceOne et voiceThree sont par défaut vers le haut (mais pas toujours) et voice To et voiceFour vers le bas. S'il n'y a qu'une seule voix, Lilypond choisit en fonction de la hauteur de la note.
Parfois la hampe de la note (Stem en anglais) est dirigée vers le haut et vous la voudriez vers le bas ou vice versa. Il y a pour cela une comande très simple : \stemUp pour forcer les hampes vers le haut, \stemDown pour les forcer vers le bas, \stemNeutral pour laisser de nouveau le choix à Lilypond.
On peut aussi rendre la hampe transparent à l'aide de :
\once \override Stem.transparent = ##t.
noire avec une hampe transparente.
Silence transparent
Il peut vous arriver de vouloir effacer les silences, on le fait avec la commande : \override Staff.Rest.transparent = ##t, et pour n'en effacer qu'un : \once \override Staff.Rest.transparent = ##t.
Décaler une ligature
Si vous voulez déplacer une ligature logique (Tie, indiquée par le symbole ~ après la note) on peut le faire à l'aide de la commande : \once \override Tie.extra-offset = #'(0.1 . -0.1) par exemple :

ligature normale
devient :

ligature décalée en hauteur et en largeur
(ici ce n'était pas très utile, je l'admets...)
De la même façon que la hampe, on peut forcer une ligature vers le haut ou vers le bas avec \tieUp \tieDown, et remettre le défaut avec \tieNeutral.
Décaler une note horizontalement
Par défaut, les voix 3 et 4 (voiceThree et voiceFour) sont décalées par rapport aux voix une et deux. C'est sympa la majorité du temps, mais parfois (lorsqu'on fait des accord, par exemple, afin d'avoir les notes alignées). On peut le faire à l'aide de la commande suivante : \once \override NoteColumn.force-hshift = 0.
Trille prolongé
On peut spécifier un trille avec \trill après la note sur lequel le trille s'applique.
Pour faire un trille prolongé, on indique le début avec \startTrillSpan et on le termine avec \stopTrillSpan.
Pour spécifier une altération sur le trille, on utilise \pitchedTrill.
Texte sur la partition
On peut utiliser \markup{} pour afficher du texte. Par exemple : c4^\markup{\italic{mezzo forte}} affiche mezzo forte en italic au dessus de la note, et c4_\markup{\italic{mezzo forte}} l'affiche en dessous.
 markup mezzo forte en italic en haut, piano en italic en bas
markup mezzo forte en italic en haut, piano en italic en bas
Accords en arpèges
Pour afficher un arpège, on utilise \arpegio. Pour préciser explicitement si l'accord est de haut en bas, on utilise \arpeggioArrowUp, qu'on termine avec \arpeggioNormal. Pour aller de haut en bas, on utilise \arpeggioArrowDown.
Voilà, c'est tout pour ce troisième petit tour dans Lilypond, je suppose qu'il va falloir attendre que j'écrive des partitions vraiment complexes pour en écrire un troisième ;). Bonne journée à tous !
Motius
]]>Mais tout d’abord, je vous souhaite à tous une bonne année 211 - 25 ! Au niveau personnel, je vous souhaite tout le bonheur que vous méritez, tant sur le plan professionnel/scolaire qu'avec votre famille/amis/béguin divers. Instruisez-vous, soyez curieux, incitez vos proches à la sagesse, et bien sûr, restez vous-même gentils.
Au niveau citoyen, je souhaite comme toujours une prise de conscience collective sur cette cage en or qu'est devenue aujourd'hui la vie sur les internets, et une plus grande sagesse de nos têtes décideuses (à défaut d'être pensantes) à propos de la réalité numérique, qu'elles n'ont toujours pas bien intégrée.
Enfin, revenons à notre tutoriel. Au cours du mois dernier, vous l'avez peut-être remarqué, le certificat de notre blog (ainsi que les certificats de nos services internes, mais ça c'est nos oignons) ont changé d'autorité de certification. Nous sommes passés d'un certificat Gandi, offert avec notre nom de domaine, à un certificat Let's Encrypt, grâce à l'ouverture de ce service en bêta publique. Pourquoi avons-nous changé ? Et bien, d'abord, depuis le temps que nous vous en parlions, il aurait été ironique que nous n'utilisions pas le système Let's Encrypt. Ensuite, cette manière de procéder n'est pas sans avantages pour un administrateur système, principalement pour les raisons suivantes :
- Gain de temps global, même pour la première utilisation ;
- Possibilité de créer un seul certificat pour plusieurs domaines ;
- Automatisation très poussée des différentes étapes, permettant l'écriture de scripts pour les renouvèlements.
J'avoue qu'avant la bêta publique et la possibilité de mettre vraiment les mains dans le cambouis, je n'avais aucune idée du fonctionnement, même basique, de ce service. Je n'ai même jamais personnellement manifesté d'attirance particulière envers les technologies de sécurité. En fait, son fonctionnement théorique est très simple, et permet même, à mon sens, de se rendre bien compte du processus de certification SSL dans sa globalité.
Principe de la vérification d'identité
Lors de la création d'un certificat, on doit suivre un protocole invariant de l'autorité de certification :
- On crée une clef secrète (ou on utilise une clef générée antérieurement).
- À partir de cette clef secrète, on génère une demande de certification (contenant une clef publique et des informations sur l'identité de l'entité à certifier).
- On soumet cette demande à l'autorité de certification désirée, qui génère et signe un certificat, ce qui dit aux outils des utilisateurs de votre service qu'il s'agit bien de vous, car il fait confiance à l'autorité de certification.
Les deux premières étapes sont instantanées ; cependant, la dernière étape prends traditionnellement plus de temps, car l'autorité de certification doit s'assurer de l'identité du domaine qu'elle doit certifier. Chez les autorités classiques, il s'agit souvent de fournir des pièces d'identités, ou de répondre à un mail auquel seul le possesseur du domaine peut accéder (du type [email protected]).
Let's Encrypt prends en charge ces 3 étapes (il faut reconnaitre que c'est très facile d'automatiser les 2 premières) en passant par un utilitaire chargé de communiquer avec le serveur de son autorité de certification.
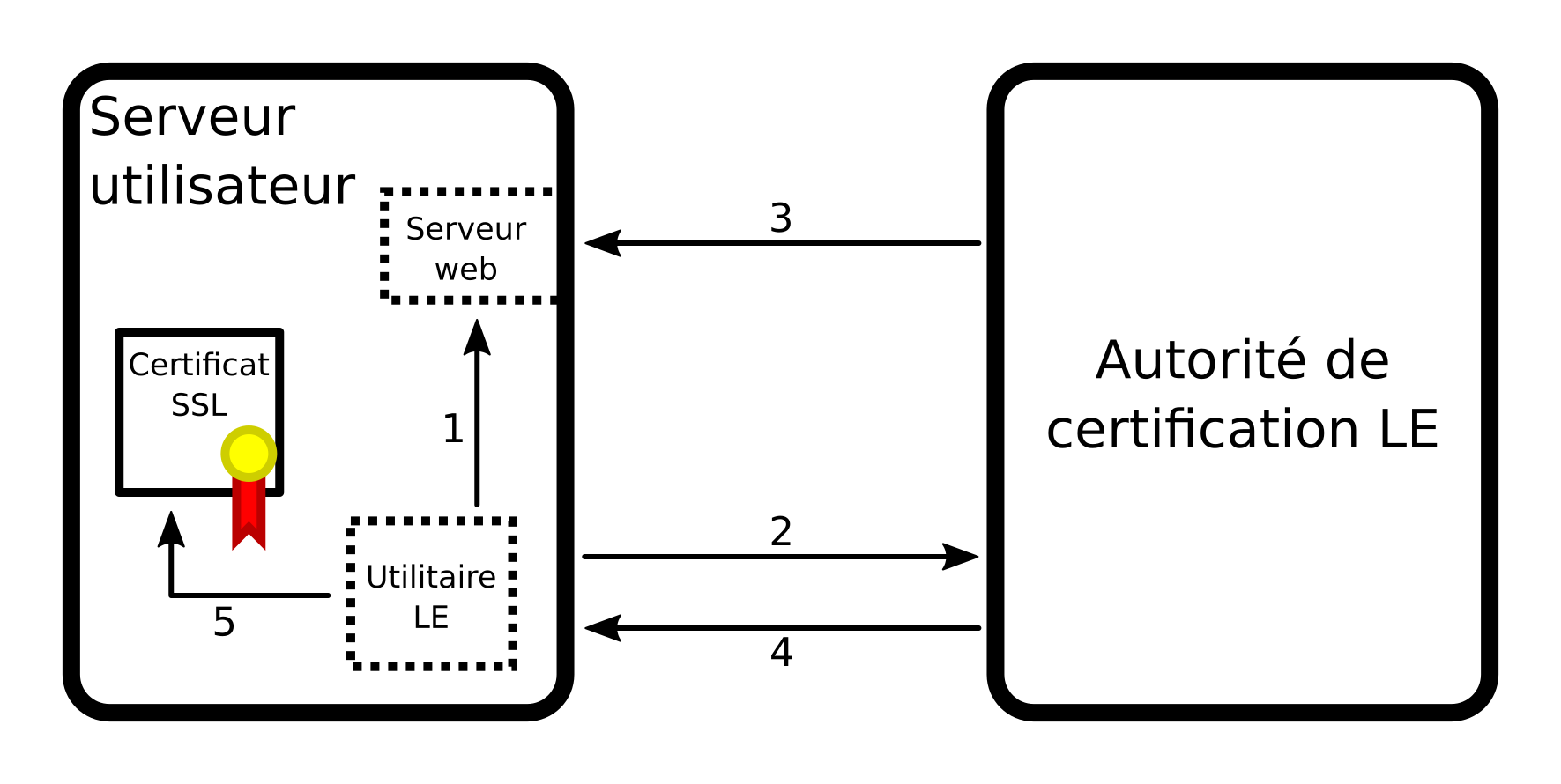
Processus de vérification d'identité
- Une fois la clef et la demande de certificat générées, l'exécutable local communique au serveur http un code de vérification à rendre accessible par le serveur de certification.
- L'utilitaire demande à l'autorité de certification de procéder à une vérification d'identité en envoyant la demande de certificat et lui communique le code servi par le serveur http à tester.
- Le serveur de certification accède au serveur http en utilisant le système DNS
- L'autorité de certification accepte l'identité et transfert le certificat.
- L'utilitaire met le certificat généré à disposition des services de l’utilisateur.
Ainsi, le processus de création du certificat ne prends en tout et pour tout que quelques dizaines de secondes. Cependant, par cette méthode, on est contraint de mettre en service, au moins temporairement, un service web pour chaque domaine à tester, ce qui est gênant pour des domaines qui ne sont pas destinés à pointer sur un site web.
Configurer son serveur web
Let's Encrypt met à disposition des "extensions" lui permettant de communiquer tout seul au serveur web les informations pour l'étape de la vérification d'identité. Cependant, j'utilise Nginx, et à ce jour seul Apache dispose d'une extension stable. Il existe une extension expérimentale pour Nginx mais je n'ai pas su m'en servir convenablement, ou alors j'ai eu la flemme de comprendre comment elle marchait. De toute façon, selon les retours utilisateurs et les forums, la méthode générique (dite du webroot) est la plus utilisée, c'est donc celle qui sera présentée, et vous verrez, ce ne sera pas bien compliqué.
Tout d'abord, il faut définir le dossier qui sera mis à disposition par le serveur web. Par exemple, pour pouvez créer et choisir l'emplacement /var/www/webrootauth.
Vous devez ensuite modifier la configuration de chaque domaine que vous souhaitez faire certifier. Vous avez le droit à 100 domaines couverts par votre certificat, vous avez donc de la marge, et vous auriez tort de vous priver. Sous Nginx, vous devez ajouter au sein de chaque server block :
location ~ ^/.well-known/acme-challenge(/.*)?$ {
root /var/www/webrootauth;
default_type text/plain;
}Sans oublier de recharger Nginx :
service nginx restartou bien, selon votre distribution Linux :
systemctl restart nginxPour information, cela demande à Nginx de servir le contenu de /var/www/webrootauth à l'adresse http://example.com/.well-known/acme-challenge/, adresse qui sela utilisée par l'autorité de certification.
Installer l'utilitaire
EDIT : C'était prévisible, maintenant quelques distributions intègrent Let's Encrypt dans leurs dépôts. Cette méthode est donc à privilégier par rapport à la méthode ci dessous.
Il faut maintenant télécharger l'exécutable mis à disposition par Let's Encrypt. Pour cela, vous allez avoir besoin de Git, veillez donc à ce qu'il soit installé sur votre machine.
Devenez super-utilisateur :
sudo su -Puis clonez le dépôt du projet :
git clone https://github.com/letsencrypt/letsencrypt /root/letsencryptConfigurer Let's Encrypt
Il est possible d'exécuter Let's Encrypt à la sauvage sans fichier de configuration, uniquement avec des paramètres long comme mon bras. Il est néanmoins plus propre d'écrire son fichier de configuration, cela donne des scripts plus propres et un historique bash plus clair. Et comme ça vous n'avez pas des tonnes de lignes de commandes à retenir en cas de perte de vos scripts :)
Un fichier de configuration Lets Encrypt ressemble à ceci :
rsa-key-size = 4096
server = https://acme-v01.api.letsencrypt.org/directory
email = [email protected]
authenticator = webroot
webroot-path = /var/www/webrootauth
text = True
renew-by-default = True
agree-tos = True
domains = hashtagueule.fr,mail.hashtagueule.fr,wiki.hashtagueule.fr,mysql.hashtagueule.fr,znc.hashtagueule.fr,ttrss.hashtagueule.frPetite explication :
rsa-key-size: la taille de la clef, on l'a mis au maximum, parce qu'on est des gros bourrins. Sachez que la génération d'une clef 4096 bits prends plus de temps, mais elle n'est générée qu'à la première exécution.server: l'adresse du serveur de certification. Ça ne sert à rien de le changer.email: l'adresse e-mail de votre compte Let's Encrypt (s'il n'existe pas, il sera créé automatiquement, pas d’inquiétude).authenticator: la méthode de vérification d'identité, on a dit qu'on choisissait la méthode webroot.webroot-path: doit correspondre au chemin choisi précédemment.text: indique que l'on souhaite exécuter l'outil en lignes de commandes, pratique pour les scripts et permet de tout exécuter sans intéraction (un mode pseudo-graphique existe mais n'est pas pratique).renew-by-default: indique que les certificats existants doivent être renouvelés.agree-tos: indique que vous acceptez la paperasse lié à l'utilisation des certificats, à lire quelque part sur leur site, mais bon, rien de bien méchant.domains: là, vous devez indiquer tous les domaines que doit couvrir le certificat qui va être généré, séparés par une virgule.
Vous placerez ce fichier quelque part d'accessible. Par exemple, vous pouvez le placer dans /root/le-config/cli.ini.
Générer ponctuellement le certificat
Tout est en place pour la génération de votre premier certificat, la tension monte, je vous sens tout excité. Allez, lancez-vous, en voiture Simone. Pour générer votre certificat, en tant que super-utilisateur, exécutez la commande suivante :
/root/letsencrypt/letsencrypt-auto certonly --config /root/le-config/cli.iniLaissez mijoter quelques instants. La première fois, des dépendances nécessaires vont s'installer, il va configurer deux trois trucs, et finalement faire le boulot.
Normalement, à la fin, vous allez avoir un message vous félicitant du succès de l'opération. Bravo, vous avez un certificat Let's Encrypt :)
Vous pourrez ensuite configurer votre serveur web pour utiliser ce certificat. Sous Nginx, vous préciserez dans vos server blocks :
listen 443;
listen [::]:443;
ssl on;
ssl_certificate /etc/letsencrypt/live/hashtagueule.fr/fullchain.pem;
ssl_certificate\_key /etc/letsencrypt/live/hashtagueule.fr/privkey.pem;Bien sûr, vous remplacerez hashtagueule.fr par le nom de votre domaine principal. Vérifiez en regardant le nom du dossier à cet emplacement.
Vous pouvez ensuite recharger Nginx, et si tout ce passe bien, vous avez un site sécurisé Let's Encrypt.
Renouvellement automatique
Les certificats générés par Let's Encrypt ont une validité de 90 jours. C'est court, et c'est un fil à la patte de devoir tous les 3 mois demander un renouvellement de certificat. Heureusement, il y a Cron.
Cron est un service sur votre machine qui va se charger d'exécuter des tâches à intervalle régulier. Tous ce que vous avez à faire, c'est d'écrire un script à fournir à cron. Ce script ressemblera à ça :
#!/bin/bash
la_cert_dir=/etc/letsencrypt/live/hashtagueule.fr
/root/letsencrypt/letsencrypt-auto certonly --config /root/le-config/cli.ini 1> /dev/null
# nginx
service nginx reload
# Vous pouvez également scripter les opération à suivre
# pour d'autres services, par exemple votre serveur mail.
# Envoi d'un mail de notification à l'administrateur
mail -a "From: Agent de certification Hashtagueule <[email protected]>" -a "Content-Type: text/plain; charset=UTF-8" -s "Renouvellement des certificats" [email protected] << EOF
Bonjour,
Le certificat des services Hashtagueule a été renouvelé et couvre actuellement les domaines suivants :
$(openssl x509 -in /etc/letsencrypt/live/hashtagueule.fr/cert.pem -noout -text | grep DNS | sed 's/, /\n/g' | cut -d: -f2)
Dates de validité :
$(openssl x509 -in /etc/letsencrypt/live/hashtagueule.fr/cert.pem -dates -noout | cut -d= -f2)
Pour rappel, les certificats délivrés par Let's Encrypt ont toujours une validité de 3 mois. Tâchez donc de définir une période de renouvellement inférieure à cette durée.
Il est à noter également que l'autorité Let's Encrypt ne délivre qu'un maximum de 5 certificats pour le même domaine par semaine. Renouvelez donc avec précaution.
Bonne journée.
EOFCe script va renouveler le certificat et vous envoyer un mail de notification comportant les nouvelles dates de validité et les domaines concernés. Classe, non ?
Il vous reste à rendre ce script exécutable et à le placer dans /etc/cron.monthly afin de l'exécuter tous les mois.
Limitations
Comme indiqué précédemment, les domaines à certifier doivent être servis par un serveur web, au moins pour la durée de la vérification d'identité.
D'autre part, évitez de générer trop de certificats, car vous êtes limités à 5 renouvèlements par semaine. En régime permanent ça ne pose pas de problème, mais je me suis déjà fait avoir lors de mes tests...
Voilà, j'espère que ce tutoriel vous aura été utile, et j'espère aussi voir fleurir une multitude de sites sécurisés.
Désormais, vous n'avez plus aucune excuse.
]]>La veille, le compte Twitter de Murdock (désormais suppprimé) avait publié des messages plus qu'étranges, à propos d'une persécution abusive policière, et de son intention de se suicider (ces messages peuvent être retrouvés ici).
Le caractère erratique de ces messages peut laisser à penser à un piratage du compte de Murdock, hypothèse assez peu probable, en considérant que ce dernier est aujourd'hui décédé. Si ces messages émanent bien de Murdock, alors il a écrit ses dernières lignes dans l'urgence et la détresse la plus totale. Par ailleurs, il explique qu'il souhaite coucher le récit complet de sa mésaventure sur son blog avant de se donner la mort, chose qu'il n'a pas faite, soit par changement d'avis, soit parce qu'il a été tué avant de pouvoir le faire.
Dans tous les cas, il s'agit d'une fin prématurée et regrettable pour cet acteur majeur de la communauté du libre, le père de l'une des premières distributions Linux et des plus utilisées dans le monde, pour ne pas dire la plus populaire.
]]>J'espère que vous avez passé de très bonnes fêtes, je suis désolé de ne pas avoir écrit plus tôt, il y a pourtant deux autres articles en préparation mais voilà, on aime tous passer du temps en famille, et puis le boulot ça occupe, mine de rien.
J'ai déjà dû vous parler de l'EFF à plusieurs reprises, et aujourd'hui, --- enfin il y a une semaine --- l'EFF a mis à jour son panopticlick. Petit tour des nouveautés.
Si vous ne connaissez pas l'EFF ni son outil panopticlick, sachez que le premier est une organisation de défense des libertés sur internet (c'est-à-dire des libertés, faut dire les choses telles qu'elles sont), et l'"outil" panopticlick est une page web qui à l'origine utilisait des programmes glanés sur le web pour identifier un navigateur web de manière unique.
Pour ce faire, les outils permettaient de trouver plein d'info à propos du navigateur, comme par exemple :
- s'il accepte les cookies (peu d'infomation) ;
- la résolution de l'écran (pas mal d'information, y'a beaucoup de tailles d'écran différentes) et profondeur de couleur ;
- quels plugins et extensions sont installés sur votre navigateur (Flash, Java, GNOME shell, etc...)
- zone géographique ;
- langue et pays (fr_FR, en_US...) ;
- type de navigateur (Firefox, Chromium, Lynx, Elinks, W3m, Opéra, Chrome, etc...) ;
- version du navigateur web ;
- système d'exploitation.
Avec la version 2, l'EFF va d'abord tester si votre navigateur web bloque les publicités qui vous épient. Ça ressemble à ça :

Test de mon firefox en navigation privée. Chromium en incognito donne à peu près le même résultat.
Donc là mes navigateurs bloquent les publicités intrusives, mais ils sont identifiables. Le seul navigateur non identifiable que je connaisse est le Tor Browser.
N'hésitez pas à partager le lien vers panopticlick (et cet article ;)) puisque plus l'EFF fait de tests et mieux elle peut dire si un navigateur web apparaît unique ou non.
Bonne journée et encore bonnes fêtes !
Motius
]]>Appréciez.
]]>Si je vous parle de ça, déjà c'est parce que c'est cool. C'est plein d'humour, de sarcasme, parfois même d'humour noir, de réflexions philosophiques. Comme on dit, ça sent le vécu.
Mais, plus dans l'auteur a sorti un livre expliquant pas mal de faits scientifiques et de trucs techniques avec des schémas et textes simples, et il est tellement content de son bouquin qu'il a publié un petit jeu dans l'univers de ses dessins. Le principe est simple, à l'image des épisodes.
À première vue le jeu est d'un ennui mortel, il s'agit de récupérer des pièces sur une carte grosse comme une carte de visite. Cependant, on se rends vite compte qu'il est possible, et c'est là l'attrait de la chose, de s'échapper de cette zone de jeu, et de débouler sur une carte gigantesque. Vraiment gigantesque. Bourrée d'easter eggs et de références en tout genre, films, séries, cartoons...
Enfin bref, je vous laisse le découvrir. Nous, on a pas encore fini de tout explorer.
]]>Aujourd'hui on va détailler une pratique très courante pour le débug réseau, la compréhension de la pile TCP/IP et les mécanismes d'organisation des machines sur le réseau IP, ainsi que pour les interceptions et écoutes du trafic sur internet : le sniffage.
Le sniffage, qu'est-ce que c'est ?
Sniffer le réseau
Eh bien c'est une pratique très simple qui consiste à faire une capture et une copie des paquets et autres trames qu'on voit passer. Évidemment, c'est très différent si vous faites ça chez vous ou bien si c'est un fournisseur d'accès internet (FAI) qui fait ça sur un routeur de collecte. Donc restez dans la légalité (et n'oubliez pas d'être gentils ;)) : exercez-vous sur votre propre réseau local ! Ça fait moins de paquets --- quoique toujours pas mal --- et aussi moins d'ennuis.
C'est ce qu'on va faire dans la suite.
Quels logiciels ?
Eh bien il y a un super logiciel libre (en GPLv2 pour la majorité des sources) qui fait tout ça très bien : il s'agit de Wireshark. Si vous êtes sous Debian/Ubuntu, vous pouvez l'installer à l'aide de la commande :
sudo apt install wireshark tcpdumpou
sudo apt-get install wireshark tcpdumpsi votre Debian/Ubuntu n'est pas récente. Sur une distribution type CentOS/Fedora/Red Hat il faut utiliser yum. Vous pouvez aussi récupérer les sources et les recompiler.
Je vous ai aussi fait installer tcpdump. Il aurait été installé quand même par résolution de dépendances, mais je tenais à le marquer pour que vous sachiez que c'est tcpdump qui va effectuer la capture, tandis que Wireshark sert d'interface pour visualiser les paquets.
Lorsque vous le lancez, il ressemble à peu près à ça :
Wireshark thème dark sous Debian GNU/Linux 8, machine de test
Notez que les utilisateurs de Microsoft© Windows® peuvent aussi utiliser Wireshark, mais une partie de ce qui suit est pour les linuxiens.
Comment faire ?
Pour utiliser Wireshark il faut naturellement pouvoir capturer les paquets qui passent sur le réseau, et malheureusement, il s'agit d'un privilège réservé à root. Maintenant, vous pourriez lancer wireshark en tant que root, et l'utiliser tel quel, mais même si c'est à peu près ce que les utilisateurs font sous Windows (je ne connais pas le détail des droits et privilèges mis en œuvre), Wireshark gronde un peu sous GNU/Linux si vous faites ça. Je vous propose donc une autre méthode pour contourner ce problème.
Les capacité du kernel
Là on va aller à la limite de ma connaissance du noyau linux (aussi appelé kernel, les mathématiciens n'auront pas de problème à utiliser les deux termes) avec la notion de capacité.
Normalement vous avez installé les commandes getcap et setcap que root peut utiliser. Elles se trouvent dans le paquet libpcap2-bin, comme en témoigne la commande :
dpkg -S getcapqui permet de chercher dans quel paquet se trouve la commande getcap.
Donc les commandes getcap et setcap permettent respectivement de voir et modifier les capacités d'un binaire sur le noyau linux. Il faut donc faire attention à ce que vous faites, mais il n'y aura aucun problème puisque les opérations sont réversibles, et que je mettrai un petit script exécutable par root pour gérer tout ça automatiquement.
GetCap, SetCap
Je suppose que vous êtes devenu root, soit avec la commande su, si vous connaissez la phrase de passe root, soit avec sudo su et votre phrase de passe, si vous êtes un sudoer. Voilà les fameuses commandes tant attendues :
getcap /usr/sbin/tcpdumppermet de voir les capacités du binaire tcpdump qui est dans /usr/sbin/.
Le binaire tcpdump a besoin des capacités suivantes pour fonctionner en utilisateur simple :
setcap cap_net_admin,cap_net_raw+eip /usr/sbin/tcpdumpVoilà, le binaire a les bonnes capacités.
Pour deux types de capacités :
- cap_net_admin
- cap_net_raw
on a donné les attributs suivants :
- e : effective
- p : permitted
- i : inheritable
Si vous avez fait une bêtise, la commande setcap -r <binaire> permet de retirer les capacités attribuées.
Mais attention ! Ce n'est pas tout !
Droits UNIX
Le binaire tcpdump est dans /usr/sbin et c'est normal, puisqu'il ne devrait être exécuté que par root par défaut. On va donc faire en sorte d'avoir une configuration optimale.
Pour pouvoir lancer le binaire, il faut pouvoir l'exécuter. tcpdump appartient à root:root, et a les droits UNIX suivants : -rwxr-xr-x ce qui veut dire que n'importe qui peut faire de la capture réseau ! Eh oui, il est exécutable par o=other. Changeons ça immédiatement à l'aide de la commande :
chmod 754 /usr/sbin/tcpdumpDonc root peut lire-écrire-exécuter le binaire, les personnes dans le groupe root peuvent lire-exécuter le binaire, et les autres peuvent seulement le lire.
Personnellement, je n'aime pas mettre des gens dans le groupe root, donc on va en créer un autre, qu'on va appeler wireshark :
addgroup wiresharkSupposons que l'utilisateur qui va utiliser Wireshark/tcpdump ait le login UNIX toto. La commande
usermod -aG wireshark totopermet de mettre toto dans le groupe wireshark et
chown root:wireshark /usr/sbin/tcpdumppour mettre tcpdump dans le groupe wireshark.
Le PATH et /usr/sbin
Maintenant seul les membres du groupe wireshark (dont toto), et root peuvent utiliser le binaire tcpdump.
Le problème c'est que l'exécutable tcpdump est dans /usr/sbin, qui n'est pas dans le PATH de l'utilisateur toto. Il y a donc deux options, une mauvase et une bonne. La mauvaise, c'est de rajouter /usr/sbin au PATH de toto. La bonne, c'est de faire un lien symbolique de l'exécutable tcpdump vers /usr/local/bin à l'aide de la commande :
ln -s /usr/sbin/tcpdump /usr/local/bin/Ça n'est pas un problème en terme de sécurité puisqu'on s'est assurés que seuls les membres du groupe wireshark pouvaient exécuter tcpdump. Ça y est. toto peut utiliser tcpdump. À partir de maintenant, les commmandes ne sont plus exécutées en tant que root. Vous pouvez soit faire une capture simple que vous lisez avec un éditeur de texte (pas un traitement de texte !), l'avantage, c'est de pouvoir travailler sur des fichiers distants, l'inconvénient, c'est que vous ne pourrez pas utiliser Wireshark pour les visualiser. Utiliser la commande :
tcpdump -i wlan0si wlan0 est l'interface sur laquelle vous voulez capturer des paquets. Il s'agit chez moi de mon interface Wi-Fi. L'interface ethernet s'appelle souvent eth0. Utiliser Contrôle-C pour arrêter la capture. vous pouvez rediriger ça vers un ficher ainsi :
tcpdump -i lo > ./mes_paquets_captures(interface loopback, ici). Sinon utilisez la commande :
tcpdump -i eth0 -w ./mes_paquets_capturéspour capturer les paquets dans un format lisible pour Wireshark. Lancer Contrôle-C pour arrêter la capture.
Vos captures devraient ressembler à ceci :
Capture réseau avec tcpdump, machine de test.
Puis il vous suffit de lancer Wireshark, et d'ouvrir le fichier de capture (raccourci Contrôle-O).
Enfin les paquets vus avec Wireshark ressemblent à ça :
Paquets capturés avec tcpdump, puis chargés sous Wireshark. machine de test.
Le script !
Alors. Puisque vous avez été sages, je veux bien. Mais c'est vraiment pas grand chose. Je le mets là parce que j'ai ça dans mon /root/ pour rapidement permettre la capture puis la retirer :
Le script pour permettre la capture : enable_tcpdump.sh
#!/bin/bash
/sbin/setcap cap_net_admin,cap_net_raw+eip /usr/sbin/tcpdumpLe script pour l'empêcher : disable_tcpdump.sh
#!/bin/bash
/sbin/setcap -r /usr/sbin/tcpdumpLe script qui paramètre tout pour vous (à ne lancer qu'une fois, en tant que root) : setup_tcpdump.sh
#!/bin/bash
/usr/sbin/adduser toto
/usr/sbin/addgroup wireshark
/usr/sbin/usermod -aG wireshark toto
/bin/chmod 754 /usr/sbin/tcpdump
/bin/ln -s /usr/sbin/tcpdump /usr/local/bin/
/bin/chown root:wireshark /usr/sbin/tcpdumpVoilà. L'utilisateur toto (ou autre, si vous avez changé le script) peut facilement intercepter le trafic sur le réseau, à l'aide des deux scripts setup_tcpdump.sh et enable_tcpdump.sh.
Je ferai peut-être une suite où l'on étudiera plus avant les fonctionnalités de Wireshark plutôt que la seule mise en place de l'écoute réseau, en attendant bonne écoute !
Touitte de NSA_PR, 22 juillet 2014 ;)
Sur ce petit troll de la NSA, je vous quitte !
Motius
PS : pour réaliser ce tuto, je me suis inspiré de cette page de la doc. Je vous recommande d'aller voir la doc pour résoudre d'éventuels problèmes, et comprendre les valeurs affichées par Wireshark.
]]>Paris a été victime de 3 attentats simultanés aujourd'hui, à partir d'environ 21h, à l'heure actuelle on parle de 45-50 morts. Je ne rentre pas dans les détails, vous les aurez bien assez tôt.
Nous ne pouvons que déplorer les morts et les blessés, de manière générale les victimes de ces événements tragiques. Hashtagueule se joint à la douleur des concernés.
Peut-être est-il malvenu de faire la remarque tout de suite, mais celà n'annonce rien de bon concernant les lois de surveillance et la liberté du net en général. Mais c'est également la preuve que cette loi de renseignement toute fraîche, ainsi que ces mesures vigipirate n'ont pas été efficaces. Alors soit le gouvernement va encore endurcir ces mesures et ainsi contiuer sur sa voie, soit se remettre en question et envisager d'autres solution, peut-être qui nous conviennent à nous les gentils.
Allez, courage tout le monde, et plus que jamais, restez gentils.
P.S: Aujourd'hui c'était la journée de la gentillesse. Une journée qui fait aller dans le sens d'Hashtagueule. Triste cynisme.
]]>J'aimerai revenir sur une notion dont on a beaucoup parlé (au moins ici et là) et dont on parlera beaucoup encore, vu qu'il s'agit d'un pan important de ce pourquoi nous nous battons.
J'aimerais clarifier et élargir toutes les très jolies choses que l'on met derrière ce terme, et éviter qu'il continue de vous faire peur afin que vous puissiez enfin dormir enfin à peu près convenablement.
Ce que l'on vous a déjà dit
Comme a dû vous le dire Motius, le net d'aujourd'hui, ou du moins tel qu'il est en voie de devenir, est méchant. Enfin il n'est pas méchant, mais les gens qui ont la main dessus le sont. Où plutôt, rien ne peut les empêcher de l'être. Pourquoi ? Parce que ces acteurs du net détiennent un quasi-monopole des services qu'ils proposent, et pire encore, ils les accumulent. Désormais, les gens reposent leur entière activité internet sur deux ou trois sociétés, que ce soit pour les mails, les contacts, la communication instantanée, les réseaux sociaux... On a donc très peu de gros centres de services conséquents dans le monde. Mais ça vous le saviez déjà.
La décentralisation, au sens strict du terme, c'est la tendance à délaisser les centres des services au profit d'une répartition de la charge sur l'ensemble des utilisateurs de ce service. Cela passe par des protocoles spéciaux d'un type que l'on nomme pour l'occasion pair à pair, bien connu sous son nom anglais peer-to-peer. Mais ça, vous le saviez aussi.
L'intérêt du pair à pair, c'est que les utilisateurs du service ne sont plus dépendants de l'énorme araignée de la toile dans laquelle ils sont tenus prisonniers, mais de porter eux même les données ou de servir de point d'accès pour d'autres utilisateurs de ce même service. Donc plus il y a d'utilisateurs, plus le service est efficace, à l'opposé d'un service centralisé traditionnel (même si souvent les centres en question déploient des moyens colossaux et peuvent ainsi traiter beaucoup, beaucoup, mais genre vraiment beaucoup de demandes). De même, la censure d'un tel service est très difficile, car l'information est en elle-même insaisissable. Pour arrêter le service, il faut faire tomber un à un tous les pairs du service, et Dieu sait que parfois ça fait beaucoup. Ainsi il est impossible d'enrayer le téléchargement illégal du dernier Twilight en pair à pair, les autorités se réduisant à établir une liste des utilisateur du service afin de faire tomber le glaive impitoyable de la justice et de les châtier à grand coups de pied là ou je pense.
Rappelons que ces protocoles pair à pair ne sont pas illégaux, ce sont certains usages qui en sont fait qui le sont. On ne va pas interdire la gravité parce que la chute inattendue d'un rhinocéros du haut d'un immeuble sur la tête est potentiellement néfaste pour la santé du propriétaire de ladite tête (et pour le rhinocéros par la même occasion).

Principal responsable de l'interdiction totale de la gravité (décret de 2035).
Tout cela vous le saviez. En tout cas vous devriez le savoir. Bon de toute façon, maintenant vous le savez.
Mais...
Je pense que je dois partager mon ressenti sur cette philosophie de la décentralisation.
L’inconvénient du pair à pair, c'est que trop peu de protocoles l'utilisent, ce qui le réduit aujourd'hui à un usage très marginal, dont celui qui n'est pas apprécié par ces respectables personnes chez Hadopi. On a bien quelques tentatives de démocratisation de services tout public en pair à pair, mais ils ont pour le moins beaucoup de mal à percer. Cela soulève également le problème de la standardisation, qui pourrait faire l'objet d'une autre tribune.
D'autre part, cela induit une conception totalement différente des principes des internets que l'on croyais acquis, dont le sacrosaint concept d'architecture client-serveur. En pair à pair, ça change du tout au tout, car il n'y a alors que des utilisateurs qui jouent les deux rôles à la fois, dans une sorte d'orgie de l'information.
Alors que faire ? Doit-on se plier à la dictature des grands de ce monde qui abusent de nos données et dont nous sommes la matière première ? N'ayez crainte, nous sommes les Gentils du Net, et même si le moment venait un jour de rendre les armes et de courber l'échine devant le totalitarisme des sociétés gangster cannibales et sans pitié d'un monde impitoyable, dénué de liberté et d'utilité par le fait, ce jour n'est pas arrivé !
À mon sens, la solution idéale dans l'état actuel des choses, quitte à adopter la décentralisation totale plus tard, passe par un élargissement du sens de cette décentralisation. Plutôt que de renoncer aux centres de services, créons-en énormément ! Je m'explique : je pense qu'il est louable que créer les propres services que nous utilisons. C'est le principe de l'auto-hébergement : on n'est jamais mieux servi que par soi-même. Et cela a l'avantage de pouvoir facilement éditer un contenu que vous mettez à disposition, puisque tous les accès dépendent de vous.
Cette structure n'est pas sans rappeler les premier jours des internets, à l'époque ou vous aviez une multitude de concurrents valables pour un même service. D'ailleurs, énormément de services vieux comme le net ont été conçu pour être compatibles entre différents centres. Les mails en sont un très bon exemple. Du coup, vous pouvez créer votre propre service mail, et pour le coup aller envoyer paitre Gmail, créer votre propre messagerie XMPP et envoyer valser Skype/Facebook...
Tant que les services sont conçus pour que les centres se comprennent, on participe alors à la fédéralisation des services, qui est une forme plus progressiste de la décentralisation.
Le fait de s'auto-héberger est également un très bon moyen / le meilleur moyen / le seul moyen de se familiariser avec les techniques d'administration système. Car en vérité je vous le dit, à Hashtagueule, on encourage les gens à s'instruire, tant sur le point de vue de l'actualité que sur celui du savoir-faire, je pense que vous l'aurez compris. Et bien sûr, bien que vous puissiez trouver des masses de tutoriels sur la plupart de ces services sur le web, on vous en concoctera quelques-uns, avec nos astuces personnelles, c'est ça la valeur ajoutée Hashtagueule.
Je pensais que ce petit billet était utile afin de proposer une solution de plus à notre combat quotidien.
Un jour peut-être, le monde sera prêt à passer en pair à pair total. En attendant, soyez votre propre centre de services.
Et restez gentils.
]]>Aujourd'hui on va faire un tout petit tour du côté de la messagerie électronique instantanée, et puis des innovations apportées par le projet Tor.
La messagerie électronique, vous en utilisez probablement tous les jours. Il y a Facebook chat (et leur application Messenger), Google Hangouts, Skype de Microsoft, etc. Mais vous pouvez choisir des moyens décentralisés pour ça. XMPP est un protocole qui permet ça.
XMPP en très très gros
Pour faire simple, XMPP est un protocole qui permet de s'échanger des messages ayant un certain format via un serveur qui relaie les messages.
Il y a donc une liste de serveurs XMPP, et une liste de clients pouvant s'y connecter. Aujourd'hui, on va parler d'un nouveau client qui vient de sortir : Tor-messenger.
Tor-messenger
Comme je l'ai dit, Tor-messenger est un nouveau client XMPP (entre autres, il permet aussi de se connecter à IRC, Google Talk, Facebook Chat, et un service de Yahoo, et un de Twitter), c'est-à-dire qu'installer et lancer tor-messenger sur votre ordinateur va vous permettre de converser avec vos amis et connaissances utilisant XMPP ou IRC, ou Google Talk, ou Facebook Chat, etc.
Tor-messenger ((en), page d'annonce et de téléchargement) est un fork du logiciel libre InstantBird créé par Mozilla. C'est le projet Tor qui l'a adapté aux besoins de ses utilisateurs pour que Tor-messenger se connecte automatiquement via le réseau Tor.
Voici une capture d'écran de mon utilisation de Tor-messenger (XMPP + IRC) :
Tor-messenger : ajout de compte, fenêtre de contacts, fenêtre de clavardage, cliquez pour agrandir.
Le gros avantage, c'est que sous GNU/Linux, il n'est pas nécessaire d'installer Tor-messenger, il suffit de décompresser la tarball avec :
tar xvfJ tor-messenger-linux\*\_en-US.tar.xzet exécuter le script start-tor-messenger ou start-tor-messenger.desktop (pas exécuté dans un terminal, le second) dans le répertoire Messenger.
Ce qui change
En en parlant autour de moi, j'ai eu des réactions comme :
- Ça change tout !
- Mais qu'est-ce que ça change ?
Pour tout le monde, sur les grandes plateformes du web
Eh bien voyons cela. A priori ça ne change pas grand chose, puisque lorsque vous parlez à votre réseau de connaissances sur Facebook ou Google, fondamentalement, vous êtes toujours connecté à votre compte, et il y a toujours les logs. Ce qui change, c'est que passer par Tor empêche à la plateforme que vous utilisez sache où vous vous trouvez.
Ce qui pourrait changer à long terme
Ce que je vais écrire est complètement spéculatif, et un petit peu optimiste, mais bon, allons-y. Il est possible que la nouvelle génération vive avec deux types d'identités :
- celle fournie à l'État ;
- une grande quantité de pseudos sur internet, bien dissociés les uns des autres, et du nom réel.
On aurait alors --- selon cette hypothèse --- des plateformes qui deviennent aveugles face à leurs utilisateurs. Elles auraient toujours le contenu, etc. mais perdrait un grand bout de l'identification des gens.
Le problème que cela résoud est facile à représenter.
Lorsqu'une personne s'inscrit sur Facebook, elle va presque automatiquement faire ami-ami avec ses proches --- famille et amis --- et ses intérêts. Alors que d'autres réseaux sociaux fonctionnent différemment, comme Reddit (mon compte), Imgur, SoundCloud, etc.
Prendre l'habitude de toujours utiliser une multitude de pseudos sur internet amenuise le ciblage publicitaire, le tracking, le profilage, etc.
Ce qui change beaucoup, maintenant
Pour ceux qui utilisent régulièrement leur propre serveur XMPP décentralisé, ça permet en plus d'anonymiser leurs connexions.
En récapitulant brièvement ce qu'il se passe pour ces utilisateurs :
- ils ont un serveur XMPP décentralisé ;
- leur logiciel Tor-messenger :
- passe par le réseau Tor par défaut ;
- impose le chiffrement par défaut ;
- fait du chiffrement OTR (Off-The-Record messaging).
Leurs communications sont donc très bien protégées, dans le sens où elles sont protégées contre beaucoup d'attaquants éventuels, et avec des algorithmes de bonne qualité.
Motius
]]>Le dernier édito commence à dater, je pense qu'il est temps de vous reparler de l'actu interne, d'autant qu'on a quelques annonces à faire.
Tout d'abord, nous avons à nouveau nos mails ! Et c'est encore mieux qu'avant, car on a désormais notre propre serveur mail, et plus ce machin bizarre que proposait notre registrar. Donc tout ça pour dire qu'on a réalisé qu'on a dû louper quelques-un de vos mails, et on en est désolés :( . Mais vous savez, si on ne répond pas à vos mails, vous pouvez venir nous botter l'arrière-train sur notre canal IRC officiel (j'ai bien peur de ne pas avoir fini d'en faire la pub) où vous pouvez vous exprimer via les commentaires ou les forums.
Bon sinon, l'équipe s'agrandit et les sujets se diversifient. Nous accueillons dans nos rangs deux chroniqueurs, qui vont se présenter d'ici une semaine environ.
Voilà, c'est tout pour le moment, vous commencez à être un petit groupe de personnes fidèles à Hashtagueule, merci de nous faire confiance.
Restez gentils et soyez sages.
Raspbeguy
]]>Voici la première partie du tutoriel en temps réel que je vous avais présenté. Ici, on commence à mettre les mains dans le cambouis pour corrompre fertiliser notre machine pour qu'elle puisse router les IP comme une déesse.
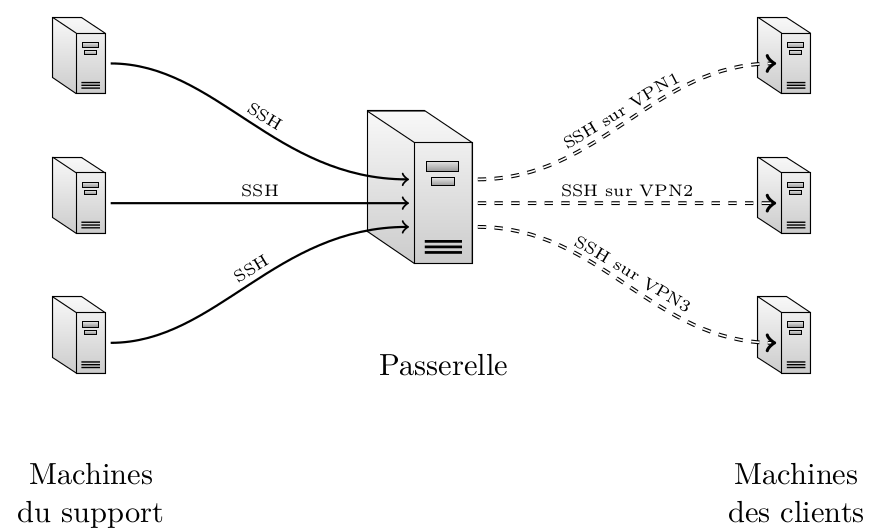
Schéma global de l'utilisation de notre passerelle
Je vous rappelle le problème. Afin que les clés SSH ne se baladent pas dans la nature, nous avons choisi d'utiliser un proxy SSH interne sur lequel se connecteront toutes les personnes qui on besoin de gérer une des machines distantes dont on a la charge. Ces machines distantes sont accessibles pour la plupart via un tunnel VPN. Et un VPN, par définition, est un moyen de créer un réseau (le N de VPN, pour network) privé (P pour private), c'est à dire inaccessible autrement sur les internets, et cela virtuellement (V pour virtual) car un "vrai" réseau se fait d'habitude physiquement, par le pouvoir et la sainte grâce du support physique brut, pur et candide (cuivre, fibre, onde électromagnétique, signaux de fumée, que sais-je encore) sans aucune intervention autre que celle d'équipements de niveau 2 dans le modèle OSI. Oui, le VPN ne sert pas qu'à télécharger illégalement des données de manière anonyme, chose qu'il fait d'ailleurs la plupart du temps très mal s'il n'est pas couplé avec d'autres techniques. Le tunnel VPN va alors se matérialiser sous la forme d'une interface spéciale sur la machine, de la forme tun ou tap, selon le protocole (pour les plus curieux, tap encapsule des frames Ethernet tandis que tun se limite à des frames IP, mais bon, on s'en tape).
Et comme les réseaux privés ne sont pas sensés être accessible de l'extérieur, les IP de ces réseaux n'obéissent à aucune pression extérieure, tels les joyeux hippies défoncés qui ont agrémenté les années 70. Ces adresses hippies sont généralement de la forme 192.168.X.X, 172.X.X.X, ou encore 10.0.X.X, ce qui fait que ces adresses hippies, même si elles s'affranchissent des ordres extérieurs, on tendance à se ressembler quand même un peu, c'est pourquoi ces tiennent également un peu du mouvement hipster.

Un exemple d'adresse IP de réseau privé.
On peut y voir tout ce que l'on veut, en bien ou en mal, mais une chose est sure, cette "hipsteritude" conduit souvent à des conflits lorsqu'il s'agit de s'y retrouver dans notre routage. En effet, imaginons, je veux envoyer un paquet à une certaine machine, je me débrouille donc pour obtenir son IP (disons l'adresse 192.168.0.2) et j'adresse ce paquet à cet IP. Seulement voilà, c'est tordant de rire, mais des IP comme ça, dans le monde, y en a des millions, et parmi mes connexions, comme j'ai pas mal de clients, il y a de fortes chances que ma machine incline là tête en arrière, me pointe du doigt et me raille méchamment. Ou alors il sera envoyé sur le premier chemin correspondant dans sa table de routage, ce qui n'est évidement pas la bonne solution. C'est ce qu'on appelle les conflits LAN to LAN.
Alors comment s'extirper de cette situation gênante ? La réponse est assez simple (en fait pas du tout) : faisons appel aux NetNS !
L'idée
Le raisonnement est le suivant : Puisqu'on ne dispose d'aucun moyen pour différencier nos IP en court-circuitant l'étape de la table de routage, eh bien utilisons plusieurs tables de routage ! C'est le rôle des NetNS (abréviation de network namespaces, ou "espaces de nommage réseau" en français). Créer un NetNS, c'est créer un nouvel ensemble de réglages réseaux, parmi lesquels des interfaces virtuelles et une table de routage toute belle toute neuve.
On peut donc ainsi cloisonner les différents réseaux virtuels qui peuvent mener des existences indépendantes, et tout ira bien dans le meilleur des mondes, pour peu que l'on exécute chaque processus dans le bon NetNS. Car oui, le beau côté de la chose, c'est que chaque processus est associé à un NetNS, par défaut au NetNS principal, c'est à dire celui qui contient les interfaces physiques.
En pratique
Les opérations suivantes s'effectuent en mode super-utilisateur ou avec la commande sudo. Soyez donc prudent, ne faites pas n'importe quoi, ne mangez pas vos enfants, la drogue c'est mal. Voilà.
On souhaite cloisonner un tunnel VPN. Pour cela on crée un NetNS que l'on nomme vpn0 par exemple. On va donc effectuer la commande :
ip netns add vpn0Ça y est, le NetNS est né ! Bon je vous avoue que tout nu comme ça, il ne va pas servir à grand chose, pour la simple et bonne raison qu'il ne contient encore aucune interface vers le monde extérieur (c'est embêtant quand on gère un réseau).
On va donc créer une interface de loopback lo (mandataire pour le bon fonctionnement de certains programmes, même si on ne s'en servira pas nous-même) et une interface main qui communiquera avec l'espace principal qui, je le rappelle, est le seul à contenir les interfaces physiques :
ip netns exec vpn0 ip link set dev lo up
ip link add nseth type veth peer netns vpn0 name mainExplications :
- La première ligne introduit la sous commande
exec: elle permet d'exécuter dans le NetNS dont le nom est fourni en premier argument une commande fournie à la suite. on exécute donc la commandeip link set dev lo updans le NetNSvpn0. - La deuxième ligne crée une paire d'interfaces : une dans l'espace principal (nommée
nseth) liée à une autre dans le NetNS nouvellement créé. Il s'agit d'un portail inter-NetNS.
On va maintenant assigner des adresse IP à ces interfaces. Eh oui, on fait comme si ces espaces étaient des machines séparées, du coup il faut mettre en place un routage IP...
Il s'agit de créer un petit réseau privé (à deux membres) avec une IP que j'ai choisie bizarre pour être sûr que personne ne l'utilise pour son adressage VPN. En théorie, un /30 suffirait, mais je vois large, et j'ai laissé un simple /24.
ip netns exec vpn0 ifconfig main 10.42.0.2/24
ifconfig nseth 10.42.0.1/24J'avoue qu'il s'agit là de la partie que je n'aime guère, le fait de créer des réseaux pour des interfaces virtuelles ne m'enchante pas vraiment. Mais je suis sur qu'il y a pire dans la vie, d'ailleurs j'ai déjà fait pire, et je referai sûrement pire (le tutoriel ne fait que commencer)...
Voilà, maintenant l'espace principal et le nouveau NetNS se connaissent mutuellement. Mais c'est pas fini. Parce que le nouveau NetNS, il ne sais pas qu'il faut passer par l'espace principal pour accéder à internet.
ip netns exec vpn0 route add default gw 10.42.0.1On ne fait qu'ajouter une entrée à la table de routage du nouveau NetNS pour lui dire "Quand tu ne sais pas ou tu vas, il faut y aller passe par l'espace principal".
En l'état, toutes les requêtes sortantes provenant du nouveau NetNS arrivent à l'espace principal, mais lui n'en a cure. Il faut alors activer la redirection IP dans l'espace principal :
sysctl -w net.ipv4.ip\_forward=1Et voilà vous pouvez taper sur n'importe quel serveur depuis votre nouveau NetNS !
Mais mais mais (parce qu'il y a un mais) ce n'est pas fini, et c'est ça, la valeur ajoutée Hashtagueule, car je n'ai trouvé aucune ressource sur le net évoquant le problème suivant : les requètes montent, pour ça, aucun problème. Mais jamais elle ne redescendrons, en tout cas pas en l'état. Vous pouvez vérifier par vous même avec la commande :
ip netns exec vpn0 ping 8.8.8.8Vous n'obtiendrez aucun écho ICMP. Pourquoi donc ?
Voyez-vous, L'IP-forwarding est bien pratique, mais il ne réfléchit pas plus que ça (et il a bien raison, car en tant normal on lui demande pas de réfléchir). Quand il reçoit un paquet qui ne lui est pas destiné, le serveur regarde dans sa table de routage vers quelle passerelle il enverrait lui-même ce paquet, et il retransmet le paquet intact. J'ai bien dit intact, c'est à dire sans modifier l'adresse source. Et l'adresse source, ben en l’occurrence c'est 10.42.0.2, une adresse bizarre que nous avons nous même attribué, une adresse interne, une adresse hippie, bref, aucune chance de routage retour.
Ce problème peut vous en rappeler un autre, enfin plus exactement le même problème mais dans un autre contexte. Si vous avez une box internet et plusieurs PC derrière, vous avez pu remarquer que vous n'avez qu'une seule IP publique, celle de votre box, et que vos PC ont chacun une IP interne. C'est exactement notre cas, sauf que nos PC ici sont virtuels (chaque NetNS auxilliaire représente l'équivalent d'un PC au point de vue réseau), et que les PC derrière une box arrivent à faire des ping à qui ça leur chante. Pourquoi ?
Eh bien, la box utilise un NAT, c'est à dire un bidule qui permet, entre autres, d'altérer des paquets sortant et de bien diriger les paquets entrants. Saux que votre box fait ça toute seule. Vu que nous on a un Linux (ouais, liberté, pouvoir au peuple, et tout et tout) on va devoir faire un NAT dans notre espace principal, qui correspond par analogie à la box. L'outil Linux pour faire un NAT s'appelle iptables, et c'est un outil assez immonde à apprendre à maitriser. Mais ne craignez rien, Hashtagueule est là pour vous tenir la main et vous écouter pleurer la nuit quand personne d'autre ne vous prête attention.
En fait, iptables est un parre-feu, c'est à dire qu'il va examiner tous les paquets venant de tous les côtés et va décider de leur sort : basiquement, les laisser passer ou les ignorer.
Pour faire du NATing, déjà, il faut activer le mode masquerade, c'est à dire la réécriture des ports entrants et sortants :
iptables --table nat --append POSTROUTING --out-interface eth0 -j MASQUERADE(en admettant que vous vous connectez à internat par l'interface eth0).
Vous pouvez définir des ensembles de règles (on les appelle des chaînes de règles), et il est recommandé de faire une chaîne spéciale pour vos NetNS, histoire de ne pas flinguer une configuration déjà existante, et dire à la chaîne principale dédiée à la redirection des paquets de prendre en considération cette nouvelle chaîne :
iptables -N netns
iptables -A FORWARD -j netnsPuis vous allez dire à votre NAT d'accepter tous les paquets impliquant l'interface virtuelle vers notre nouveau NetNS :
iptables -A netns -i nseth -j ACCEPTVoilà, vous êtes parés ! Maintenant votre NetNS peut pleinement communiquer avec Internet. Les paquets sortants seront modifiés afin de prendre l'IP publique, et les paquets entrants seront automatiquement restitués au bon NetNS.
Maintenant, pour ouvrir un VPN sans risquer de troubler votre routage (c'était le but à la base), par exemple avec OpenVPN, et ouvrir une connexion SSH sur un serveur membre de ce VPN, vous n'avez qu'à effectuer les commandes :
ip netns exec vpn0 openvpn fichier\_de\_conf.ovpn
ip netns exec vpn0 ssh mon\_serveur\_distantAstuce : pour ne pas être obligé de retaper ip netns exec vpn0 à chaque commande, vous pouvez lancer un nouveau shell dans le NetNS et bénéficier ainsi de l'hérédité de l'environnement de travail :
ip netns exec vpn0 bash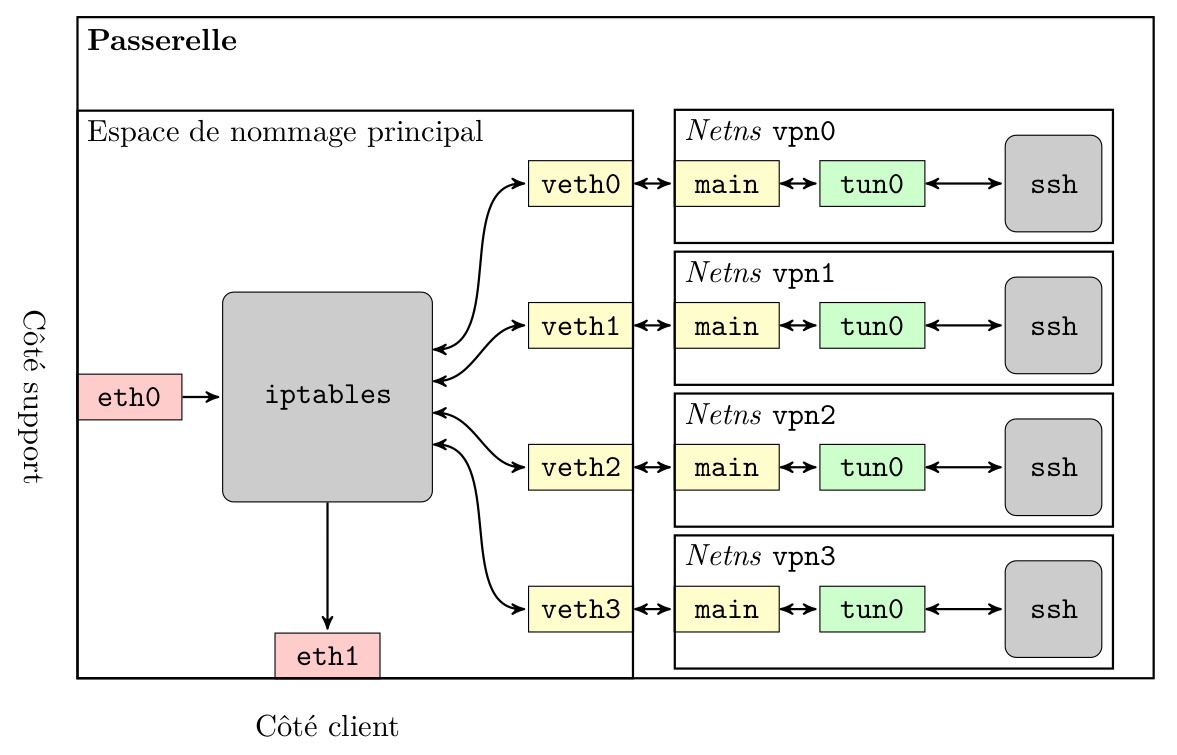
Récapitulatif du fonctionnement interne
Voilà, c'est pas beau tout ça ?
Eh bien non, ce n'est pas beau. Il y a plusieurs grands problèmes :
- Il est nécessaire de passer en super-utilisateur pour passer des commandes dans les NetNS qui nous intéresse et pour lancer des tunnels VPN.
- On ne veut pas être obligé de se rappeler d'utiliser tel ou tel protocole pour ouvrir un VPN. Il faut standardiser tout ça.
Nous verrons la solution de la standardisation des accès VPN dans la partie 2.
Restez connectés, à la prochaine.
]]>Aujourd'hui on va s'attaquer à un très gros morceau : la publicité. En tous cas celle en ligne. Et croyez-moi, il y a vraiment énormément à dire. Donc je ne pourrais pas tout traiter, mais je vais essayer d'aborder le plus possible les points essentiels, puis voir quel position aborder face à ce phénomène qui s'est emparé de toutes les pages web. Toutes ? non, seules une minorité résiste encore et toujours...
C'est vraiment dur de s'attaquer à un sujet aussi gros que celui-là. Où commencer, quel aspects traiter, quels sont les apports et les méfaits, etc. On va donc faire thématique, pour diviser le boulot.
Les inconvénients techniques de la publicité
Le rendu de la pubilicité
C'est bête à dire --- heureusement de moins en moins vrai sur la majorité des sites --- mais parfois les publicités empêchent la bonne lecture du site. Soit que la publicité soit plus grande que prévue, qu'elle soit animée, avec du son, qu'elle clignote, soit qu'elle ne prennent pas en charge les mobiles. Et ça peut être particulièrement lourd.
La bande passante consommée
Indéniablement, charger de la publicité --- ie du contenu --- consomme de la donnée et diminiue la bande passante disponible durant la période de chargement.
Tracking
Pour cela il faut examiner le réseau de distribution de la publicité :
- la publicité d'un site web émane rarement de celui-ci, mais la grande majorité du temps de serveurs de pubs tiers (ex : googleads.g.doubleclick.net, adserver.yahoo.com, azure de Facebook --- vendu par Microsoft --- etc.) ;
- la raison à cela est que les vendeurs de pub ont besoin de savoir combien de fois leur pub a été vu / combien ont suivi le lien etc., il y a donc un problème de confiance si les vendeurs de publicité n'ont pas la main sur le serveur distribuant la publicité.
Ça pose un problème concernant le tracking des informations sur internet. En effet :
les boîtes les plus rentables en matières de publicité sont les plus grosses, il y a donc peu d'entreprises qui vendent de la pub. En fait on en connait la majorité (Google, Facebook, Twitter, Microsoft, via leurs services spécialisés), et les rares que le grand public ne connait pas sont des startups qui ont de bonnes idées/un bon algorithme, et qui finiront dans le ventre d'un des géants (critéo, etc.).
Ainsi le premier problème est qu'une minorité d'entités connaît la plupart des choses que nous faisons sur internet, ce qui constitue un genre d'espionnage permanent des communications numériques de tout le monde.
Le second problème vient de l'idée de valorisation de la publicité : pour éviter qu'une publicité sur les produits hygiéniques féminin ne soit vu par des hommes, il faut les cibler. De là découle le tracking par les entreprises sur internet. Une course à qui vendra le mieux ses internautes, en somme...
Format des publicités
On ne dirait pas mais c'est extrêmement important. Savoir si la publicité est une image JPG/PNG a priori beaucoup moins dangereuse qu'une publicité utilisant flash ou java. Il ne faut pas perdre de vue qu'un serveur http peut proposer une page, et demander au navigateur web d'aller chercher une page http sur un autre serveur, laquelle peut faire exécuter du code javascript par le navigateur. Eh bien ça, c'est vraiment un immense problème. C'est tout simplement inadmissible. Ça veut dire qu'on va sur le serveur a.chose qui appelle une page du serveur b.publicite et la page située à l'adresse b.publicite se permet d'exécuter du code sur votre ordinateur. Autant se balader à poil sur internet. Avec ce mécanisme l'utilisateur ne choisit plus en qui il a confiance.
Le "native advertising" alias publicité native (?)
Je ne connais pas l'équivalent français. Il s'agit de publicité ayant un contenu. Par exemple vous tombez sur un article qui à l'air d'être du contenu, mais qui en fait est une publicité.
Certains américains se targuent de l'avoir inventé en 2012, mais ça a toujours existé, sous la forme d'une biographie sponsorisée, sous la forme d'un blogueur spécialisé à propos d'une entreprise, etc.
Ça pose pas mal de problèmes, notamment concernant la confiance dans internet. Selon les sites qu'on visite et les thèmes de prédilection, on peut avoir une confiance plus ou moins grande dans ce qu'on lit sur internet. Et bien ceci ne va pas aider. Surtout en ce qui concerne l'éducation des enfants.
Petite parenthèse sur la publicité, la confiance dans l'information qu'on reçoit et l'actualité :
À propos de ce sujet, la loi que le gouvernement essaie de faire passer pour interdire la publicité sur les chaînes publiques destinées à des moins de 12 ans est sympa, mais très en retard ! La majorité de ceux né au moment de ces débats passeront beaucoup plus de temps sur internet qu'à regarder la télévision (enfin j'espère !). Il y a tout de même un débat qu'on n'a pas eu, c'est celui sur l'étendue de l'application de la loi. À ce jour, celle-ci est supposée être limitée à la télévision publique, mais ça pose un problème d'inégalité entre le public et le privé qu'on peut résoudre de plusieurs manières :
- une version assez "communiste"/État stratège de la chose où l'on impose la même aux entreprises privées ;
- une version où l'on ne fait rien, et l'on garde le déséquilibre ;
- une version où l'on abroge la loi.
De là à dire qu'il faut un pacte des acteurs du numériques sur la publicité et l'éducation des enfants... On verra comment ce sera traité.
Fin de la parenthèse
Perte de valorisation de la publicité
Je vais oser commencer par le trop entendu "trop de x tue le/la x" : trop de pub tue-t-il la pub ?
Le but de la publicité ciblée était d'éviter les publicité ne concernant pas les gens. De ce constat, on en est arrivé à une course à qui affichera la publicité la plus adaptée. Il y a littéralement des enchères qui sont faites sur un profil de l'utilisateur pendant le chargement de certaines pages web.
Pourtant plus on affiche de publicité, et moins elles ont de valeur. Pas parce qu'on y est moins réceptifs --- il faudrait prouver cela, et ça me paraît difficile --- mais tout simplement parce que la publicité incite à l'achat, et que la capacité d'achat (oui, j'ai fait exprès) n'est pas infinie.
On aperçoit ici deux vision du monde de la publicité :
- celle où l'on s'écharpe, c'est la guerre à qui fera la meilleure publicité, la vendra le mieux, au prix le moins cher, et après tout, c'est compréhensible dans un monde de compétition ;
- celle où le nombre de publicité est limité, où chacune possède une plus grande valeur, et nécessairement où l'on a trouvé un moyen pour réguler ce bazar --- c'est pas dit.
Et de la centralisation naquit le pouvoir...
Une chose à ne pas perdre de vue, c'est que beaucoup des noms célèbres sur internet ont eu des problèmes avec les sociétés vendant de la publicité, au point que certains --- je pense à quelques blogueurs renommés --- se sont vu intimé l'ordre de retirer un contenu ou risquer de perdre une source de revenus sur la toile.
Ça veut évidemment dire que critiquer les entreprises vendant de la publicité ou leurs intérêts est limité voire impossible, problème de censure, de critique du pouvoir, donc de type dictatorial.
Ça veut aussi dire qu'il n'y a pas une assez grande concurrence, puisqu'une personne ayant une sérieuse réputation aura du mal a faire jouer la concurrence.
Intérêt de la publicité
Un tweet à l'air provocateur de Marissa Mayer prétend que la publicité peut améliorer internet... vu qu'afficher la publicité est le comportement par défaut des navigateurs web, et qu'une partie des internautes s'acharne à installer adblockeur sur adblockeur, on peut vite répondre sur la valeur des publicité indésirables...
Cet exemple n'est pas seul. Qui ne s'est jamais retrouvé, au bout d'une suite de trois vidéos suggérées sur youtube, avec une vidéo n'ayant pas de rapport avec la première ? En ce qui me concerne, je suivais sur twitter le compte @MSDN de news de microsoft, et me suis retrouvé avec des tweets sponsorisés par Microsoft® --- dont je n'ai pas grand chose à faire, puisque j'évite le plus possible cette plateforme, et que l'intérêt que je porte à MSDN est lié aux nouvelles technologies, à l'actualité scientifique et technique...
Une dernière chose --- je vais faire mon vieux con ici --- parfois la publicité engendre de mauvais comportement (c'est pour cela que les publicité sur l'alcool sont accompagnées d'un message de prévention). Avoir de la publicité à outrance n'est pas sain.
Les raisons de la publicité
On nous a rebattu les oreilles avec, mais faisons-le encore.
Le marketing
Faire connaître un produit ou un service est une tâche complexe. On s'en rend compte à hashtagueule.fr, où nous cherchons à faire entendre notre voix.
Financement
Une bonne partie des choses qui nous coûtaient dans le monde analogique est devenu "gratuit" --- enfin pas tout à fait --- dans le monde numérique où l'on ne développe plus ses photos pour en faire un album qu'on triera, mais on les publie sur un site qui se charge de tout. Idem pour le mail, etc. Un des inconvénients de passer d'une société de biens à une société de services, la transition coûte cher, et il faut définir le nouveau business modèle.
La publicité est donc le modèle choisi par beaucoup pour financer leur activité (journalistes, blogueurs, hébergeurs de contenu, etc.).
Design et représentation graphiques
La publicité c'est aussi l'occasion pour les marques de créer une identité visuelle, et pour les designers en tous genre --- du graphistes jusqu'au webdesign --- d'inventer la représentation visuelle de nos produits et sesrvices. Il n'y a qu'à demander aux fans de toutes les industries liées de près ou de loin au luxe, la puublicité a une histoire.
Avenir de la publicité
Il y a peu de temps duckduckgo.com a anoncé être bénéficiaire. DuckDuckGo est un moteur de recherche plutôt centré sur le monde anglophone (il donne aussi des résultats français) qui affirme de pas tracker ses utilisaterus --- et donc leur fournir du contenu non ciblé. Et pourtant, DuckDuckGo arrive à être rentable, et à ce que publicités ne soient pas vaines.
Qwant.com vient de lever 25 millions d'euros pour se développer, et va tenter de percer dans le marcher allemand (il est français à la base, mais donne aussi des résultats en anglais). Lui aussi a un business modèle sympa :
- il ne fait pas de publicité, mais propose des résultats liés à l'achat/vente que lorsque les termes recherchés semblent indiquer l'intention de faire du shopping ;
- il se rémunère à l'aide d'un partenariat avec des vendeurs.
En définitive
La publicité non personnalisée --- à l'aide de tout un tas de trackers --- a un avenir chez ceux qui font de la publicité intelligente, qui servent les pubs à bon escient.
Comme Google a influencé la construction du web à via son algorithme pagerank etc. puisque les sites veulent --- généralement --- être indexés et bien recensés, peut-être que les bloqueurs de pubs pourront transformer le web de telle sorte qu'une partie des sites web adoptent une politique de présentation des publicités plus éthique. On pourrait avoir entre autres (pas nécessairement pour chacune d'elles) :
- des publicités sans animation ;
- des publicités sans images (plus rapide à charger) ;
- un cadre réservé au publicité avec la mention "publicité" (pour éviter, par exemple, que des journaux ne perdent en crédibilité à cause du native advertising) ;
- des publicité hébergées par le possesseur du site web (peut-être à condition de pouvoir mettre en place un mécanisme de vérification par le vendeur de pubs (pas toujours nécessaire : on sait approximativement combien de personnes sont lecteurs de tel ou tel journal)) ;
- etc.
Motius
]]>Vous avez aimé le petit tuto Lilypond 1 ? Eh bien c'est reparti pour un tour.
Petit récapitulatif
Passez ce paragraphe si vous connaisez mon précédent article par cœur, ou si vous avez déjà des bases de Lilypond. Il s'agit cependant d'un récapitulatif complet et simple. La dernière fois, je vous ai montré :
- le mode absolu de représentation d'une note avec LiLypond (par défaut, pas recommandé) ;
- le mode relatif (instruction
\relative c') ; - comment do-ré-mi-fa-sol-la-si s'écrit
c-d-e-f-g-a-ben Lilypond ; - comment augmenter la hauteur d'une note avec
'; - comment abaisser la hauteur d'une note avec
,; - le dièse avec
is, le double dièse avecisis; - le bémol avec
es, le double bémol aveceses; - comment définir la longueur d'une note avec les puissances de 2 (
1: ronde,2blanche,4noire,8croche,16double croche...) ; - les accords à l'aide des brackets
<et>; - comment changer de rythme avec l'instruction
\time 3/8; - comment changer de clef à l'armure avec l'instruction
\clef(treble, bass...) ; - comment imposer une tonalité à l'aide de l'instruction
"\key c \minor"ou"\key f \major"par exemple ; - comment faire des legati avec
(et); - comment forcer la ligature des crochets de hampe de (simples-, doubles-...) croches à l'aide de
[et]pour l'esthétique visuelle aussi bien que pour la facilité de lecture du chant ; - comment compiler à l'aide de la commande lilypond (on peut aussi utiliser l'IDE Frescobaldi) ;
- comment faire en sorte que Lilypond nous ennuie pas avec la version de Lilypond utilisée avec le header
\version "2.18.2"; - comment marquer les mesures (facultatifs, mais un moyen de vérification utile) à l'aide de
|.
Vous savez plein de choses ! Mais la musique est un art, et qui dit art dit beaucoup de travail et un peu de génie. Allons voir comment Lilypond vous permet de représenter le génie qui habite vos partitions préférées...
La suite...
Au programme :
- écrire plusieurs portées, (jusqu'ici, on n'en a écrit qu'une seule, ce qui est un peu triste pour du piano...) ;
- représenter plusieurs voix ;
- écrire les ornements ;
- faire disparaître les mesures ! magie ! ;
- faire disparaître l'armure ! magie magie ! ;
- un retour sur les rythmes avec les pointées ;
- écrire des commentaires dans la partition.
On va s'y prendre de la même manière que la première fois, rien ne vaut un petit exemple simple pour comprendre.
Plusieurs portées
On pourrait essayer de faire ça pour obtenir deux portées :
\version "2.18.2"
upper = \relative c'
{
c e g
}
lower = \relative c
{
c e g
}Mais ici on ne dit pas à Lilypond comment il doit gérer les deux groupes de notequ'on a créé. La seule chose ici qu'on a fait, c'est dédoubler le premier groupe de musique et on leur a donné des noms. On a de plus pas généré de PDF ! C'est un bon début, mais ce n'est pas suffisant. Il faut donc préciser dans un header -- qu'on va placer à la fin, je suppose que ça en fait un footer -- comment les ajouter. Voici le code, attention les yeux :
\version "2.18.2"
upper = \relative c'
{
c e g
}
lower = \relative c
{
c e g
}
\score
{
\new GrandStaff \with { instrumentName = "Piano" }
<< \new Staff = upper { \new Voice = "singer" \upper } \new Staff = lower { \lower } >>
}Voilà, c'est un peu moche, mais on ne touchera plus à ce footer dans cette deuxième partie de tutoriel. Il est cependant très utile, puisqu'il permet en théorie l'ajout de paroles et la création automatique du fichier midi de votre partition. Voici le résultat tand attendu :

Deux portées au piano. Le début de la gloire !
Bon maintenant tout ça donne un PDF un peu moche, alors rendons-le plus joli. Vous savez faire, il suffit de changer la clef à l'armure (je ne mets plus les headers ni les footers) :
\version "2.18.2"
upper = \relative c'
{
c e g
}
lower = \relative c
{
\clef bass
c e g
}qui donne :

Partition à deux portées avec Lilypond
Commentaires
Pour insérer un commentaires en lilypond, il suffit d'utiliser le caractère %.
Tout ce qui suit le % est ignoré par le compilateur. Voilà. Simple et efficace.
Plusieurs Voix
On se représente les voix facilement lorsqu'il y a plusieurs instruments, donc sur plusieurs portées, mais une portée peut représenter plusieurs voix. Le code peut ressembler à ceci :
\version "2.18.2" % ---- header ---- %
upper = \relative c'' {
\clef treble
<< \voiceOne{c4 c c c c} \\ \voiceTwo{b4 b2 b4 b} >>
}
% ---- footer ---- %
\score {
\new GrandStaff << \new Staff = upper { \new Voice = "singer" \upper } >>
\layout {
\context {
\GrandStaff
\accepts "Lyrics"
}
\context {
\Lyrics
\consists "Bar_engraver"
}
}
}dont le rendu est :
Gérer deux voix sur une portée avec Lilypond
Pas très original, mais pratique pour faire apprécier l'idée : ici le chant en haut est constitué de do 4, et la basse de si 4 et 2.
J'ai encore un peu modifié le footer pour que les deux voix soient prises en compte.
Ornements
Vous connaissez ces jolies petites notes qui ne compte (souvent) pas dans le calcul de la longueur de la mesure ? Il y en a plein et nous allons les découvrir.
upper = \relative c'' {
\clef treble
\appoggiatura{a8} c2 \appoggiatura{a16}c2 | \appoggiatura{a32}c2 \appoggiatura{a16 b}c2 | r1 \bar "" \break
\acciaccatura{a8} c2 \acciaccatura{a16} c2 \acciaccatura{a32} c2 \acciaccatura{a16 b} c2 r1 \bar "" \break
\grace{a8} c2 \grace{a16} c2 | \grace{a32} c2 \grace{a16 b} c2 \bar ""
}Il s'agit la de trois ornements que j'ai mis en parallèle pour que vous puissiez voir la différence facilement :

Ornements avec Lilypond
Les notes sont espacées exprès à l'aide de la commande \break. Ce n'est pas utile pour l'instant, il s'agit d'une commande avancée mais je l'ai utilisé pour que les notes soient très écartées, pour plus de lisibilité.
Trilles - mordants
On n'oublie surtout pas les mordants et autres trilles qui vont de pair avec les ornements :
upper = \relative c'' {
\clef treble
c4\trill r2 r4 | c\prall r2 r4 | c\mordent r2 r4 | c\turn r2
}dont le rendu est :

Trilles et mordants avec GNU Lilypond
Écriture du rythme
Si vous avez fait un peu de mathématiques ou d'informatique, vous savez qu'on peut représenter n'importe quel nombre à l'aide des puissances de 2. Les musiciens devaient savoir ça et permettent de rallonger les notes ainsi :
upper = \relative c'' {
\clef treble
a4 r2 r4 |
a. r8 r2 |
a4.. r16 r2 |
}ce qui donne :

Notes pointées avec Lilypond
J'ai fait exprès ici de mettre les silences complémentaires pour terminer la mesure afin qu'on se rende compte de l'effet du . sur la note.
Accentuations
Voici comment expliquer la façon dont une note est jouée :
upper = \relative c'' {
\clef treble
a4 a^. a^- a^> |
a^1 a^^ a^+ a-\_ |
}ce qui donne sans grande surprise :

Notes accentuées avec Lilypond
Ici le ^ sert à introduire le signe qui sera utilisé sur la note.
Pour quelques sesterces de plus...
On en a fini (je crois) avec les principales règles de Lilypond. Bien sûr il y en a encore plein d'autre qui existent et elles sont plus ou moins importantes en fontcion des partitions que vous jouez. Alors pour finir, on va faire disparaître la mesure, et c'est là que vous vous rendrez compte que les commandes de Lilypond sont très puissantes.
global = {
\cadenzaOn %supprimer les mesures
\override Staff.TimeSignature.transparent = ##t
}
upper = \relative c'' {
\clef treble
a4 a a a
a a a a
a a a a
}donne

J'ai donc utilisé un header supplémentaire, le header global, auquel j'ai donné une instruction : \cadenzaOn, et une commande \override Staff.TimeSignature.transparent = ##t.
Et après ?
On n'a pas fini. loin de là ! il reste à découvrir, entre autres :
- comment générer le fichier midi associé à votre partition ;
- comment gérer les barres de mesures de fin de partition ;
- comment gérer les mesures partielles (je vous ai aidé, là, ça s'appelle une anacrouse) ;
- la gestion des paroles
- et probablement beaucoup d'autres choses !
mais pour cela il faudra revoir de plus près la structure logique du document texte .ly, et non pas seulement ce qu'il y a entre les accolades. Ce sera donc pour le petit tuto lilypond 3...
Merci d'avoir suivi ! À bientôt, et n'hésitez pas à commenter !
Motius
]]>Savez-vous comment marche le mécanisme de la confiance dans une page web reçue avec HTTPS ? Petit tour rapide et présentation de Let's Encrypt.
Si vous êtes un lecteur régulier du site, vous savez que le chiffrement de bout en bout est un dada chez moi, plutôt que le chiffrement point-à-point. On n'a pas encore fait de glossaire, donc je vais le réexpliquer à cette occasion, mais on finira par se référer à un petit manuel de bases. Donc si vous connaissez, vous pouvez zaper la partie 0 qui suit.
Chiffrement de bout en bout vs chiffrement point à point.
C'est assez simple :
- le chiffrement de bout en bout signifie que votre ordinateur chiffre avec la clef de votre correspondant, et par conséquent sur le réseau, le message est toujours chiffré ;
- le chiffrement point à point est appliqué entre vous et votre pair direct, puis (éventuellement) votre pair chiffre avec son pair, etc. jusqu'à destination, le message peut donc :
- traverser un bout du réseau sans chiffrement ;
- être lu par tous les pairs qui ont acheminé le message.
- En comparaison, c'est comme si une lettre à La Poste était lu par tous ceux qui l'ont en main, et que de temps en temps le service de poste était négligent, et laissait à tous la possibilité de lire la lettre.
Sur internet vous utilisez les deux :
- le mail utilise le chiffrment point à point (sur lequel vous pouvez rajouter du chiffrement de bout en bout avec GPG/PGP) ;
- parler HTTPS avec un serveur permet de récupérer une page qui sera chiffrée entre vous et le serveur, donc d'un bout du réseau à l'autre.
Comment fonctionne le HTTPS ?
HTTP vs HTTPS, méthode de chiffement
HTTP est un protocole qui permet de récupérer des pages web. Exemples de ce qu'on peut "dire en HTTP" :
- quand on est le client :
- donne moi la page à cette URL ;
- quand on est le serveur :
- la page que tu m'as demandé, je l'ai, la voici ;
- la page que tu m'as demandé, je l'ai, mais attends un peu, je suis surbooké, là (schématiquement) ;
- la page que tu m'as demandé, bah elle existe pas (404) ;
- ce que tu demandes n'est pas ici, va voir ailleurs (301) ;
- j'ai pas compris ce que tu m'as demandé (400) ;
- ce que tu fais-là, tu n'en as pas le droit (403) ;
- le serveur est en panne (503)...
Et beaucoup d'autres. HTTPS n'est que l'utilisation d'une couche de chiffrement (SSL/TLS) pour chiffrer les données :
- la requête (pas celles initiant le chiffrement) ;
- les données échangées par la suite.
Pour visualiser la couche de chiffrement, on peut se représenter un tunnel entre le client et le serveur dans lequel la donnée passe. Personne ne peut accéder à l'intérieur du tunnel parce qu'il est solide, et le tunnel a une entrée (le client) et une sortie (le serveur).
Confiance de HTTPS
Lorsqu'Alice va demander la page web de Bob en HTTPS, que va-t-il se passer ?
- Le client A (son navigateur web Firefox) va faire une requête vers un serveur B
- B qui va indiquer qu'il sait parler HTTPS ;
- A va interroger B ;
- B va répondre, et s'il a la page, la transmettre.
Tout ça s'est fait automatiquement. Voyons un peu l'architecture de chiffrement mise en place ici. Il s'agit d'une infrastructure clef publique/clef privée + autorité de confiance :
- A va obtenir via le réseau la clef publique de B.
- Le navigateur web de A va vérifier que la clef est valide, c'est à dire qu'il s'agit bien de la bonne clef (et pas celle d'un attaquant) et qu'elle est toujours valide (par mesure de sécurité, les clefs ont une durée de validité, d'un an en général).
- A va chiffrer ses messages pour B avec la clef publique de B.
- B déchiffre ses messages avec sa clef privée.
Ainsi, la confiance que l'on a dans HTTPS dépend de deux facteurs :
- comment le navigateur reconnait qu'un certificat est valide ;
- la qualité du chiffrement, ie les algorithmes utilisés (RC4 : mauvais, AES-256 très bon, à ce jour).
On ne parlera pas plus des algorithmes ici, à la place on se concentrera sur comment le navigateur a décidé de reconnaître un certificat, ou de l'invalider.
Réseau de confiance de l'architecture X509
Le problème de fond, c'est de reconnaître la validité d'une clef de chiffrement (publique) pouvant changer fréquemment obtenue via internet.
On utilise ce qu'on appelle un pair de confiance. Si un certificat est signé par un pair de confiance, alors le certificat est considéré comme valide. Le pair de confiance dans l'architecture X509 s'appelle une autorité de certification (AC, parce que j'ai pas envie de le réécrire ;) ). Par défaut Firefox fait donc confiance à un certaint nombre d'AC.
Ainsi lorsqu'une clef publique arrive depuis internet :
- si le certificat est signé par une AC, il est valide (sauf cas exceptionnel où l'utilisateur a interdit le certificat) ;
- si le certificat n'est pas signé par une AC, mais est accepté par l'utilisateur, il est valide ;
- le reste poubelle, la connexion est terminée.
Dans les AC vous en connaissez peut-être quelques unes dont Thawte, VeriSign, GoDaddy, CA-Cert, Gandi, Google (eh oui, il font ça aussi), et depuis peu Let's Encrypt.
Mais la chaîne de confiance n'est pas complète. Comment savoir quelles sont les entités reconnues, comment en rajouter sans mettre à jour tous les navigateurs ?
Eh bien à la base de la création de X509, on a généré une clef c0, et une clef c1, on a signé la clef c1 avec la clef c0 et découpé c0 en plusieurs (4 ?) parties qu'on a dispachées dans des coffres-forts. On fait donc en sorte que la clef 0 soit reconnue, et on signe les AC avec la clef c1. Les entités créent leur clef c_entite (plusieurs en fait), qui est valide, puisque signée par c1, elle-même valide puisque signée par c0.
Récapitulons. On fait confiance à c0. c0 signe c1, de telle sorte que :
- c1 puisse signer des certificats ;
- c1 puisse signer des AC ;
On signe les AC, qui créent leur clefs, qui sont signées par c1 de telle sorte que :
- elles puissent signer des certificats ;
- éventuellement elles puissent signer d'autres AC.
Ainsi, la chaîne de confiance est une hiérarchie. Faire confiance à c0 permet/implique a priori de faire confiance à beaucoup de gens (on peut cependant demander à Firefox de ne pas accepter un certificat valide).
Subtilité de X509, résilience
Vous avez peut-être remarqué que c0 ne sert qu'à signer c1, puis on demande au navigateur de reconnaître c0, puis on signe avec c1.
Vous vous demandez peut être pourquoi... Imaginons que c0 = c1 = c$latex \alpha $, c'est à dire qu'au début de la chaîne de confiance il y ait non pas deux mais une seule clef c$latex \alpha $.
Un problème se pose, et a pas mal de répercussions :
Si la clef $latex \alpha $ est perdue alors toute la sécurité de l'architecture X509 s'effondre.
- Dans le cas où on n'a qu'une clef c$latex \alpha $, on ne peut rien faire.
- Dans le cas ou on a c0 et c1, et c1 est perdue (on suppose que c0 n'est pas perdue, elle sous clef, éparpillée sur le globe), on révoque c1 à l'aide de c0, et on regénère une clef c1'. Ça permet notamment de pouvoir rapidement recréer un environnement de confiance, et de ne pas avoir besoin de rediffuser la clef à toutes les machines.
Let's Encrypt
Alors pourquoi est-ce que je vous rabats les oreilles avec tout ça ? Eh bien pour deux raisons :
- d'abord pour que vous sachiez quelle confiance accorder dans des connexions HTTPS ;
- ensuite pour vous parler spécialement d'une AC : Let's Encrypt.
Vous l'avez compris, il y a beaucoup d'enjeux concernant une AC. La confiance qu'on a, la qualité de son travail, de la façon dont elle sécurise ses données pour ne pas perdre sa clef et servir de vecteur d'attaque, etc. Il y a d'autres enjeux dont la possibilité pour tous de chiffrer facilement, en effet les certificats ne sont pas gratuits, sauf certains de CA-Cert, et de Gandi.
C'est pourquoi Mozilla Cisco l'EFF et d'autres se sont unis pour créer une AC dont le but serit de permettre à tous de pratiquer le chiffrement à tour de bras. Et voilà qui est fait.
Depuis le 19 octobre 2015 les certificats de Let's Encrypt sont de confiance par défaut dans les versions récentes de Firefox (probablement Chrome/Chromium, Microsoft Edge, et Safari).
Let's Encrypt va donc pouvoir se mettre à un rythme de croisière de signatures de certificats d'ici très peu de temps.
Bon chiffrement à tous et bonne journée !
Motius
]]>AVG décide de vous influencer sur ce que vous lisez sur le web. Il s'agit là d'une petite expérience à laquelle je me suis retrouvé confronté par hasard après avoir lu cet article sur slashdot.org
L'article de slashdot contient ce texte :
An anonymous reader writes: AVG, the Czech antivirus company, has announced a new privacy policy in which it boldly and openly admits it will collect user details and sell them to online advertisers for the purpose of continuing to fund its freemium-based products. This new privacy policy is slated to come into effect starting October 15. The policy says: We collect non-personal data to make money from our free offerings so we can keep them free, including: Advertising ID associated with your device; Browsing and search history, including meta data; Internet service provider or mobile network you use to connect to our products, and Information regarding other applications you may have on your device and how they are used.
en gros et en français, dans leur politique de confidentialité :
Bonjour, c'est nous AVG la boîte qui faisons votre antivirus -- vous savez, un type de logiciel présent dans à peu près tous les Windows®, et qui a une quantité de permissions colossales -- eh bien aujourd'hui on a décidé de vendre vos données personnelles puisque tout le monde s'y est mis, que tout le monde s'en fout, et que c'est la mode. On va regarder ce que vous faites sur votre navigateur web, regarder vos métadonnées (franchement large !), des informations permettant d'identifier votre ordinateur (cookies), des informations sur votre FAI (Orange, Free, SFR, Numéricâble, Bouygues...) et des informations sur des applications installées.
Ni une, ni deux, je me dis qu'il faut envoyer cela aux utilisateurs d'AVG, puisque le changement allait avoir lieu rapidement (15 octobre) et voilà à quoi sont confrontés les utilisateurs d'AVG, sur le site slashdot.org :
- l'accès à slashdot ne pose pas de problème, on tombe sur une page ressemblant à ça après avoir accepté les cookies :
page d'accueil slashdot.org
- Lorsqu'on fait une recherche du mot-clef AVG ça ressemble à ça :
recherche du mot-clef AVG sur slashdot.org
- Et lorsqu'on clique sur l'article en question, voilà ce qu'il ce passe :
AVG annonce un virus sur slashdot.org
Avant de conclure qu'il s'agit là d'une action d'AVG dont le but est d'influencer l'utilisateur, comparons ce qui est comparable, alors voici la dernière capture d'écran :
News sur slashdot.org à propos d'AVG
Comme vous le voyez, cette news est aussi prises sur yro.slashdot.org, le même sous-domaine, et contient aussi une news à propos d'AVG, par contre AVG ne se plaint pas ici... En conclusion, AVG est capable de faire du FUD (Fear (peur, je vous mâche le boulot ^^), Uncertainty (incertitude), Doubt (doute)) sur une seule page, non pas seulement un sous-domaine. On ne peut pas raisonnablement penser que cette action de la part d'AVG n'est pas grave. Un antivirus est un logiciel ayant beaucoup de droits, et les boîtes vendant ce type de logiciel se font une réputation sur la qualité de leur produit. Il serait malhonnête de prétendre que cette fenêtre d'AVG ne va pas influencer le lecteur à ne pas lire l'article (pour la plupart), voire ne plus retrourner sur le site, après tout, c'est un site anglais, ils sont très dangereux, et mangent peut-être les petits enfants.
Je pense qu'à ce point on peut conclure que le comportement d'AVG est objectivement biaisé, et cherche à censurer une partie de ce que les internautes lisent sur le web.
Quant au volet des CGU, eh bien je ne l'ai que rapidement parcouru.
AVG prétend que les informations collectées ne sont pas personnelles (ce qui est faux, il n'y a qu'à aller voir l'avis de la CNIL sur ce qui constitue une donnée personnelle, et vous verrez qu'elle considère, à raison, que l'IP, etc. en font partie) et ne sont pas partagées avec des tiers (ici, il faut leur faire confiance...) en tout cas il n'avait pas l'air de vouloir que la nouvelle du changement de politique de partage de données confidentielles se répande...
Quand c'est gratuit, c'est vous le produit. Bonne journée ! N'hésitez pas à commenter, linker l'article, faire des suggestions...
Motius
]]>Je parle bien sûr d'aujourd'hui 21 octobre 2015, jour qu'ont choisi Marty McFly et le Docteur Emmet Brown pour leur petite visite du futur dans le deuxième volume de la trilogie _Retour vers le Futur_.
Bon, le jour est déjà bien entamé, et pas d'apparition de Delorean volante aux infos, donc j'ai bien peur qu'un autre de nos fantasmes de gamin ne se soit évanoui. Enfin, grandissons un peu.
N'empêche que cette vision de l'année 2015 depuis l'année 1989 (26 ans, rendez vous compte !), même si manifestement différente de la réalité, reste pour le moins intéressante. Je ne vais pas vous faire l'affront de dresser une liste des différences, beaucoup de personnes plus talentueuses l'ont déjà fait.
D'aucuns vous diront que le futur imaginé en 1985 était beaucoup plus évolué que notre présent réel, d'autres affirmeront le contraire. Pour ma part, je pense que les deux évolutions se valent en norme, mais ont suivi des tangentes différentes. En effet, j'ai l'impression que le futur décrit dans le film poursuit la vision des années 80, avec un développement d'innovations hétéroclites, mais également réparties dans les différents domaines de la vie de tous les jours. On y met aussi l'accent sur les découvertes physiques, comme la lévitation, par exemple les voitures volantes ou le fameux overboard, qui a fait rêvé beaucoup de monde et qui a fait l'objet de plusieurs hoaxes.
Découvrez l'overboard dans la réalité par Gentside
Aujourd'hui, on se retrouve dans la réalité avec des innovations non moins négligeables, mais peut-êtres moins visibles et pas dans le même ordre.
Je rappelle que je ne fais que donner mon avis. Vous êtes libres de sortir dans la rue et d'observer la société par vous même, et de vous faire un avis en regardant le film.
Donc aujourd'hui, disais-je, mon impression est que le progrès a été nettement plus centralisé. On a focalisé nos efforts sur une technologie particulière (quoique vaste) qui est l'informatique et ses sous domaines, comme le big-data ou l'interface homme-machine, et on en a mis partout. Quand je dis partout, je veux dire partout. La liste des objets qui ne disposent pas d'un système d'exploitation standardisé se réduit à une peau de chagrin de nos jours, et c'est donc le règne de la micro et macro-informatique.
Ce qui découle aussi d'un phénomène plus global : au lieu d'inventer de nouvelles technologies, on a surtout perfectionné les technologies existantes : les voitures ne volent pas et roulent toujours au pétrole, mais elle sont plus sures et moins gourmandes (sauf exceptions).
Ce qui donne au final une image très différente de l'année 2015.
Mais bon, surtout, n'en voulons pas à Robert Zemeckis de s'être un peu trompé, franchement qui pourrait prévoir les évolutions de la société à presque 30 ans d'avance ? En tout cas, la science-fiction a entre autres pour rôle de stimuler l'imagination et de faire bouillir des neurones agités des scientifiques, ingénieurs, entrepreneurs, et finalement nous tous, car nous avons tous le pouvoir de faire changer la société, dans le bon ou le mauvais sens.
]]>Voici le premier tutoriel en temps réel présenté sur Hashtagueule. Il s'agit tout simplement de résoudre un problème "costaud" en plusieurs parties, qui sont publiées à chaques fois que l'auteur achève de formaliser son idée. Cette idée de temps réel reflète le fait que l'auteur travaille sur la solution en même temps qu'il écrit le guide.
Que les soucieux se rassurent, cela ne veut pas dire que les solutions présentées sont bancales ou non testées. À chaque partie publiée correspond beaucoup d'heures d'essais et de prototypage. Ne vous inquiétez pas, on sait rester pro chez Hashtagueule :)
Il va sans dire que vous êtes encouragés à partager vos propres solutions, demander des précisions, suggérer un détail ou réagir pour n'importe quel motif, en commentaires, sur les forums ou bien par IRC. Nous vous écouterons avec le plus grand plaisir et le plus grand intérêt.
Venons-en au fameux problème auquel j'ai été confronté il y a quelques semaines. Sa formulation en elle même est assez délicate, et les contraintes sont assez, comment dire, "contraignantes". Enfin bon, essayons tout de même.
Mettre en place une administration collective de plusieurs réseaux virtuels dont les adressages IP sont indépendants et possiblement conflictuels
Là. Je vous avais dit que la formulation était indigeste. Si vous avez tout compris du premier coup je vous en félicite. Pour les autres comme moi, voici une petite explication grosso modo.
- Il s'agit de donner un accès facilement révocable indépendamment à plusieurs personnes à plusieurs parcs informatiques. Une personne ayant été exclue de ce groupe ne doit plus pouvoir s'y connecter après coup.
- Les parcs informatiques sont gérés par des personnes indépendantes qui ont mis en place la plupart du temps un VPN pour que nous puissions nous y connecter. Ces VPN étant eux-mêmes indépendants, les conflits IP sont monnaies courantes (beaucoup d'adresses en 192.168.0.0/16 ou 172.16.0.0/16 par exemple).
- Les technologies de méthodes d'accès sont différentes d'un parc à l'autre. Par exemple on peut avoir du OpenVPN, VPNC, IPsec, etc. sur les VPN, et pour la connexion SSH on peut avoir de l'identification par clef ou par mot de passe.
Voilà, ça fait pas mal de contraintes, hein ? Ben devinez quoi, c'est l'objet de notre tutoriel.
La question qu'il est légitime de se poser à ce niveau, c'est : Mais Raspbeguy, à quoi ça peut bien servir, et pourquoi tu gaspille notre temps avec des inepsies pareilles ? À cela je vous répondrai que ce genre de problèmes ne sort pas spontanément de mon esprit dérangé, mais bel et bien d'une situation réelle, et en l'occurence bloquante. Les gens capables de concevoir des horreurs pareilles sont les entreprises offrant un support technique informatique à d'autres entreprises ayant une infrastructure relativement imposante. Si vous n'êtes pas dans ce cas, ne fermez pas tout de suite votre onglet ; si vous êtes un peu curieux, ce tutoriel pourrait vous donner des idées, car au delà d'une application précise, il permet de comprendre un peu plus certains mécanismes réseau et/ou Linux. Donc tout le monde y gagne :)
Et ce tutoriel, ma foi, nous ne le commencerons pas aujourd'hui. Non non. Mais bientôt je vous le promet. J'ai réfléchi longuement à ce problème pour le décomposer en sous-parties. Voici mon plan d'attaque :
- La gestion de conflits LAN to LAN : résoudre les problèmes de routage induits par les conflits exposés ci dessus.
- L'uniformisation des accès VPN, ou comment éviter à l'utilisateur de se prendre la tête avec 50 commandes faisant toutes la longueur de mon bras.
- La gestion des droits : autoriser un groupe de personnes à effectuer des actions précises et uniquement ces actions.
Donc je vous donne rendez-vous pour la première partie de ce tutoriel consacrée à la mise en place du terrain fertile pour y planter nos tunnels. En attendant, dites-nous ce que vous en pensez :)
]]>Aujourd'hui on va parler de SMSSecure et de TextSecure en tant que solutions de chifrement de textos. Avantages, inconvénients, architecture de chiffrement...
Comme d'habitude ans les échanges cryptographiques, on prendra Alice qui veut communiquer avec Bob, et Ève qui tente d'espionner (vous commencez à avoir l'habitude si vous lisez hashtagueule.fr régulièrement ;) ).
Fonctionnalités de base
Les deux application TextSecure et SMSSecure peuvent être utilisée par le grand public puisqu'elles fonctionnent même sans chiffrement. Elles servent alors de remplacement à l'application SMS/MMS par défaut de votre Android.
TextSecure et SMSSecure sont sous licence libre GPLv3 ! Vous pouvez vous en servir avec une grande confiance, et éventuellement donner aux développeurs de TextSecure et SMSSecure, si le cœur vous en dit.
Puisqu'elles sont sous licence libre, on peut plus facilement avoir confiance dans le chiffrement qu'elles proposent, ce que nous allons détailler ci-dessous.
Description du chiffrement
TextSecure est une solution de chiffrement développée par Open Whisper Systems, qui permettait le chiffrement de SMS et MMS sur mobile. Cette solution était d'assez bonne qualité, en voici les détails :
-
chiffrement de bout en bout : Alice chiffre (automatiquement, c'est mieux pour le commun des mortels) le message sur son téléphone avec la clef de Bob. Ainsi le message n'est jamais sur le réseau de manière non-chiffrée ;
-
pas de notion de session de chiffrement, à l'inverse de ce qui peut se faire avec XMPP + OTR : inconvénient : si Alice perd sa clef, tous les messages chiffrés par Bob peuvent être déchiffrés ;
-
l'application utilise le "TOFU" : Trust on First Use : c'est-à-dire que lorsque Alice parle à Bob, elle va d'abord initier une session chiffrée, et quelqu'un (Bob a priori) va recevoir le message d'initialisation. Alice va donc recevoir une clef de chiffrment à utiliser. À partir de ce moment, la conversation est chiffrée, mais pas authentifiée, puisqu'Alice n'est pas certaine de savoir à qui appartient la clef de chiffrement reçue. Il faudra donc qu'Alice rencontre Bob, ou quelqu'un qui connait la clef de Bob (et en qui Alice a confiance) pour que la conversation soit authentifiée.
Depuis quelques mois, TextSecure a abandonné le chiffrement des SMS pour ne garder que celui des MMS, ce qui a mis en rogne certains utilisateurs, ce pourquoi SMSSecure est né, forké du code de TextSecure. SMSSecure a donc la même architecture de chiffrement que TextSecure, mais diffère sur quelques points.
Alors SMSSecure ou TextSecure ?
Avantages de SMSSecure :
- SMSSecure chiffre aussi les SMS.
- Les SMS chiffrés par SMSSecure ne passent pas par des serveurs de Google (contrairement aux messages chiffrés de TextSecure, ce qui fait que Google a les métadonnées, mais pas les données. On se rappelle Edward Snowden qui nous a dit que les métadonnées était aussi importantes que les données).
- SMSSecure demande moins de permissions que TextSecure. Là il faudrait voir s'il y a un loup, mais je préfère une application qui demande moins de permssions.
Avantage de TextSecure :
- TextSecure passe par la donnée, donc peut potentiellement être utilisé à l'étranger par des correspondants de différents pays. À l'instar des applcations Hangouts de Google et iMessage de Apple.
- TextSeure est compatible avec l'application iPhone "Signal".
Comment passer de l'une à l'autre ?
(Attention ni hashtagueule.fr ni l'auteur de cet article ne sont responsables d'éventuelles pertes de données. Je décris ces mécanismes parce que j'ai un peu bidouillé, et n'ai eu absolument aucun problème).
C'est assez facile, mais cela requiert que vos contacts fassent de même, ce qui peut être un frein... Le processus pour passer à SMSSecure est le suivant :
- on installe SMSSecure ;
- on définit SMSSecure comme application par défaut ;
- on importe les SMS (si vous utilisiez une autre application sans chiffrement, comme l'application par défaut)
- on exporte les données de TextSecure ;
- on importe la sauvegarde de TextSecure à l'aide de SMSSecure.
Voilà. C'est propre et assez rapide (les phases d'import et export sont les plus lentes, durant à peu près 5 min chacune, en fonction du nombre de SMS/MMS).
Important : ne pas supprimer d'application SMS ni de données tant que vous n'êtes pas arrivé au bon résultat que vous souhaitez.
Mais pas de panique, si vous importez en double des SMS/MMS sur SMSSecure, il vous suffit de tout supprimer de SMSSecure et de recommencer les deux procédures d'import.
Il ne vous reste qu'à indiquer cette procédure à tous vos amis, et les inciter à utiliser SMSSecure.
Bonne journée !
Motius
]]>Aujourd'hui on s'attaque à un gros bout, le chiffrement de d'un bout à l'autre du réseau pour tous les utilisateurs.
(Dans tout ce qui suit, on ne parlera pas des mécanismes de "décryptage", ou de cassage de cryptographie, seulement de chiffrement (avec clef), et de déchiffrement (toujours avec clef). Un aspect important de cet article est de savoir qui possède la clef, et d'où à où le message est chiffré.)
Je vais donc décrire rapidement différents types de chiffrement, puis expliquer la problématique derrière le chiffrement pour tous.
Qu'est-ce que le chiffrement de bout-en-bout ?
Sur le réseau, l y a deux types de chiffrement :
- le chiffrement de bout en bout, pour lequel l'ordinateur A chiffre la donnée (page web, mail, clavardage XMPP, irc...), puis l'envoie sur le réseau, puis est reçue par B, qui la déchiffre, avec sa clef ;
- le chiffrement "par le réseau". L'exemple type est le mail. Quand vous utiliser Gmail, Yahoo, Outlook, Orange mail, etc. vous pouvez y accéder sur leur site web, via un webmail, ou à l'aide d'un client lourd, comme Thunderbird. Dans ce cas, les mails sont en clair sur les bases de données de Google, Yahoo, Microsoft, Orange... mais cependant les mails traversent le réseau de manière chifrée. Pour schématiser, ce sont les serveurs de mails qui s'occupent du chiffrement, de serveur en serveur, jusqu'à arriver à la boîte mail du destinataire.
Dans le second cas, la donnée chiffrée n'est pas accessible au plus grand nombre, mais ce mécanisme implique une confiance accordée aux tiers qui gèrent vos données. (Tiers dont le nombre se multiplie).
Dans la suite, on va parler de iMessage de Apple pour fixer les idées.
Le problème qu'on s'est fixé est : peut-on généraliser le chiffrement de bout en bout pour la majorité, et si oui, comment ?
Le mécanisme que iMessage utilise est du chiffrement de bout en bout, c'est-à-dire le premier mécanisme, ou le message est chiffré par une clef appartenant à l'utilisteur, puis passe sur le réseau, où personne ne peut le déchiffrer, puis est reçu par le destinataire, qui seul peut le déchiffrer.
Le problème, c'est que l'utilisateur ne gère pas ses clefs. Cela a des avantages et des inconvénients. L'avantage principal :
- plus de gens peuvent utiliser le chiffrement de bout en bout, un chiffrement de meilleur qualité que le mail, puisque pour le mail, il est possible qu'il ne soit pas toujours chiffré sur tout le trajet...
Les inconvénients (plus ou moins subtil) :
- les gens ne savent pas quel type de chiffrement ils utilisent, ou si le chiffrement est de bonne qualité ;
- il faut faire confiance à un tiers ;
- la partie la plus importante de cette article : je pense que cette crypto admet facilement une backdoor.
Je m'explique. Prenons Alice et Bob, qui veulent dialoguer, et Ève, qui veut espionner. Ève peut être n'importe quelle tierce personne, à l'inclusion de l'État, une entreprise...En effet, l'avantage du chiffrement de bout en bout, c'est que personne d'autre que les deux partis de la conversation n'y prend part. Autoriser l'État ou une entreprise revient à dire qu'on ne fait plus du chiffrement de bout en bout.
Pour qu'Alice chiffre un message, il faut qu'elle possède "la clef" de Bob. Problèmes :
- celle-ci est gérée par Apple ;
- s'il y en a plusieurs (une par appareil supportant iMessage, iPad, iPhone, iMac...), il faut qu'Alice les récupère toutes.
Vous m'avez vu arriver à des kilomètres.
Il est tout à fait possible qu'une mauvaise clef -- n'appartenant pas à Bob -- soit donnée à Alice. Je ne pense pas que ce soit ce qui se passe, puisqu'il faut alors changer le chemin que prend le message, le stocker sur un serveur, puis le rechiffrer avec la clef de Bob. C'est possible, mais il y a franchement plus simple.
Lorsque Alice envoie un message à Bob, iMessage récupère pour elle toutes les clefs de Bob. Il est tout à fait possible que iMessage récupère les n clefs de Bob, plus une clef appartenant à Ève. Ça y est. Sans avoir presque rien fait, on a backdooré iMessage, sans surcoût, sans grande difficulté, sans qu'Alice ni Bob ne s'en aperçoive.
C'est pourquoi je crains qu'il soit très difficile de mettre en place une solution de chiffrement de bout en bout pour le grand public.
Voilà, un petit tour du côté du chiffrement, de la manière dont on crée l'architecture des systèmes de chiffrement, et le problème reste ouvert pour comment avoir du chiffrement de bout en bout pour tous.
Bonne journée !
Motius
]]>Aujourd'hui, on va parler empreintes de fichiers. Petit tour du principe, des algorithmes, et des nouveautés...
Les empreintes digitales permettent d'identifier de manière unique un individu, cependant l'information contenue dans une empreinte est très faible par rapport à toute l'information que représente un individu.
De même, il existe en informatique un challenge comparable, qui consiste à permettre d'identifier de manière unique des fichiers. On utilise donc un algorithme qui -- en théorie -- est très sensible à la variations de bits dans un fichier, de telle sorte qu'il soit impossible -- ou presque -- que deux fichiers distincts aient la même empreinte.
Les cas d'utilisation d'empreintes sont nombreux :
- vérification rapide qu'un téléchargement ne comporte pas d'erreur ;
- identification d'un fichier dans un gestionnaire :
- git pour des fichiers source ;
- YouTube pour ses vidéos ;
- etc.
Beaucoup d'algorithmes ont été développés : MD4 (très vieux), MD5 (déprécié pour toutes les applications liées à la sécurité) SHA1 (pour Secure Hash Algorithm) SHA2, SHA3...
Dans la mesure de l'efficacité d'un algorithme, on distingue :
- la sureté, c'est-à-dire la capacité d'un algorithme de donner une empreinte différente pour deux fichiers différents ;
- la sécurité liée à l'algorithme, qui garantit qu'une attaque contre l'algorithme (soit en essayant beaucoup de fichiers, soit en trouvant une "fonction inverse") est quasiment impossible.
Ainsi, la sureté d'un algorithme correspond à la capacité de cet algorithme de détecter une modification du fichier. De MD5 à SHA-3, tous en sont relativement capable.
La sécurité de ces algorithmes est essentielle. Prenons Bob, et un attaquant Jeb. Le but de Jeb est de pouvoir créer un fichier ayant la même empreinte que celui attendu par Bob, pour pouvoir le substituer à celui que Bob a demandé sur le réseau.
Eh bien figurez-vous que la sécurité de SHA vient d'être une nouvelle fois remise en cause. Dès 2005, des chercheurs avaient réussi à trouver des collisions (ce qui se passe quand deux fichiers ont la même empreinte). Désormais, le site Ars nous parle d'attaques plus systématiques sur l'algorithme SHA-1.
Tout ceci est bien dommage étant donné que les navigateurs web (Firefox, Iceweasel, Chromium, Opéra, Chrome, ...) ont abandonné MD5 il y a peu (il n'est plus supporté), et que la fin de support de SHA-1 est prévue pour fin 2017.
En attendant, la relève est là (SHA-2, SHA-3) mais encore faut-il que les sites webs que vous visitez supportent SHA-2, ce qui n'est pas gagné. Seuls quelques rares utilisent les bons algorithmes au bon endroit (Wikipédia, Google, Twitter, ...)
Tout ceci arrive au moment même ou la NSA (la partie sécurité intérieure) rend obsolète AES-128 (pour AES-256) et SHA-256 (une des quatres version de SHA2 pour les documents classés Secret Défense :
- SHA-224
- SHA256
- SHA-384
- SHA-512)
pour SHA-384...
Bonne journée !
Motius
]]>Je vous avais déjà parlé ici des présidentielles US et plus particulièrement de Lawrence Lessig, candidat à l'investiture démocrate. Update et présages...
Petit rappel pour ceux qui ne prendront pas le temps de lire l'article précédent : Lawrence Lessig, avant d'être candidats à la présidentielle états-unienne, est un avocat spécilalisé dans le droit constitutionnel et la propriété intellectuelle, pour laquelle il a beaucoup œuvré sur internet en tant qu'activiste, avant de fonder les Creatives Commmons, essentiel au partage simplifié d'images sur internet.
Lawrence Lessig a réussi son pari. Récolter 1 million de dollars en 4 semaines de campagne de crowd-funding est extra, il ne manque que les lolcats et trololo pour réjouir notre génération internet.
La route est cependant très longue pour lui : il lui faut d'abord être investi par le parti démocrate ce qui va représenter une longue campagne, puis faire face aux candidats républicains.
Mais aussi loin que Larry soit allé, il me semble qu'il risque de se casser le nez sur la primaire démocrate. On va me reprocher de faire mon défaitiste, mais voici pourquoi. Les campagnes présidentielles se cristallisent souvent autour de quelques point principaux. On se rappelle :
- l'Obamacare ;
- Guantanamo ;
- le mariage homosexuel ;
- le retrait des troupes d'Afghanistan ;
- et quelques autres...
lors de la campagne de 2012.
Loin de moi de suggérer que c'est tout ce qui fait une campagne, à mon avis on ne peut pas faire une campagne sur un seul thème (la réforme du système électoral états-unien), surtout si on est là pour proposer la solution. Un parallèle pour vous montrer comme je vois ça : c'est comme si l'adminsys de la boîte prenait le rôle de PDG quelques mois le temps de gérer une attaque sur les systèmes d'information... Clairement il en est le plus apte, et ça s'est peut-être déjà vu... mais pas dans des grandes entreprises. Des startups à la rigueur.
Ce que j'espère donc, si Lawrence n'est pas investi par les démocrates, c'est qu'il aura réussi à initier un mouvement de sensibilisation autour de lui, et un courant au sein de son parti.
Motius
]]>La différence avec Manatori c'est qu'ils sont basés en France, donc ça évite pas mal de frais de ports, et le type de goodies est assez varié (pas que des T-shirts en fait). Bon, la variété des stocks est pour le moment assez limité, mais c'est normal, vu qu'ils n'ont ouvert qu'il n'y a que quelques semaines. D'ailleurs pour l'occasion, profitez-en, les frais de ports sont offerts pour une durée limitée.
]]>Ce post au titre ambitieux va traiter de quelques problèmes fréquents que vous avez pu rencontrer, et de leurs solutions par les gentils du net.
Les thèmes abordés seront le "logiciel libre" dans l'éducation, les "télécom" en tant qu'infrastructure, et "l'informatique" pour le commun des mortels (tout le monde sait qu'un pseudo UNIX est immortel ;) ).
Les idées de l'article sont indépendantes, puisqu'il s'agit-là d'une compilation de problèmes.
Le logiciel libre et l'éducation
Ce premier paragraphe vient faire écho à cet article (traduit) de Richard Stallman (rms). Dans la lignée du scandale Volkswagen qui invite à l'utilisation des logiciels libre, rms explique l'intérêt de la préférence du libre dans les écoles.
Je n'ai pas le niveau pour me comparer à rms (ni à l'excellent Eben Moglen), mais les idées développées par la fsf - quoique fondamentalement utiles pour le progrès du monde libre, et l'accessibilité de l'informatique à tous - sont généralement ou blanches ou noires.
Les deux différences entre "l'open-source" et "le libre", sont la philosophie qu'il y a derrière, et la licence.
- La philosophie du libre impose le partage. Si vous utilisez du logiciel libre que vous améliorez, il faut qu'il y ait des retours pour la communauté du libre. Le libre est un bien commun, en somme, une base sur laquelle on peut bâtir son petit bout de code.
- La licence -- la GPL par exemple -- qui va avec est donc différente d'une licence BSD. On peut fermer une branche de code sous BSD et s'approprier tout ce qu'on a construit dessus, la GPL dit qu non, et qu'il vaut mieux contribuer, puisqu'on a eu de l'intérêt pour du code ouvert que parce qu'il est de bonne qualité, à jour, compétitif industriellement parlant.
C'est pourquoi les licences ouvertes (libre ou open-source) sont a privilégier en termes d'éducation :
- l'ouverture incite à l'apprentissage et/ou la bidouille ;
- l'ouverture diminue les barrières à l'entrée ;
- les applications ouvertes sont l'exemple de ce qui se fait dans l'industrie (même Microsoft utilise Ubuntu !) ;
- l'école n'a pas à se soucier de licences ou droits d'auteurs qui :
- coûtent des sous ;
- posent des problèmes de compatibilité (pour C# disponible sur windows®), d'utilisation (pour les droits d'auteur), etc.
L'utilisation de solutions non-ouvertes posent plusieurs problèmes supplémentaires :
- dépendance des élèves à une plateforme ;
- dépendance des enseignants à un outil.
- risque de ne pas être assez général dans le domaine et ne parler que de l'outil propriétaire étudié (parler uniquement de Microsoft Access en cours de bases de données alors que MySQL de Oracle, et PostgreSQL ont une part de marché plus importante).
C'est pourquoi il devrait y avoir (sinon une exclusivité par trop utopique) une préférence marquée pour l'univers ouvert (libre ou open-source).
TL;DR : L'ouverture apportée par les logiciels libres (ou open-source) est bonne pour l'apprentissage, pour les élèves, pour les enseignants, pour donner une perspective et ne pas être enfermé dans un outils propriétaire, et partant, devrait être encouragée fortement.
Les réseaux : une infrastructure d'État
Vers la fin du XIXème siècle, la construction de l'infrastructure de réseau de chemin de fer a mobilisé jusqu'à 1/3 de l'épargne des français. Il s'est agit d'une entreprise complexe où cohabitèrent les directives de l'État, ses ingénieurs des Ponts-et-Chaussées, les entreprises privées -- chargées de la construction, du respect des normes et du tracé -- et enfin des capitaux actions des Français.
Le numérique est une révolution du même type, mais d'un ordre supérieur. Du même type, il s'agit entre autres d'une infrastructure réseau (fibre optique, réseau cuivre, antennes GPRS, EDGE, 2G, 3G, 4G, faisceaux hertziens...). D'un ordre supérieur, le numrique permet l'acheminement d'informations plus vite que la poste combinée au train et à l'avion. Mais le numérique n'est pas limité à l'infrastructure réseau, il implique aussi d'immenses espaces de stockages (bases de données, datacentres, fichiers de boîtes mails, etc.) et une intelligence au bout, l'ordinateur.
Le réseau de transport (ferré, routier, aérien...) n'a pas changé la nature de ce que l'on voulait changer : biens, personnes, objets à vendre ou vendus, etc. Le numérique si. Le numérique s'oppose à ce qui est analogique. Ce qui est numérique n'existe que sous forme de 0 et de 1. L'enjeu de la transformation entraîné par le numérique est donc beaucoup plus grand.
- Les gens font des albums photos, mais ils ne tiennent pas un serveur de photos en ligne avec une liste de permissions afin qu'untel puisse y accéder, mais qu'un autre se voie refuser cette possibilité. Ils utilisent facebook.
- Les films montrent la manière dont nos ancêtres (ça y est j'ai l'impression d'être vieux) géraient leur conversations épistolaires. Ils regroupaient les lettres par conversations et les rangeaient. Ça fait même l'objet de drames lorsqu'il y a du contenu compromettant dans l'une d'entre elles. Mais nous ne tenons pas de serveurs de mails. On utilise le webmail de son FAI, ou de Google, de Microsoft, de Yahoo...
Les exemples comme ceci sont légion. Mais le numérique a fait plus que cela. Avant le numérique, le coût d'une photo était bien plus grand. Une fois la photo prise avec son Kodak, il en restait une de moins sur la pellicule, que celle-ci fût réussie ou pas. On peut désormais les effacer. De plus les disques durs ont rendu le stockage bon marché.
Tout ça pour dire qu'il y a un changement de paradigme du fait du numérique, mais que certaines habitudes d'avant l'ère numérique n'ont pas subsisté. Parfois c'est une bonne chose, et parfois non. Et que d'autres habitudes on subsisté. Qui parfois sont utiles, parfois nuisibles dans ce "nouveau monde". (J'y reviendrais dans un prochain article, d'ailleurs).
Voyons où se situe le problème à l'aide de ces analogies (dont on a bien précisé qu'elles sont approximatives). Si la poste avait eu un service de bijoux concurrent de Baccarat, ou s'était associé à un concurrent de Baccarat, et qu'elle ralentissait de plusieurs mois l'acheminement des produits Baccarat, on trouverait cela intolérable, et cette pratique serait taxée de déloyale et non-concurrentielle. Sur un autre registre, si demain La Poste égare ou délaye l'envoi de tracts du PS, mais accélère celui du RPR (pardon de l'UMP) ce serait un scandale. L'existence même du CSA sert à garantir une forme d'équilibre du temps de parole à la TV des politiques, ce qui n'est rien d'autre qu'une égalité des chances de parler aux citoyens, étant donné que le nombre de chaînes hertziennes de TV est limité.
Eh bien dans le monde numérique -- notre monde, le nôtre à tous, sans peut-être que vous vous en soyez rendu compte -- La Poste, ce sont nos FAIs (Orange, Bouygues, SFR, Numéricâble, Free...), et le concurrent de Baccarat ce sont les grands hébergeurs du web. Google, Facebook, Microsoft, Apple, Twitter, Amazon. Le fait qu'un FAI privilégie le trafic vers un hébergeur plutôt qu'un autre pose le même problème qu'avant. Problèmes de censure, d'accès à l'information, de pratique déloyale et non-concurrentielle.
Empêcher cela porte un non : La neutralité du net. La neutralité du net préserve l'accès à l'information. Préserve la concurrence.
Vous pouvez souffler un peu, on a déjà fait un gros bout, mais la neutralité du net n'est même pas l'objet de cet article, même s'il est essentiel d'en comprendre les enjeux pour la suite.
J'en reviens au tout début de cette seconde partie : l'infrastructure qu'est un réseau de communication. Si ce sont des entreprises qui vendent du contenu qui créent les infrastructures qui délivrent le produit, ça pose problème. Imaginez que le premier marché de La Poste fût la vente de bijoux et non pas d'être un réseau de transport. Du jour ou La Poste devient un moyen de transport d'objet et est le seul moyen de véhiculer les objets, Baccarat a un problème. ce problème existe maintenant, il prend deux formes :
- l'association de certains opérateurs avec des boîtes pour leur garantir, moyennant finance, une priorité dans leur réseau ;
- le fait que des distributeurs de contenus se lancent dans le réseau informatique. Je pense bien évidemment à Google Fiber, pour l'occident, et aux drones de Facebook pour leur projet internet.org (qui vient d'être renommé), et aux ballons stratosphériques de Google. Ces deux derniers projets permettent à des pays en voie de développement d'accéder à l'internet, ce qui est une bonne chose, tant que l'on légifère dessus. Pour chaque pays.
Vous le voyez, le passsage au numérique est un sujet complexe, mais il existe des moyens pour s'en sortir bien. En ce qui concerne cette partie, les solutions (à choisir dans une gamme de solutions) ressemblent à pas mal de neutralité du net, plus une pincée de législation sur l'investissement pour les infrastructures réseau. Que Google et Facebook s'enrichissent en proposant un service d'hébergement et un service de FAI, pas de problème. Tant qu'il y a des garanties apportées. Elles sont synonymes d'une très grande transparence. À l'inverse, un État informé pourrait faire un choix plus souverainiste. Mon but étant toujours un choix informé.
TL;DR : Entre opérateurs réseaux et fournisseurs de contenu, il y a un grand enjeu pouvoir de distribution de l'information et de concurrence. L'un des aspects importants est la neutralité du net, l'autre la nécessité d'une loi par État régissant leurs rapports, et l'évolution de l'infrastructure.
La responsabilité sociale de l'univers informatique
Les gens ne gèrent plus leurs mails ? Très bien. C'est dommage, mais c'est ainsi. Les gens ne gèrent pas d'albums photo en ligne ? Très bien. C'est vraiment dommage, mais c'est ainsi.
De nombreux acteurs sont nés du numérique, et ce domaine s'est complexifié -- on a vu tout à l'heure que le numérique pris largement regroupe le réseau, le stockage, le logiciel, l'informatique... De cette complexité et cette richesse provient l'ignorance relative du vulgus pecum en matière de numérique. Plus qu'aucune autre discipline spécialisée, un contrat social est nécessaire entre les utilisateurs et "les adminsys" (plutôt les décideurs des grandes plateformes du web).
Les parallèles, c'est bien, ça fixe les idées. Allons-y.
Si je me fais arnaquer par mon banquier (ou si vous criez à la tautologie), la confiance que je vais accorder dans les métiers liés à la finance, etc. va baisser.
De même, si les personnes qualifiées (ou douées) dans des domaines IT sont les seules à pourvoir échapper à certains abus que l'on rencontre sur le web, la confiance générale diminuera.
On peut voir ceci de deux manières :
- soit sous forme d'un équilibre, les gens se font avoir, puis commencent à se méfier, et continuent à utiliser l'outil, mais moins. De même, les non-banquiers se font roulers, les agents immobiliers festoient comme des vautours sur les non-initiés, etc. et chaque profession pratique son propre corporatisme.
- Soit on essaie d'établir une sorte de renouveau de contrat social, où chacun se voit attribuer un traitement équivalent.
À mon avis, tout ceci tient toujours de l'équilibre. Mais on peut faire plus ou moins d'effort dans la transparence.
La raison pour laquelle ce contrat social est si important pour le domaine informatique est qu'il touche littéralement toutes les professions, en plus de tous les gens.
TL;DR : notion de responsabilité d'une profession envers les non-initiés, au moins a minima. afin de préserver un équilibre, un certain contrat social et éviter un corporatisme des professions.
Voilà, c'est tout pour aujourd'hui, long article qui m'a pris pas mal de temps. Des bouts de cette réflexion se retrouveront dans un prochain article, n'en doutez pas ;). N'hésitez pas à commenter l'article, les idées à rajouter des exemples qui vous paraîtraient pertinents. Bonne journée !
Motius
]]>Les mises à jour logiciel c'est bien ! En tout cas dans le monde du libre, où elles sont généralement bien gérées, et que mises à jour rime avec nouvelles fonctionnalités...
Eh bah ? Qui s'est déconnecté ? Ah oui, ceux qui font la mise à jour de leur Firefox ! Bon, d'accord, mais n'oubliez pas de revenir lire la fin de l'article pour voir les nouveautés !
Dans Firefox 41 (la version stable au 24 septembre) la fonctionnalité principale est l'ajout de la fonction clavardage (le mot français pour "chat") intégré à Hello. Pour ceux qui ne connaissent pas Hello, il s'agit de la fonctionnalité de WebRTC de firefox qui permet de faire des conférences vidéos sans autre logiciel que Firefox (non, je ne citerai pas le trop connu logiciel racheté par Microsoft, et dont les serveurs ont eu une panne lundi), et sans plugin.
Je ne sais pas vous, mais moi j'aime beaucoup le WebRTC. On n'a pas de logiciels à installer. Et puis je l'ai testé et utilisé depuis qu'il est arrivé dans Aurora, la version alpha de Firefox, en septembre dernier.
La deuxième mise à jour est l'apparition de l'icône de son sur l'onglet qui joue un média - très attendue, d'autant qu'elle est déjà sur chromium m'a-t-on dit.
Et pour ceux qui comme moi regardent un peu les autres versions de Firefox 42.0b1 sur le canal Bêta vous avez vu que désormais Firefox bloquera activement le contenu qui vous tracke sur internet dans les onglets de navigation privée.
Il s'agit d'une petite feature très sympa et dont le développement a été progressif, puisque Firefox bloquait déjà des éléments depuis un certain temps. Pas de panique en tout cas, puisque Firefox vient avec un tuto visuel très simple.
Bonne navigation ! N'hésitez pas à commenter.
Motius
]]>Vous avez sans doute entendu parlé de l'affaire Volkswagen depuis lundi, en tous les cas c'est une bonne occasion pour faire un point sur l'affaire...
Volkswagen est un grand groupe. Il possède notamment Audi, Porsche, et Lamborghini (et non pas l'inverse, c'est bizarre, mais c'est comme ça. Les marques luxueuses vendent cher leurs voitures, mais sur un petit marché), devenue en 2015 plus grand groupe mondial, devant Toyota.
Mais qu'est-ce qu'il s'est passé ? Pour ceux qui n'ont pas suivit, lundi matin on a eu confirmation d'une rumeur qui courait depuis vendredi 18 : que VW ment sur les émissions carbones de ses voitures diesel. 500 000 voitures pourraient être rappelées aux États-Unis, l'action VW a ainsi perdu 16% d'entrée entre le vendredi soir et le lundi matin (162.20 --> 139.95).
Tout ceci est une grande histoire (VW risque en plus une amende aux États-Unis, le patron ne voulait pas démissionner, mais l'a finalement annoncé aujourd'hui par peur d'être viré vendredi...), mais allons à ce qui nous intéresse :
- le logiciel ;
- et bien sûr, les bêtises qu'internet à pu faire cette semaine ^^.
En ce qui concerne le logiciel, ça prouve qu'on ne peut jamais faire confiance à du logiciel dont on n'a pas la facture, si c'est pas libre, c'est pas sûr. Imaginez des machines à voter faites ainsi... Je place cet exemple ici parce que ce sujet revient souvent, mais les médias n'ont pas toujours la mémoire des incidents, et la méfiance qu'il faut avoir. Le dire à ce moment aura peut-être plus d'effet...
Et enfin, la catégorie que vous attendiez tous, les parodies !
- ma favorite ;
- la réaction de Greenpeace ;
- cette vieille publicité ;
- très très dur.
{kind=link}
{kind=link}
{kind=link}
En conclusion, j'aimerais revenir sur un de mes dadas. Certains critiquent le logiciel libre en disant qu'il ne devrait pas être nécessaire à l'utilisateur d'avoir à mettre les mains dans le cambouis. C'est vrai. Ils disent souvent "est-ce que tu as besoin de savoir comment une voiture fonctionne pour t'en servir ?" "non". Néanmoins il est nécessaire que des gens puissent vérifier que le moteur de la voiture fait bien ce que le constructeur dit. Pour éviter des mensonges sur la quantité de polluants dans le cas des voitures. Idem pour le logiciel. Il est nécessaire de savoir exactement ce que le logiciel est censé faire. Pour le modifier, l'améliorer. Et éviter les backdoors, etc. À ma connaissance, il n'y a pas ou peu de contrôle sur les logiciels fermés (de Microsoft, Apple, Adobe...) et c'est même limité par une clause légale interdisant le reverse-engineering. Voilà matière à penser.
Bonne journée, n'hésitez pas à commenter, partager vos images/vidéos favorites du moment...
Motius
PS : le slogan de Audi est "Vorsprung durch Technik" c'est-à-dire le progrès par la technologie, amusant leur choix de techno ? ;-)
]]>"Le Petit Prince" est un phénomène à lui tout seul. Pour moi, il s'agit d'un monstre sacré de mon enfance, mais un tour sur la page Wikipédia montre qu'il s'agit du deuxième livre le plus lu et le plus traduit, derrière la Bible. Alors ! Mais il y a aussi derrière une sale histoire de droits d'auteur : en effet le livre est dans le domaine public au Japon et Canada depuis 1995, dans le reste du monde (sauf la France) depuis le 1er janvier 2015, et une guerre sévit en France par les ayants-droits pour obtenir un droit perpétuel sur Le Petit Prince en déposant une marque.
Mais passons, l'heure n'est pas à la polémique, mais à la détente.
L'actualité du jour, c'est le film d'animation Le Petit Prince sorti cette année. hashtagueule revient sur le film... (Attention, SPOILERS)
Le film est construit autour du bouquin, et c'est plutôt une bonne chose. Si je devais résumer l'idée qui conduit le film, je dirais qu'il montre la réception de l'histoire du Petit Prince dans un monde imginaire.
La nouveauté, c'est donc l'univers dans lequel l'action principale se passe. Et là une bonne surprise : il s'agit d'un monde uniforme, où l'on recommande à tous "d'être essentiel", la compétition pour entrer dans l'académie de ses rêves commence beaucoup trop tôt - tous les éléments nécessaie pour un monde absurde.
trois moins bonnes surprises arrivent peu après :
- dans la série de planètes que le petit prince visite en partant de son "Astéroïde B612", il ne visite pas le buveur, et j'adore le dialogue qu'il y a à ce moment du livre, et ce volet de l'absurde ;
- il ne visite pas non plus l'allumeur de révèrbères ;
- les visites chez le roi et le businessman sont quelque peu altérées :
- le roi n'a pas côté mi-sage où il ordonne au soleil de se coucher, mais au tempo du soleil ;
- le businessman n'est pas seulement l'être absurde qui amasse étoile sur étoile et galaxie sur galaxie, mais il a aussi une prétention à un pouvoir tyrannique.
C'est vraiment la seule chose que je reprocherai au film. Il est très bien, a de bonnes animations, une bonne idée pour faire un film à partir du livre, mais il déforme le message du livre. Je suppose que c'était dur de résister à la tentation de faire un "grand méchant du film", qui rend l'avancement de l'action plus facile.
Au rayons des bonnes surprises, c'est un vieux papi un peu lunatique qui apporte l'histoire du Petit Prince à l'héroïne. Le scénario est vraiment classique avec la jeune fille qui est d'abord intéressée par l'histoire, puis la rejette, a des remords, et comprend le message, essaie de réunir le Petit Prince avec le vieillard, the end.
En conclusion, je dirais que Le Petit Prince est un bon film pour les enfants, et ceux qui ont réussi à le rester, qu'il a l'avantage de perpétuer l'histoire pour les plus jeunes, même si je recommande le livre (ou le PDF ;-) )
Bonne scéance, et n'hésitez pas à commenter !
Motius
]]>L'épée contre le bouclier symbolise un éternel équilibre dans une guerre, mais à la fin, qui gagne ? Aujourd'hui je vous propose d'aller jeter un coup d'œil du côté d'un de nos outils favoris : l'internet, ses monts et merveilles, et le reste...
La plupart d'entre vous êtes familiers des concepts que je vais décrire dans cette première partie, mais elle me semble essentielle afin que l'on parte d'une base commune.
Quelques définitions...
Je vais essayer d'être suffisamment clair pour qu'il vous soit inutile de suivre les liens indiqués dans l'article, cependant je les inclus à toutes fins utiles.
Internet : Il s'agit d'un réseau physique reliant des machines. En gros des tuyaux transportant de l'information, normalement sans en modifier le contenu (donnée). Schématiquement, il n'existe que deux objets sur internet :
- des ordinateurs ;
- des "câbles" (fibre optique, réseau cuivre, antennes 3G, 4G, ...).
Internet est en fait un réseau de réseaux : chaque opérateur internet (FAI) construit son bout de réseau, qu'il interconnecte ensuite aux autres (il y a pas mal de questions de taille d'opérateur, de gros sous, d'organisation des réseaux, mais on va faire simple). L'étymologie du mot internet décrit cela : il s'agit d'une interconnexion (inter) de réseaux (network).
Cela dit, dans tout cet article, une représentation schématique à peu près équivalente d'internet sera utilisée (vous pouvez cliquer pour afficher les images taille réelle dans un nouvel onglet) :
Représentation d'un réseau physique de machines. Schéma simplifié d'internet. CC-BY-SA
Web : réseau virtuel de machines. Ce réseau utilise l'infrastructure qu'est l'internet. Il est constitué de deux types d'objets :
- les machines client-web. Celles-ci peuvent demander du contenu (via le protocole HTTP) ;
- les machines serveur-web. Celles-ci proposent du contenu.
Il est tout à fait possible pour une machine d'être à la fois client-web et serveur-web. Le web peut être vu comme une sous-partie d'internet, tous les ordinateurs connectés pouvant théoriquement proposer et demander du contenu. Le web est un réseau virtuel.
Protocole : manière qu'ont plusieurs ordinateurs de communiquer. HTTP est un protocole du Web. De manière non-exhaustive, les protocoles incluent HTTP/HTTPS, FTP, BitTorrent, SSH...
Serveur : une machine qui propose du contenu ou service. Exemples, un serveur web propose des pages web (via le protocole HTTP/HTTPS), alors qu'un serveur proxy effectue des requêtes à votre place de telle sorte qu'il semble que c'est lui et non pas vous qui a effectué la recherche.
Client : une machine qui demande du contenu ou service. La majorité des internautes ne sont que clients.
Donnée : de l'information. (Volontairement court : une méta-donnée est de la donnée, et peut très bien être considérée comme de la donnée pure, selon le contexte).
Méta-donnée : de l'information à propos d'une information ou personne, objet... Exemple : les métadonnées d'une image sont :
- la date ;
- l'heure ;
- le type d'appareil photo ;
- la géolocalisation (éventuellement).
Ce concept est complexe. En effet si une image passe sur internet, les métadonnées des paquets IP sont les adresses IP source et destination (etc.), et les métadonnées de la photo sont des données sur internet.
Chiffrement : Le fait de transformer une donnée numérique à l'aide d'algorithmes mathématiques afin de la rendre indéchiffrable pour quiconque en dehors de la personne à qui la donnée est destinée.
Déchiffrement : le fait d'obtenir les données en clair à partir du flux chiffré.
Décryptage : opération qui consiste à essayer de casser le chiffrement protégeant de la donnée.
Empreinte (hash) : suite de caractère identifiant de manière unique de la donnée à l'aide d'un algorithme. Les algorithmes utilisés actuellement sont : MD5 (vraiment obsolète, et déconseillé), SHA-1 (en voie d'obsolescence depuis 2015, le plus utilisé), SHA-2 (assez peu utilisé), ou SHA-3 (usage vraiment marginal).
Signature : le fait d'authentifier les données. Cette opération se fait en deux temps : le serveur réalise une empreinte des données, puis il signe l'empreinte. Vérifier l'intégrité des données consiste à effectuer l'empreinte et vérifier la signature.
Comment les mathématiques contournent le droit.
Comme d'habitude, je vais essayer de présenter les faits le plus objectivement possible (ce qui sera assez facile, étant donné qu'il s'agit d'abord d'un sujet technique) puis émettre une opinion - bien personnelle, comme toujours - que je vous encourage à critiquer dans les commentaires.
Le fil de cet article sera le suivant :
- tout d'abord, je vais présenter les principes du réseau d'anonymisation (ici tor que la majorité d'entre vous connaît) ;
- puis les principes mathématiques des techniques de chiffrement puissant de nos communications (PFS, OTR, GPG/OpenPGP/PGP...) ;
- et enfin les principes mathématiques pour rendre improuvable l'existence d'une donnée (utilisés par TrueCrypt, CypherShed, VeraCrypt).
(En fait l'idée de nouvelles possibilités à l'aide des mathématiques n'est pas nouvelle : le principe du VPN ou du chiffrement permet de s'abstraire du risque d'un réseau non sécurisé en soi...)
Du réseau d'anonymisation
Un petit schéma aidera à mettre les idées au clair, mais pas si vite ! Rien ne vaut un petit parallèle avec ce que vous connaissez déjà...
Lorsque vous chargez une page web en HTTP (flux non-chiffré, non-signé) il se passe ça :
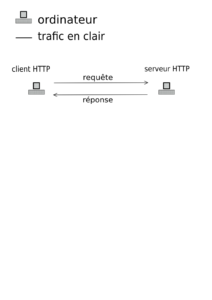
Trafic HTTP (Web). Requête, réponse. CC-BY-SA.
La suite d’événement est :
- le client parle au serveur (connexion) ;
- le serveur dit "je parle HTTP" ;
- le client demande la page web identifiée de manière unique par une URL ;
- le serveur répond :
- "200 OK", s'il l'a, puis la transmet ;
- "404 Error", s'il ne l'a pas (la très fameuse "Erreur 404" que tout le monde connaît, et facile à obtenir, il suffit de demander une page qui n'existe pas à un serveur).
De même, demander une page web en HTTPS, ça se représente comme ça :
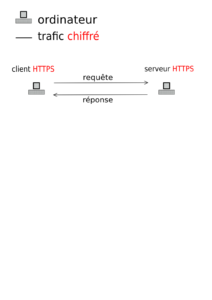
Trafic HTTPS (Web). Requête, réponse. CC-BY-SA.
La suite d’événement est presque identique :
- le client parle au serveur (connexion) ;
- le serveur dit "Je parle HTTPS" ;
- le client demande en HTTPS l'URL ;
- le serveur répond :
- "200 OK", s'il l'a, puis l'envoie
- "404 Error", sinon.
Deux différence entre HTTP et HTTPS, avec HTTPS :
- le trafic est chiffré (impossible de lire) ;
- le trafic est signé (impossible d'altérer le contenu, s'il était modifié, le client jetterait les paquets IP et les redemanderait).
Eh bien utiliser tor, ça ressemble à ça (décrit ici par le projet tor) :
Trafic tor. CC-BY-SA.
C'est-à-dire que tor fonctionne comme s'il y avait au minimum (parce qu'il peut y avoir plusieurs nœuds milieu en théorie) trois proxy (ou intermédiaires) entre nous et le serveur que l'on interroge.
Tor est ainsi un réseau virtuel de machines serveur appelées "nœud". Il y a trois type de nœuds :
- entrant ;
- milieu ;
- sortant.
Le trafic ressemble donc à ceci :
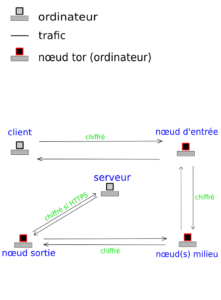
Apparence du trafic avec tor. CC-BY-SA.
Une représentation complète de l'internet avec du trafic tor serait :
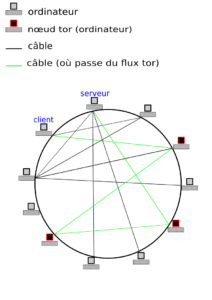 ](https://hashtagueule.fr/assets/2015/09/tor.png)
](https://hashtagueule.fr/assets/2015/09/tor.png)
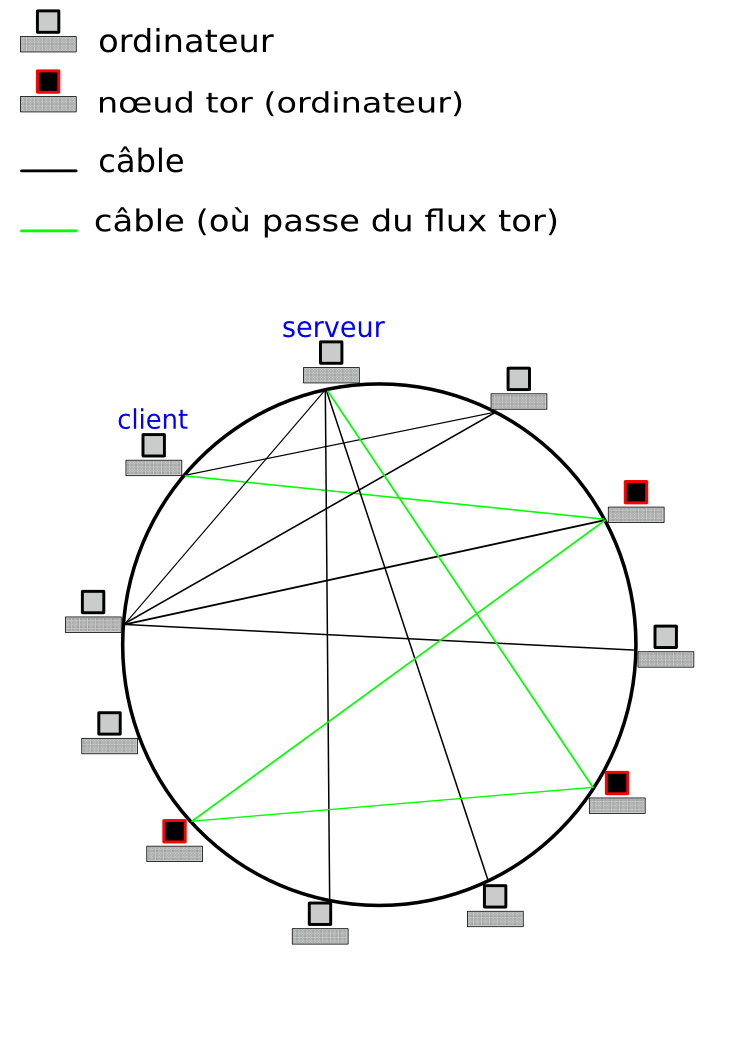{kind=link}
Trafic tor sur internet. CC-BY-SA.
Utiliser le réseau tor permet donc un anonymat de très grande qualité, en effet :
- le FAI qui relie l'abonné ne voit que du trafic, qu'il peut identifier comme étant du trafic tor, même en HTTP ;
- le serveur ne sait pas qui a demandé sa page ou son service ;
- le nœud d'entrée ne connait que l'utilisateur, pas le contenu (même en HTTP) ;
- le relais milieu ne connaît que ses voisins (ou les relais milieu...) ;
- le nœud sortie connaît le nœud milieu et le serveur interrogé, et voit :
- soit du trafic HTTPS indéchiffrable ;
- soit le trafic HTTP demandé, en clair.
Ainsi l'utilisation de tor, par le grand anonymat qu'il permet, empêche de relier un utilisateur au trafic qu'il a demandé.
L'utilisation de tor fait donc disparaître les informations liées à une connection : les métadonnées.
Une communication irrémédiablement chiffrée
Une communication chiffrée, une clef de chiffrement. Une idée gargantuesque consiste à enregistrer, au niveau d'un État, tout le trafic chiffré qui passe, et de l'analyser après, avec plusieurs idées derrière la tête :
- on trouvera peut-être des failles dans les protocoles de chiffrement actuels ;
- les utilisateurs perdront/divulgueront peut-être leur clef ;
- dans le cas d'une enquête légale, on demandera les clefs de chiffrement.
Eh bien les beaux jours des clefs perdues sont terminés (ou presque). En effet, dans un échange de clefs de type Diffie-Hellman :
- même si l'on perd les clefs ayant servit à un échange chiffré ;
- même si tout le trafic chiffré a été enregistré,
la conversation ne sera pas déchiffrable. Expliquons le procédé.
Il s'agit d'un échange de clefs de chiffrement au travers d'un réseau non sécurisé (internet) sans divulgation d'information. Pour le décrire, je vais procéder comme Wikipédia, à l'aide de couleurs :
- Alice possède une couleur secrète A, et tire au hasard une couleur A' ;
- Bob possède une couleur secrète B, et tire au hasard une couleur secrète B',
puis :
- Alice mélange A et A', qui donne A
''; - Bob mélange B et B' qui donne B
'',
puis
- Alice envoie A
''sur le réseau ; - Bob envoie B
''sur le réseau,
ces couleurs peuvent être "entendues" (par un tiers espionnant) sur le réseau, si le réseau est enregistré, puis :
- Alice mélange B
''avec A'', et obtient C = (A + A' + B + B') - Bob mélange A
''avec B'', et obtient (A + A' + B + B') = C !
Ainsi :
- Alice et Bob ont réussi à créer un couleur C inconnue pour le réseau ;
- De plus, cette couleur est temporaire : Alice et Bob ont tiré pour cette communication A' et B' ;
- En enfin, cerise sur le gâteau, on ne peut pas déchiffrer la conversation sans avoir à la fois A' et B', qui sont supprimées par Alice et Bob, puisqu'il s'agit de clefs temporaires. Même si l'on obtenais B' de Bob, il manquerait toujours A'.
En conclusion, Alice et Bob ont un moyen de communiquer qui empêche le déchiffrement a posteriori. Au niveau du réseau, la reconstitution de l'échange est devenue impossible.
Cette fonctionnalité s'appelle PFS (Perfect Forward Secrecy : confidentialité persistante) pour le web, OTR (Off-The-Record Messaging : messagerie confidentielle) pour la messagerie instantanée (utilisant par exemple le protocole XMPP).
Ici, ce sont les données de la conversation qui disparaissent.
Information, existes-tu ?
Un autre recours de l'enquête est la perquisition : physiquement aller voir l'information. Dernière déception pour les tenants du contrôle, ça n'est plus possible. Un mécanisme appelé "déni-plausible" consiste à pouvoir cacher si bien une donnée qu'il devient impossible de faire la preuve de son existence. Plongée dans les profondeurs du mystère...
Ces technologies sont très fortement associées à des logiciels, et à une actualité liée (probablement) à la NSA, mais à hashtagueule on a prévu de rester, donc on va faire court, quitte à revenir là-dessus sur une prochaine news. Je parlerai indifféremment de TrueCrypt (et ses descendants VeraCrypt, CypherShed, et j'en passe) comme synonyme du déni-plausible pour la clarté de l'article, mais ces logiciels permettent bien plus.
Rien ne vaut un exemple : TrueCrypt permet de créer des volumes chiffrés, ainsi :
- Ève crée un volume A de 100 Go de données personnelles, chiffré avec une clef α ;
- elle crée un sous-volume E de 100 Mo de données très confidentielles, chiffrées avec une clef ε.
Si quelqu'un accède à cet ordinateur, il verra le volume A chiffré, et ne pourra pas accéder aux données. Si ce quelqu'un est la justice, elle peut l'obliger légalement (même article que plus haut) à lui donner accès à ses clefs de chiffrement. Il lui suffit de ne donner que la clef α à la justice, et elle ne verra que le volume A de 100 Go (moins 100 Mo). Le sous-volume chiffré sera toujours inaccessible, et qui plus est, il ressemblera toujours à des données aléatoires, comme avant le déchiffrement de A. (Les données de E ne sont pas protégées contre la destruction, mais c'est une autre affaire).
Ainsi, l'existence de données dans E n'est pas prouvable, et il est même plausible qu'il n'y ai rien à cet endroit. C'est comme cela que l'on peut cacher des données.
En conclusion
Vous m'avez probablement vu arriver avec mes gros sabots, mais je vais quand même récapituler :
- on peut stocker une information sans qu'elle ne soit jamais accessible que par son propriétaire (3ème paragraphe) ;
- il est possible pour deux personnes de communiquer sans que leur trafic ne soit jamais déchiffrable (décryptable, c'est une autre affaire) (2ème paragraphe) ;
- il est possible pour deux ordinateurs de communiquer sans qu'aucun acteur du réseau ne le sache (1er paragraphe).
La totalité de la conversation a donc disparu des radars : les métadonnées de la conversation, le contenu de la conversation, et la copie locale sauvegardée.
Tout ceci est possible, là, maintenant, avec des logiciels open-source (ou libres) dont le code source (c'est-à-dire l'application logicielle de la formule mathématique, avant d'être traduite en langage ordinateur) est disponible au téléchargement (vous utilisez peut-être de la PFS avec hashtagueule.fr sans le savoir).
La conclusion (personnelle, vous le rappelez-vous ?), c’est qu’on ne peut gagner le volet numérique de la guerre contre le terrorisme par les seules voies législatives ("When you have a hammer, everything looks like a nail" ;-) ).
{kind=link}
Encore un dernier exemple (fictif celui-là) pour illustrer le pire des cas : un groupe terroriste qui est la tête-pensante, cherchant à radicaliser des jeunes, en vue d'en faire des terroristes. Son outil numérique ultime consiste à faire une solution logicielle reprenant les trois concepts, de faire le tout de manière décentralisée, et d'automatiser le processus de distribution.
Les derniers points que j'ai survolé :
- le côté open-source donne l'assurance du code qui est exécuté ;
- le côté décentralisé délivre de la nécessité d'un tiers (pour les mails, le chat...)
La vraie conclusion est qu'il ne faut pas faire de bêtises en matière de numérique, parce que tout ce que j'ai écrit n'est qu'une compilation d'informations publiquement disponibles sur internet, et maintes fois redondées.
N'hésitez pas à commenter et donner votre avis dans la section commentaires !
Motius
]]>
Rassurez-vous, vous pourrez bientôt contrôler toutes vos machines avec un seul couple clavier/souris. Souvenez-vous de l'adage : Think with portals.
Vous y arriverez grâce à Synergy. Il s'agit d'un logiciel multi-plateforme sous licence GPL même s'il vous suggère très lourdement de le payer. En tout cas, vous pouvez l'obtenir gratuitement sur les dépôts par défaut Debian/Ubuntu.
Il existe plusieurs manières d'utiliser Synergy sur Linux, dont une en lignes de commandes. Je vous conseille d'utiliser le paquet Quicksynergy également présent sur les dépôts Debian/Ubuntu.
Pour le configurer, rien de plus simple. Vous devez faire en sorte que vos machines soient accessibles l'une à l'autre (être sur le même réseau local est amplement suffisant) et connaître vos adresses IP ou vos noms d'hôtes.
L'idée est que vous allez configurer un serveur qui partagera son clavier et sa souris, sur lequel vont se connecter des clients. Dans le cas de ma configuration, mon serveur s'appelle fluttershy.local et j'ai un client qui s'appelle pearl.local.
Côté serveur, voilà ce que ça donne :
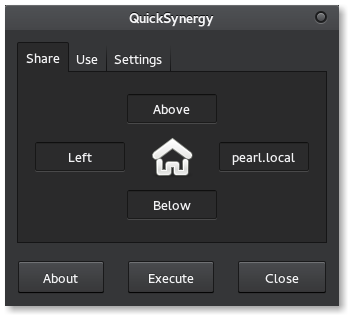
Cela signifie que l'écran de mon client se situera à droite de l'écran du serveur, c'est-à-dire que je devrai déplacer ma souris vers le bord droit de l'écran serveur pour aller sur le client et que le curseur y apparaîtra sur le bord de gauche. Enfin j'imagine que vous saisissez.
Remarquez que vous pouvez configurer jusque 4 clients qui peuvent être placer également à gauche, en haut et en bas. Il aurait été amusant de penser à une catégorie de machine entre le client et le serveur pour relayer l'autorité du serveur et pouvoir ainsi avoir jusque carrément un mur entier d'écrans, mais là je deviens un peu trop mégalo.
Du côté clients, voici la configuration :
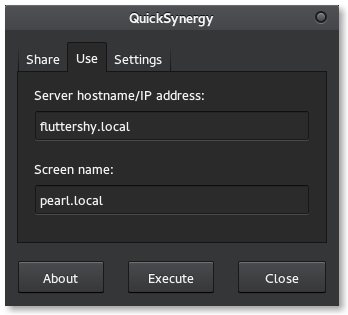
Cliquez finalement sur "Execute" d'abord sur le serveur, puis sur les clients.
Et voilà, fini les brouettes de claviers et les câbles de souris qui s'emmêlent. Votre installation se comporte exactement comme une seule machine avec plusieurs écran, sauf que chaque machine dispose de ses applications propres !
Attention cependant, avec la version GPL de Synergy, il est impossible de sécuriser les liaisons directement depuis l'interface. Il est néanmoins possible de les sécuriser un peu en créant un tunnel SSH, référez-vous à ce tutoriel.
Vous avez aimé cet article ? N'hésitez pas à le partager à d'autres gentils du net et découvrez-en d'autres sur hashtagueule.fr.
]]>Aujourd'hui sur la toile, le mot WikiGate circule. Mais de quoi ça s'agit-il donc bien ? Heureusement l'équipe hashtagueule est là pour mettre au clair tout ça.
Vous aurez tous reconnu la formation du mot-clef Wikigate à partir de Watergate, ce scandale à propos d'écoutes aux États-Unis. Apparemment, c'est devenu traditionnel d'utiliser le suffixe -gate pour désigner des scandales ou de grands débats sur la toile.
De quoi est-ce que relève ce Wikigate ?
Connaissez-vous Elsevier ? Il s'agit d'une maison d'édition qui publie des articles scientifiques. Celle-ci vient d'offrir à Wikipédia 45 comptes d'accès à leurs articles scientifiques. Les personnes ayant accès à ces comptes seront très probablement des éditeurs fréquents de l'encyclopédie. Expliquons le drame, mais avant, un lien vers le blog de la fondation Wikimédia qui traite ce problème (en anglais).
Il y a beaucoup d'aspect à cet "offre" de la part d'Elsevier, et je vais m'efforcer de les aborder tous avant de donner mon avis.
Traitons tout d'abord les avantages de cette offre
- pour Wikipédia, il s'agit-là d'un accès direct à l'information dans le monde scientifique, qui plus est avec un éditeur assez reconnu ;
- cet accès peut en outre signifier une amélioration plus rapide du contenu scientifique de l'encyclopédie.
Voyons à présent les inconvénients
(c'est bizarre à dire d'une offre gratuite, mais ayons les yeux ouverts...)
- Tout d'abord, cela pose des problèmes de vérification de l'information sur Wikipédia. En effet, les éditeurs de l'encyclopédie ayant reçu un accès aux articles d'Elsevier peuvent être tentés de les citer, et cela pose plusieurs problèmes :
- premièrement un problème de vérification par relecture directe, en effet il ne sera pas possible à tout un chacun d'aller vérifier qu'un propos sur Wikipédia lié à une citation est conforme à la citation puisque les articles de Elsevier ne sont pas disponibles.
- Deuxièmement, Wikipédia est une encyclopédie, et comme telle, son but est plutôt de recueillir une information obtenue par un processus scientifique dit "contradictoire", c'est-à-dire (entre autres) revu et corrigé par des pairs, testé par des équipes indépendantes, etc...
- Troisièmement, par nature Wikipédia est une encyclopédie ouverte : il y a (au moins) deux contraintes liées à cela :
- on ne peut pas publier n'importe quoi sur l'encyclopédie (du contenu breveté, avec du droit d'auteur, etc...) ;
- les contributeurs s'engagent à mettre leur publication sous une licence qui permet un certain partage. Il serait injuste envers les contributeurs de fermer l'encyclopédie partiellement, par exemple.
- Un second problème vient du fait que Wikipédia est le 7ème site le plus visité au monde, 5è en France (selon Alexa). Ainsi :
- Elsevier se fait une publicité immense si la plupart des lien d'articles scientifiques redirige vers eux ;
- il s'agit donc d'un problème d'indépendance de la part de Wikipédia ;
- une menace plus grave à mon avis est celle qu'on appelle "native advertising", cette tendance où vous lisez un papier qui ressemble à un article, mais qui en fait est de la publicité, ou un article d'une société, qui n'est pas tenue aux règles journalistiques.
- Le dernier point soulève des questions liées à cette actualité, mais pas de réel problème imminent :
- le droit de citation va surgir dans ce débat, il va y avoir une sorte de jurisprudence ou d'équilibre (si vous faites du droit ou de la physique ^^) sur la possibilité des auteurs de Wikipédia de citer les articles. Il est évident que cet accès de la part de Elsevier n'est pas donné pour qu'instantanément les articles se retrouvassent sur Wikipédia...
- en deuxième lieu, mais lié au premier, il y a la question de la durée au bout de laquelle le contenu d'un article pourra se retrouver en grande partie dans l'encyclopédie, mais il s'agit-là de vieux débat...
Démêlons le Schmilblick
Alors que faire ? me direz-vous. Hauts les cœurs, et envisageons la meilleure sortie pour tous de ce parti.
Ayant vu les problèmes clairement, on peut suggérer
- S'il faut qu'Elsevier soit cité, alors que premièrement, Elsevier soit citée le moins possible comme seule source. C'est-à-dire que le plus possible, il faut que les citation de bas de page (celles que les collégiens utilisent pour leurs exposés ;) ) soient vers des articles en libre accès, quitte à ce qu'eux-même redirigent vers Elsevier, et qu'en dernier ressort, l'on cite seulement Elsevier.
- qu'on utilise la catégorie "discussion" de Wikipédia pour les articles vraiment récents, afin d'éviter le contenu sujet à débat (n'ayez crainte, les wikipédiens le font déjà)
C'est tout, n'oubliez pas de donner à la fondation Wikimédia qui s'occupe de Wikipédia, de lire et corriger Wikipédia, et merci d'avoir prit le temps de vous inquiéter pour l'encyclopédie, et n'oubliez pas de commenter et donner votre avis !
Motius
]]>Ah la la, les mots de passe, une sacrée affaire ! On devrait d'ailleurs dire phrase de passe, pour éviter que les gens ne les choisissent dans le dictionnaire. Heureusement, hashtagueule est là pour faire un petit tour de la question.
Comment choisir un mot de passe, à quoi est-ce que ça doit ressembler, doit-il vraiment comporter 18 caractères ?
Un mot de passe, c'est tout d'abord personnel. Évitez le nom de votre animal de compagnie, c'est d'ailleurs une très mauvaise idée de la part de certains webmails de les utiliser. Jiminy ou Croquette ne sont pas des bons "mots de passe", barrez-les de la liste.
Un mot de passe, ça contient :
- majuscules ;
- minuscules ;
- caractères spéciaux
('"[|-]_=^+ç/!§.;?*÷׿¡%€); - chiffres ;
- un assez grand nombre de caractères (10 au minimum, 8 pour des sites sans importance).
De plus :
- il n'y a pas de mot du dictionnaire. D'aucun dictionnaire, en fait, messieurs les latinistes, et hellènes, anglophiles...
- Il n'y a pas de lieu géographique (lieu de naissance).
- Il n'y as pas de date, ni de nom (toto42, gilles63, 1984).
- et surtout, surtout, ce n'est jamais 1234, 0000.
Alors comment s'y prendre ?
Il existe trois méthodes qui résistent à une attaque de type "bruteforce" ou "par dictionnaire" :
- prendre une phrase que l'on connaît, et la transformer ;
- utiliser un générateur de mots de passe ;
- choisir un grand nombre de mots au hasard dans un très grand dictionnaire.
Détaillons la première méthode. Je prends cette phrase, trop peu connue :
- Le Petit Prince : "On ne voit bien qu'avec le cœur. L'essentiel est invisible pour les yeux."
et je la transforme ainsi (je ne garde que les premières lettres des mots) :
LPP:"Onvbq'ac.L'eeiply."L2P:"0nvbq'4c.L'e2iply."
La seconde méthode impose d'avoir confiance dans le logiciel qu'on utilise.
On a le choix entre plusieurs solutions logicielles sous GNU/Linux :
- apg ;
- pwgen ;
- un basique
$ cat /dev/urandom;-)
Personnellement, j'apprécie le logiciel apg, dans les dépôts de Debian/Ubuntu :
$ apg -a 1 -n 50 -m 40 -x 40 -M SNCL
détaillons les options :
- -a 1 pour forcer le comportement automatique (pas d'entrée utilisateur, plus rapide).
- -n 50 : génère 50 mots de passe. Permet de laisser le choix.
- - m 60 -x 60 : taille minimale et maximale des mots de passe générés de 60 caractères. La encore, permet de choisir un sous-ensemble de caractères.
- -M : permet de spécifier le type de mot de passe. les options sont :
- S : impose la présence d'un caractère spécial, s : permet la présence d'un caractère spécial.
- N : impose la présence d'un chiffre, n : permet la présence d'un chiffre.
- C : impose la présence d'une majuscule, c : permet la présence d'une majuscule.
- L : impose la présence d'un minuscule, l : permet la présence d'une minuscule.
La dernière méthode est récente et peut être plus facile à retenir : il s'agit de piocher au hasard des mots dans un grand dictionnaire. S'il y a suffisamment de mot, que le dictionnaire est suffisamment grand, et qu'on les a bien piochés au hasard (et pas au début ou à la fin), alors le temps nécessaire pour créer tous les couples sera trop long. Exemples :
- Éléphant miel Barbiturique repolluaient plaquebière plaisantin hôpital
- izolovat resouffrirons Réébarbées Espanbrun bootabilisa collimateront biliotin
qui ont le double avantage d'être complexes, et de nous cultiver un peu ^^. Pour obtenir ces résultats, j'ai utiliser la fonction page aléatoire du Wiktionnaire. J'admets qu'utiliser des mots à consonance française (1er exemple) est plus facile.
Enfin, si vous voulez tester un peu vos idées de mots de passe, ne les envoyez jamais sur un site web. Vous n'avez aucune garantie que celui-ci ne va pas les enregistrer. Utilisez des mots de passe à la construction identique. Il y en a deux sites permettant d'en tester la robustesse que je peux vous conseiller :
- how secure is my password ;
- un vérificateur passif-agressif en anglais que je trouve amusant.
À bientôt !
Motius
]]>À hashtagueule, on aime les projets innovants qui en plus permettent la décentralisation, le respect de la vie privée. Eh bien bonne nouvelle en provenance de Own-Mailbox : ils ont des bonnes idées, et un projet solide !
Des beaux projets de décentralisation du mail, on en a vu quelques uns :
Eh bien celui là a de nouvelles idées ! Même s'il ne propose pas une solution complète d'autohébergement comme les projets ci-dessus, Own-Mailbox est novateur.
Own-Mailbox, c'est un projet Kickstarter sous la forme d'un petit boîtier que vous branchez derrière votre box, et qui s'occupe de tout. De tout, vous dis-je. Les fonctionnalités incluent :
- chiffrement GPG (PGP possibilité de gérer ses clefs manuellement) ;
- chiffrement TLS pour ceux n'ayant pas GPG (grande innovation, selon moi) ;
- autohébergement du mail ;
- utilisation IPv4/IPv6 ;
- coutournement du blocage par certains FAIs du port 25 (mail).
Selon moi la grande nouveauté, c'est l'utilisation d'une seconde méthode de chiffrement pour ceux n'ayant pas GPG. Il s'agit de la fonctionnalité dite PLM (pour Private Link Message). Simplement :
- si le(s) correspondant(s) possède(nt) une clef GPG, ownmailbox utilise GPG pour chiffrer ;
- sinon le contenu du mail reste dans le serveur ownmailbox, et dans le mail est envoyé un lien HTTPS vers le serveur. Ce lien est configurable pour éviter - si besoin est - les robots, être disponible pendant un certain temps, être cliquable une seule fois, demander une authentification mot de passe, etc...
Cette méthode vous permet de discuter de manière chiffrée avec tout le monde sans prise de tête, même lorsque votre correspondant ne sais pas/veut pas se préoccuper de chiffrement.
Pour finir, quelques points de détail :
- Les logiciels utilisés sont libres/open source (celui qu'ils développent utilise la GPLv3, ceux qu'ils utilisent/améliorent conservent leur licence) ;
- le matériel est open hardware ;
- le boîtier possède un port USB :
- pour exporter/importer les clefs GPG ;
- pour augmenter la capacité de stockage ;
- l'équipe pense pouvoir vendre ses premiers modèles dès juin 2016, en fonction du résultat de la campagne Kickstarter ;
- la box fera tourner un OS basé sur Debian (Ubuntu et Linux Mint sont debian-based, pour mémoire) ;
- possibilité de mise à jour en un clic.
En fin de compte un projet ambitieux et qui vend du rêve !
Passer d'un monde centralisé (autour des GAFAM) à un monde décentralisé va être difficile, et même si l'autohébergement reste l'utopie, ce sont des projets comme celui-là et CaliOpen qui font avancer les choses dans le bon sens.
Bonne journée à tous !
Motius
]]>Il s'agit d'une boîte (eh oui, c'est pas libre) que je qualifierais d'éternelle start-up, vous savez ces nouvelles boîtes informatique (mais pas que) qui essayent de proposer des trucs simples et innovants sur un marché déjà surpeuplé.
Niveau simplicité, Padlet a donc vu juste, car il n'est question ici que de réinventer le bon vieux principe du tableau blanc, ou de la façade de frigo. Le service met en effet à disposition des surfaces ou les gens autorisés peuvent placer des mémos, billets, photos ou autre contenu multimédia ou pièce jointe.
Chaque tableau est personnalisable, et même s'il faut passer à la caisse pour déverrouiller toutes les options, on peut déjà bien faire mumuse avec un compte gratuit. On peut notamment changer le fond du tableau parmi une sélection de textures proposées et on peut charger son logo.
Niveau confidentialité, vous pouvez rendre un tableau uniquement accessible pour vos collaborateurs, ou bien publiques en lecture ou en écriture, et même en modération (c'est à dire que vous autorisez les utilisateurs à supprimer les messages d'autres personnes).
Sinon, on peut se demander à quels usages est destiné ce service. Bien évidemment, il peut s'agir d'un outil de productivité, et son organisation graphique est bien adaptée aux réunions de type brainstorming, car il est aisé de positionner les messages selon des colonnes de rangement à sa propre sauce, comme "urgent / pas urgent" ou encore "must have / nice to have". Vous comprendrez donc ici que dans ce cas il est judicieux de restreindre la modification, voire la lecture, à ses collaborateurs.
Mais il est évident que si la mayonnaise prends vraiment très fort (ce qui n'a pas l'air d'être le cas pour l'instant), des community managers, politicards, publicitaires et autres blogueurs pourraient utiliser ce service à grande échelle, en organisant un lâcher de commentaire dans tous les sens et de toutes les couleurs. Ça pourrait faire office de forum ou de canal IRC.
Visiblement, la sauce n'a pas pris, comme nous le montre par exemple l'extension Wordpress abandonnée depuis plus de 2 ans, et son apparente absence des... comment dire... conventions sociales et ethnologiques modernes.
Juste pour l'essai, rien que pour voir, voici un petit padlet dédié à votre site web préféré. Lâchez-vous, parlez-nous de n'importe quoi. C'est cadeau.
]]>J'espère que vous avez passé une bonne semaine de rentrée. En ce qui me concerne j'ai pas arrêté, ce qui facilite mentalement l'entrée dans le mois de septembre...
C'est également la (première) rentrée pour hashtagueule.fr avec un rythme de publication qui s'approche de celui de croisière. Ça y est, l'activité du blog est maintenant bien lancée. Merci à Motius de tant s'investir dans la vie du blog.
Autre nouvelle, la création d'un canal IRC officiel pour le site, c'est par ici. Bon, pour le moment il s'agit uniquement d'un canal sur un service existant, mais lorsque que je disposerai de mon propre serveur dédié (pour le moment, je suis hébergé chez notre ami Ubr), j'en profiterai pour déménager le tout et créer un vrai serveur IRC à nous.
Je rappelle également que vous pouvez toujours partager via les commentaires et les forums.
Voilà, bonne continuation, et n'oubliez pas, restez gentils :)
Raspbéguy
]]>Ce mois ci, Google a présenté son nouveau design : un logo Google et une icône G quadricolore. Mais ce G ne plaît pas à Qwant, un nouveau moteur de recherche qui respecte la vie privée de ses utilisateurs.
En termes de dates, le logo de Qwant est antérieur au nouveau de Google. Les deux se ressemble énormément, Google utilise désormais une fonte beaucoup plus épurée, et le G a perdu du serif, et est désormais très proche du Q de Qwant. Le problème, c'est qu'ils utilisent tous les deux un dégradé rouge-jaune-vert-bleu.
En conclusion, ce qui les rapproche, c'est :
- la fonte (similaire, arrondie, épurée sans serif) ;
- les couleurs (même si elles diffèrent légèrement) ;
- la succession des couleurs ;
- le secteur d'activité (moteurs de recherche).
Si ça vous intéresse, Korben a une théorie intéressante sur l'histoire de la création du nouveau logo de Google ;-) .
Le DG de Qwant a indiqué à Numérama que Qwant songeait à porter plainte contre le nouveau logo.
Motius
]]>Êtes-vous amateurs de musique ? Eh bien nous aussi, c'est pourquoi aujourd'hui je vous présente Lilypond (pour ceux qui ne le connaissent pas déjà). Lilypond est un logiciel permettant de créer des partitions de musique. Pour ceux qui connaissent le fonctionnement de LaTeX, le principe est le même. Pour les autres, on va le découvrir ensemble...
Aspect pratiques
Vous pouvez passer à la partie II si vous n'êtes pas sûr de vouloir utiliser Lilypond, pour en voir les fonctionnalités de base.
Lilypond se télécharge ici.
On écrit les partitions dans un fichier texte, à ouvrir avec notepad++ (ou autres) sous windows, vim (ou geany ou emacs) sous linux.
On compile avec la commande :
lilypond mon_fichier.lyPour les petits exemples, ceci est plus rapide. Il existe néanmoins un IDE très efficace que j'utilise qui s'appelle Frescobaldi, qui est multiplate-forme. L'avantage de Frescobaldi est qu'il permet de prévisualiser son travail :
Exemples
En fait c'est assez simple, vous écrivez les notes, et Lilypond se charge du reste. Mise en page, espacement, production du PDF/DVI, manière optimale de disposer la queue des croches...
Faisons simple avec un petit exemple. Écrire :
{ c' e' g' c' }dans un fichier texte test.ly produit le résultat suivant après compilation :
On ne s'en rend pas compte tout de suite, mais c'est très puissant. Lilypond a automatiquement créé un PDF à partir d'un fichier texte tout simple. En fait il a fait plus que ça. Puisque rien n'est précisé ici (mis à part les notes) Lilypond a fait beaucoup d'hypothèse, il s'agit en fait du comportement par défaut :
- Durée de chaque note (noire)
- Clef à afficher (clef de sol)
- durée de la mesure (C = 4/4)
- hauteur des notes (do à 293,66 Hz)
En fait, la seule chose que j'ai écrite ici, c'est c' = do, e' = mi, g' = sol. Vous l'avez compris, Lilypond utilise la notation anglo-saxonne pour représenter les notes. Au début c'est ennuyeux (il faut chercher la lettre correspondant) mais vu le nombre de notes qu'il faut taper dans une partition, à la fin on est content.
Voici donc la table des notes :
- a = la
- b = si
- c = do
- d = ré
- e = mi
- f = fa
- g = sol
Vous avez sans doute remarqué que j'ai écris une apostrophe après chaque note, celle-ci permet d'indiquer l'octave supérieure.
En fait il y a deux comportements de Lilypond :
- le mode absolu que vous venez de voir et que je n'utiliserai bientôt plus (il est par défaut) ;
- le mode relatif.
On peut donc réécrire notre fichier lilypond ainsi :
\relative c' { c e g c }Vous découvrez là une nouvelle fonctionalité de Lilypond ! les commandes. Celles-ci sont introduites par le caractère "\". Ici on a demandé à Lilypond de disposer toutes les notes relativement au do 293. \relative permet de ne plus avoir besoin de mettre d'apostrophe, chaque note étant écrite en fonction de la précédente. Ainsi :
\relative c { c' c' c' }produit le résultat suivant :
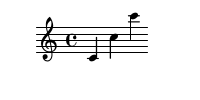
Vous savez désormais écrire toutes les notes, augmenter d'une l'octave, utiliser le mode relatif ou absolu. Pour diminuer d'une octave, le caractère à utiliser est la virgule :
\relative c'' { c' c, c, }donne :
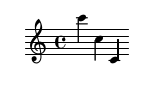
Tout cela est un peu monotone. Ajoutons du rythme. Ici c'est pareil que la hauteur. Le rythme d'une note dépend de la précédente. La première vaut une noire par défaut. Pour définir un rythme, on utilise les puissance de 2. En effet une ronde vaut deux blanches qui valent deux noires, qui valent deux croches, qui valent deux doubles-croches etc...
Pour Lilypond, la ronde est représentée par le chiffre 1. On a donc :
- 1 : ronde
- 2 : blanche
- 4 : noire
- 8 : croche
- 16 : double croche
- 32 : triple croche
- etc...
On peut donc écrire :
\relative c' { c1 | c2 c | c4 c c c | c8 }qui donne :

Vous remarquez :
- que j'ai utilisé un pipe "|" pour délimiter les mesure. Ce n'est pas nécessaire, Lilypond le fait automatiquement, mais si vous les insérez, Lilypond peut lever une erreur "barcheck" pour vous prévenir que vous n'avez pas mis le pipe au bon endroit. (Une erreur barcheck peut aussi signifier que vous avez essayé de faire une mesure trop longue).
- que je précise la durée de la note seulement lorsque je désire la changer.
Deux autres concepts fondamentaux :
- Les altérations (dièse, bémol, bécarre)
- les ligatures
Une chose à retenir : on n'écrit jamais de bécarre. Lilypond les écrira pour vous :
\relative c' { \key c \minor c d e f | c d ees f | e ees e ees }donne :

Quelques explications :
- es indique le bémol ;
- is indique le dièse ;
- eses le double bémol ;
- isis le double dièse ;
- dans la première mesure, j'ai écrit e sur une partition ou mi est bémol. Donc Lilypond a mis le bécarre automatiquement.
- Dans la seconde mesure, pas de bémol à écrire, il est à la clef.
- J'ai utilisé la commande \key suivie obligatoirement de deux paramètre :
- c
- \minor
NB : il ne faudra pas confondre \key qui permet de définir la tonalité du morceau et \clef qui indique la clef de la mesure (qui admet treble (clef de sol), bass (clef de fa)... comme paramètre) :
\relative c' { \clef treble c \clef bass c \clef treble c \clef bass c | }donne :
J'espère que vous êtes convaincus que le résultat est ce qu'on attend. En effet il s'agit quatre fois de la même note.
Finissons-en avec les problèmes de durée de note :
- On obtient une note pointée en écrivant un point après :
- c.
- c4. (et non pas c.4, qui serait absurde, il faut d'abord connaître la durée de la note pour savoir combien le point vaut)
- c'4. (l'apostrophe (ou la virgule) doit être collée à la lettre, en effet la note est c' puisque c est une note différente, une octave en dessous)
- On peut sinon utiliser les parenthèses pour indiquer une ligature de note tenue. Cela se fait ainsi :
\relative c' { c1( | c4 ) c }qui donne :

La parenthèse est collée après la note sur laquelle le début de la ligature commence.
Voyons maintenant les accords. On les obtient ainsi :
\relative c' { <c c'> <cis e cis'>8. <cisis cisis'>16 }qui donne :
Vous remarquez que Lilypond a fait automatiquement le lien entre la croche pointée et la double croche. Vous savez aussi comment organiser :
- les dièses ;
- les < > pour les accords ;
- les points ;
- les chiffres pour la durée de la note.
Pour changer la manière dont Lilypond lie les croches/doubles-croches/etc... il faut utiliser "[" et "]" exactement comme on a utilisé les parenthèses :
\relative c' { c8 c c c c c c c | c[ c] c c c c c c }qui donne :

Je ne sais pas vous, mais je trouve que Lilypond a bon goût dans la manière qu'il a de lier les croches.
Changeons de mesure ! 4/4 ça devient ennuyeux ;-) . Eh bien pour cela, on va utiliser la commande \time suivie d'un argument. \time 3/8 donne une mesure qui dure 3 croches :
\relative c' { \time 7/8 c8 c c c c c c | \time 3/8 c[ c] c c c c c c }donne :
Je vais finir cette première esquisse par quelques points :
- Lilypond grogne à chaque fois qu'on compile sans le numéro de version. il suffit de rajouter l'entête
\version "2.18.2". Il s'agit là d'un header, on en verra d'autres par la suite. - Les partitions peuvent être très complexes :
- plusieurs voix ;
- plusieurs portées ;
- plusieurs instruments ;
- plusieurs partitions au sein d'un livre ;
- ajout d'un accompagnement guitare, chant, paroles, etc...
Faites-moi part de vos commentaires !
Motius
PS : la suite, c'est par ici !
]]>La fondation Wikimédia, qui s'occupe entre autres du bon fonctionnement de Wikipédia a bloqué l'édition de l'encyclopédie pour 381 comptes et quelques adresses IPs associées.
Selon la fondation, les utilisateurs ne respectaient pas la charte de l'encyclopédie. Le problème soulevé est la neutralité des points de vus, qui est nécessaire pour l'objectivité de Wikipédia.
Les comptes étaient payés pour réaliser des modifications sur Wikipédia. Si cela est autorisé, il est nécessaire (selon la nouvelle charte) de signaler les problèmes de conflits d'intérêts.
C'est donc pour améliorer la neutralité et l'objectivité de Wikipédia que ces mesures ont été prises, et peut-être aussi pour envoyer un message.
Cela dit il est toujours possible de recréer un compte, ou d'utiliser un VPN.
L'article en anglais sur le blog de la fondation.
Motius
]]>Vous vous en rendrez compte si vous ne le saviez pas, je ne suis pas un immense fan de Google. Et pourtant ceci est une des fois où je pense qu'on est injuste envers Google.
On lis chez zdnet.fr l'article en question : l'Inde accuse Google de favoriser ses propres services (ceux de Google LTD, ou de Alphabet) au sein du moteur de recherche google.com (ou google.fr, .in, etc...)
Faisant partie des "gentils du net" vous vous doutez que je préfère la décentralisation. Et pourtant je ne vois pas de problème à ce que Google privilégie ses propres services. Tout simplement parce que google n'est pas un service public.
À cela s'ajoute une autre raison : le travail d'un moteur de recherche est de recenser les lien et de proposer des sites web en fonction d'une requête. C'est fondamentalement un annuaire intelligent de sites web. D'ailleur d'un point de vue historique c'est exactement cela qui c'est passé. On est passé d'un annuaire centralisé de tous les sites web qui était compliqué à des requêtes DNS + un moteur de recherche.
Quel que soit le point de vue permettant de justifier cette amende, il se heurte à cet argument, et il y a de facto deux poids deux mesures : si je crée mon moteur de recherche ce n'est pas grave si je mets en première page mon service de mail par exemple.
À la limite, tout site web un peu gros d'aggrégation de news et de liens externes est aussi un point de départ sur le web, la seule différence est que la recherche n'est pas automatique, et faite à petite échelle, sur une sous-partie de l'internet.
Le fond du problème pour moi se trouve donc là : on accuse google de priviliégier ses services, mais pour savoir quels services mettre en premier, il faudrait que google utilise des critères objectifs. Seulement là-dessus pourrait-on légiférer. Mais personnellement je ne veux pas d'un moteur de recherche sponsorisé par l'État. C'est d'autant plus absurde que lorsque je me rends sur google.fr, je désire la réponse de google. sinon j'irai sur yahoo.com ou bing.
Si on veut faire une analogie : c'est comme vouloir interdire que Carrefour promeuve ses produits dans son magasin, et qu'Intermarché et Auchan fassent la même chose.
Bonne journée !
Motius
]]>La news date du 27 août 2015 via slashdot : Google traque les recherches des internautes et a proposé un challenge à ceux dont les recherches sont liées à la programmation. À la fin du challenge (des cinq challenges en fait) l'internaute remplit un formulaire et est contacté par le service de recrutement de la société.
Ce n'est pas une première de la part de Google qui en 2004 avait lancé des défis mathématiques de la sorte.
Tout ceci rappelle les vieilles légendes selon lesquelles pendant la guerre froide le MIT recrutait les mathématiciens d'europe central et de l'est à la sortie des concours....
Motius
PS : deux articles sur Google d'affilée. Faut que je change de sujet ou bien l'on va penser que je fais une fixation ;-)
]]>Via 9gag
]]>je ne sais pas si vous connaissez Politwoops le site qui recense les tweets des personnalités publiques ? La Sunlight Foundation en est à l'origine d'abord aux États-Unis puis a essaimé dans une trentaine de pays. Le site web utilisait une API permettant de sauvegarder les données publiquement accessible du touitte : date, contenu, géolocalisation si fournie, et éventuellement la date de suppression.
Eh bien le 24 août 2015 Politwoops a indiqué que Twitter leur avait bloqué l'accès à cette API permettant de récupérer les touittes automatiquement. La raison invoquée par Twitter est la non conformité de Politwoops avec la licence de l'API.
En effet Twitter permet un "droit à l'oubli" à ses adhérents. Et selon lui, la conservation des touittes par Politwoops n'est pas conforme.
À mon avis, il y a là plusieurs erreurs de raisonnement.
- Premièrement, les touittes archivés étaient ceux de personnages publics, et non de Monsieur tout le monde, et leurs faits et gestes influent directement sur la manière dont nous nous gouvernons.
- Deuxièmement, supprimer un touitte de son fil revient à se dédire, par contre empêcher le droit de citation en rendant l'action de citer difficile n'est pas un grand progrès pour le débat. Il est en outre possible de faire une capture de son écran, ce qui en termes de citation est identique, mais pas aussi facile à automatiser.
- Troisièmement d'un point de vue historique conserver la donnée est toujours une bonne chose. Le numérique devrait faciliter le travail des historiens et permettre l'écriture d'une Histoire plus complète, plutôt que lacunaire.
Sur cette nouvelle un peu ancienne, je vous souhaite une bonne journée. N'hésitez pas à commenter/donner votre avis !
Motius
]]>une news très brève et à prendre avec des pincettes. En effet, au cours de mes tribulations sur les zinternets, je suis tombé là-dessus : un article de Wikistrike (que je ne connaissais pas) datant d'août 2015 intitulé 1 million de signatures contre TAFTA à la poubelle. Je ne sais vraiment pas ce que ça vaut :
- en termes de crédibilité, je ne connais pas le site ;
- de vérification des sources (c'est un sujet difficile, et les accord internationnaux sont secrets afin de laisser de la marge aux négociateurs, puis deviennent connus par les parlements (européen ici, mais ç'aurait pu être chacun des 27 parlements) et enfin publics).
La raison pour laquelle je vous en parle, c'est un paragraphe du texte (encore une fois à remettre en question, on n'est jamais trop prudent) situé vers la fin :
Parmi les grands dangers dénoncés par Stop TTIP, il y a cette mise en place de tribunaux d’arbitrages qui offriront la possibilité aux entreprises de contester des décisions gouvernementales. Toute décision collective qui entraverait le libre marché transatlantique serait susceptible d’être punie. Par exemple, si la France estime qu’il faut interdire un conservateur déterminé afin de protéger la population d’un risque sanitaire donné et que cette interdiction engendre une perte pour une multinationale, cette entreprise pourrait poursuivre l’état et exiger des dommages et intérêts.
Eh bien ça (que j'espère bien être faux) me paraît malsain. On a toujours du mal a définir les limites de la liberté (où s'arrête ma liberté d'expression ? Je ne peux pas dire du mal d'autrui, ni dire du bien du IIIè Reich). De même je pense que la liberté d'entreprendre est une bonne chose, mais que toute entreprise n'est pas bonne et la liberté doit donc pouvoir être régulée par l'État. À partir d'ici il y a deux scénarios :
- soit on régule sur un critère objectif (pas de CFC, etc...) ;
- soit non (lui je l'aime pas, sa tête ne me revient pas).
Le second cas pose un problème de favoritisme ce pourquoi il est nécessaire de pouvoir contester les décisions de l'État.
Dans le cas d'un critère objectif, il existe deux sous-cas :
- soit le critère est jugé valide par des expert en la matière ;
- soit non.
Mais indifféremment des cas, on ne doit jamais pouvoir obtenir des dommages et intérêts de la part de l'État puisque l'État a rendu une décision (à tort ou à raison) et qu'il s'agit ainsi d'un choix de société. Contester oui. Mais pas faire de calculs sur un éventuel manque à gagner.
Quoi qu'il en soit, j'espère qu'on ne verra rien de tel dans TTIP, et que sur ce point, wikistrike.com se trompait. Je sais, je fais naïf, là.
Bonne journée à vous !
Motius
PS : j'ai le point Godwin du jour !
PPS : oulà ! Plus long que je croyais cet article.
]]>Vous lisez le titre et je vous entends déjà hurler "quoi ? qu'est-ce qu'il a fumé ? c'est dans un an et demi !", "Mouais la politique on s'en fout un peu sur un blog de geeks, surtout aux États-Unis"
En fait je voulais simplement linker vers un AMA (ask me anything) de reddit. Larry (Lawrence) Lessig et Jimmy Wales ont répondu à des questions intéressante. C'est toujours sympa (à mon avis) de les écouter parce que Larry a bosssé sur les Creatives Commons (toutes les licences CC-BY-SA-NC, etc... que vous voyez sur des images sur internet) et Jimmy est le cofondateur de Wikipédia.
L'actualité ici, c'est que Larry se présentera à la présidentielle US s'il obtient 1 million de dollars grâce à la campagne de crowd-funding qu'il a lancé.
En fait Larry a fait une promesse : il doit accomplir une mission pendant son mandat et démissionnera après, laissant la place au vice-président : réformer le financement des campagnes.
L'argumentaire développé par Lessig est qu'après cela, les américains pourront enfin partir d'un bon pied pour résoudre pas mal de problèmes aux US.
À bientôt !
Motius
PS : oui, ça été dur de ne pas troller sur Trump ;-)
]]>On trouve ça par exemple là. TL;DR : la loi interdisait aux boulangers de prendre des vacances, c'était un des rôles du préfet d'organiser cela, car le pain était une denrée de première nécessité.
Je n'ai pas grand chose à dire, seulement que la libéralisation implique maintenant la coordination des boulangers... et que ça fait une super idée de (petite) startup : créer un site web recensant les horaires d'ouverture des boulangerie l'été (et lesquelles sont ouvertes) et lier ça éventuellement avec une application mobile Android/iOS.
Motius
PS : désolé pour ce post assez jacobin ;-)
]]>Peu de jours après avoir proposé que tous les nouveaux sites webs dussent être enregistré par le gouvernement le 23 août 2015, la Malaisie se met a censurer les sites webs en fonction du contenu le 27.
On peut parfois douter du caractère tragique d'une nouvelle. Pas là.
Que doit-on en retirer ?
- Premièrement il faut éviter la concentration (tout chez Facebook, Google, Twitter...) parce que ça facilite le travail de censure. Donc s'autohéberger, ou bien faire des collectifs.
- Deuxièmement que le développement de la censure peut être très rapide (quatre jours ici)
Ironiquement, le gouvernement malaisien avait donné des raisons pour son projet :
- lutter contre la calomnie (untel est un voleur, etc...) ;
- lutter contre la citation calomnieuse (dire qu'untel a dit que 'ça' alors que c'est faux).
Finalement, c'est pour lutter contre l'organisation d'une manifestation à l'aide du mot-clef "Bersih 4" (filet n°4) que la censure a été utilisée. Utiliser la censure pour faciliter la censure.
Motius
]]>Ce premier post n'est pas vraiment un article, seulement l'occasion pour moi de me présenter rapidement, si vous n'avez pas eu l'occasion de lire la page des présentations rapides. Je suis Motius, étudiant en école d'ingénieur, passionné par GNU/Linux, la philosophie du libre, engagé pour la neutralité du net, et surtout les problèmes liés à l'application du droit sur internet. Mes passe-temps incluent tirer des sons d'un piano et casser des bateaux ;-). J'espère que vous vous plairez sur hashtagueule.fr. N'hésitez pas à commenter !
Motius
]]>Vous avez peut-être remarqué la petite quantité de contenu de ce site. En tout cas, nous en sommes conscients.
Rassurez-vous, c'est normal. Premièrement, on a été pas mal occupés pour la mise en place de ce site depuis sa publication. On a eu quelques problèmes aussi, comme le rétablissement du site suite à un crash (ma faute...) puis le déménagement du site chez un nouvel hébergeur. On a également beaucoup travaillé à la cohérence et à la structure, donc maintenant je pense (j'espère) que le plus dur est fait concernant la technique.
Deuxièmement, je suis pour le moment le seul chroniqueur actif sur le site, les autres se mettront à publier plus tard. Je pense donc que la grande ouverture du site se fera courant septembre.
En tous cas, si l'idée du site vous plaît, restez avec nous, et si vous avez des remarques ou des questions, n'hésitez pas à me contacter.
Voilà, éclatez-vous, soyez libres et restez gentils.
]]>En effet, Disney a annoncé ce week-end lors du salon D23 en Californie la création d'une zone entièrement dédiée à Star Wars, non pas dans un de ses parcs d'attraction, mais dans deux de ses parcs, en Californie et en Floride.


Crédits : Disney Parks
Personnellement, je n'ai pas beaucoup approuvé le rachat de Star Wars par Disney, mais d'un autre côté je ne pourrai pas m'empêcher d'aller voir le film, quitte à sortir en hurlant de rage. Ah ils sont forts chez Disney, les gredins. C'est plus fort que moi, Star Wars représente tellement pour moi, et comme avec toutes les choses qui nous sont très chères, si on a pu goûter aux merveilles de cet univers, il faut savoir également endurer les moment les plus pénibles, car il s'agit d'un moment affreux pour Star Wars à n'en point douter.
Et d'un autre côté, je ne peux m'empêcher d'avoir un sentiment d'excitation au plus profond de mes tripes au sujet d'un parc Star Wars. En effet, même si je sais pertinemment qu'il s'agit d'une opération marketing gigantesque et d'une arnaque morale abominable, l'idée de se balader sur une des planètes de cette galaxie ou de tâter le pont du Faucon Millénium est très séduisante, comme un rêve de gosse qui se réalise. J'ai honte de le dire, mais j'adorerais aller dans l'un de ces parcs rien que pour ça.
Bon, maintenant tout ce que j'espère, c'est que mon fauteuil de cinéma sera encore intact après que j'aie visionné le film, même si ça s'annonce vraiment, mais alors vraiment très mal, rien qu'aux vues de la bande annonce (pauvre vieil Han Solo, ne prolongez pas ses souffrances, aidez le à partir dans la dignité).
Espérons que j'aie tort.
]]>Nicklas Nygren, alias Nifflas, est principalement développeur de jeux vidéos, pour la plupart simplistes mais dotés de très bons gameplays. Ses jeux sont très jolis et prenants.
Du point de vue des histoires de fond, l'action se situe souvent dans des mondes dépourvus d'humains ou bien post-apocalyptiques dans lesquels des créatures de la nature on repris le contrôle de la terre, ce qui accentue le caractère poétique de ces ouvrages.
Within A Deep Forest est sans conteste l'un de ses jeux les plus novateurs en termes de gameplay. Vous y incarnez une petite balle dont vous devez maîtriser les rebonds en leur donnant plus ou moins de force et en changeant le matériau constituant la balle. Les matériaux sont progressivement gagnés en accomplissant des quêtes proposées par les différents PNJs et se déroulant dans des univers propres. Le design est très simpliste, tout en pixels apparents et et 2D vue de profil.

WADF : Dans la nature, obstacles à franchir. Très esthétique.
L'un de mes jeux préférés de Nifflas est Knytt, toujours en 2D et aux pixels grossiers. Le principe est simple, vous incarnez une petite créature perdue sur un terrain inconnu, et vous devez explorer une carte pour retrouver des pièces de votre vaisseau spatial pour pouvoir retourner chez vous.

Knytt : Design simple, carte simple, ambiance simple. Tout est dans la simplicité.
Vos seules interactions sont vos déplacement. En dehors du gauche/droite vous pouvez littéralement grimper aux murs (tous les murs) et sauter.
Notons que Nifflas a ensuite développé Knytt Stories, la "suite" de Knytt, avec un personnage différent, une carte bien plus vaste et une histoire un peu plus poussée, même si le design et l'ambiance restent identiques. Il y est introduit de nouveaux pouvoirs à gagner au fil du jeu comme le double saut, le leurre holographique et l'ombrelle qui permet de tomber moins vite. Le jeu comprend également un éditeur de niveau ce qui permettait à tous les joueurs de proposer leurs propres niveaux, ce qui donnait potentiellement au jeu une durée de vie infinie.
Plus récemment, une refonte totale du jeu a été faite, baptisée Knytt Underground, avec des graphismes nettement plus léchés, une carte immense, une vraie histoire de fond et une multitude de quêtes. Le plus intéressant dans ce jeu est qu'il mêle les gameplays de Knytt et de Within A Deep Forest : le joueur, passé un certain niveau, peut choisir à tout moment de permuter entre la petite créature grimpante et la balle bondissante, ce qui permet des possibilités de jeu assez incroyables.
Nifflas a également développé pas mal de jeux expérimentaux. Beaucoup de jeux dont le développement a été arrêté, mais dont les travaux en cours peuvent être téléchargé en fouillant sur son site. Heureusement, certains de ces jeux expérimentaux sont complets, notamment le fantastique 7 Nanocyles, qui repose sur deux petits jeux précédents, et très très prenant. Dans ce jeu en 3D très abstrait, vous devez vous déplacer dans l'espace en étant soumis aux lois de la gravité lorsque vous êtes en dehors de certaines zones fermées, qui vous permettent de voler dans l'importe quelle direction lorsque vous êtes à l'intérieur. C'est assez subtil à expliquer mais simple à comprendre, regardez plutôt la vidéo suivante :
Nifflas compose également beaucoup de musique, une bonne partie pour ses jeux.
Musique électronique très abstraite et évasive. Très apaisante si vous voulez mon avis.
Nifflas collabore également avec beaucoup d'autres artistes pour les musiques de ses jeux. Je parlerai de certains de ces autres artistes dans des articles ultérieurs, parce qu'il le méritent également.
Voilà, je vous laisse découvrir l'ensemble de ses œuvres (il y en a tellement) sur son site, c'est par ici.
Dernière chose : La plupart des jeux de Nifflas sont gratuits. Les derniers jeux PC sont compatibles Windows, Mac et Linux. Les jeux anciens ne sont compilés que pour Windows, mais ils passent très bien dans Wine sur Mac ou Linux.
]]>C'est un grand plaisir que je prends en écrivant ce premier post. Je pense que quasiment personne ne va voir ce blog à ses débuts, j'espère que la mayonnaise va prendre.
Tout d’abord, veuillez excuser le manque total de personnalisation du blog, on y travaille et un jour, je vous le promets, elle sera super chouette.
Petite présentation. Je suis Raspbéguy, fondateur du blog et rédacteur en chef. Je m'intéresse à pas mal de choses, entre autres au développement logiciel, au techniques de réseaux et à l'art numérique, notamment le dessin vectoriel et la musique électronique. Je serai bientôt rejoint par une petite équipe de joyeux lurons bien motivés, possiblement issus de plusieurs continents, ce qui pourra donner lieu à un blog international et multilingue !
Hashtagueule, mais d'où diantre cela vient-il ?
Il est vrai que ce nom un peu provocateur peut susciter quelques questions. Il s'agit d'un très bon jeu de mot lancé par le youtubeur vidéaste Antoine Daniel. Ce calembour m'était sorti de la tête jusqu'à un jour où je me suis baladé sur le site de mon registrar sans but précis, et paf, je me suis demandé si ça pouvait faire un bon nom de domaine.
Ce nom que j'apprécie beaucoup représente notre volonté d'utiliser et de construire un Internet libre, décentralisé et neutre, en rejetant poliment mais fermement les services mettant en danger ses utilisateurs et ne respectant pas les principes du net que nous promouvons.
Hashtagueule, de quoi ça va parler ?
Ce blog aura pour thème la technologie, les sciences, l'informatique et les arts numériques. Il sera l'occasion pour les chroniqueurs de se défouler de partager leur expérience et de propager leurs idées et leurs envies quant au monde dans lequel nous vivons, du moins des points de vues évoqués dans la phrase précédente. Ainsi, y seront postés :
- Des éléments d'actualité, probablement la majeure partie du contenu de ce blog ;
- Des coups de cœur / coups de gueule, sur l'actu techno, sur une expérience d'un programme, sur la tarte que Grand-Mère nous a préparé pour midi, que sais-je encore ;
- Des astuces/tutoriaux divers et variés, avec les meilleurs vœux du chef ;
- Des sélections de sites utiles/intéressants/marrants, oui parce qu'on sais se marrer aussi nous les gentils du web ;
- Et pourquoi pas des tests, revues de presse, rubrique jeux vidéo, en fait ça dépendra des gentils chroniqueurs qui vont me rejoindre.
Mais des sites comme ça, ça n'existe pas déjà ?
Ah ben tout de suite ! Bon, on est bien clair, on a pas dit qu'on allait inventer le bidon de 2 litres. Des sites comme le nôtre, il en existe des tonnes. Je ne vais pas donner de liste mais le cœur y est.
Il s'agit uniquement de donner un autre son de cloche, ou d'ajouter le nôtre à ceux qui nous plaisent, mais également de faire passer de la bonne humeur et de relayer les infos utiles. C'est tout ! Après, chacun fait ce qu'il veut, hein, nous même on consulte et on est fan d'autres blogs, ça ne nous empêchera pas de l'ouvrir et de dire ce qu'on pense.
Bon, je crois que j'ai tout dit, jusqu'au moment ou je me rendrai compte que j'ai oublié un truc important et que j'éditerai ce post à la barbare, mais le principal y est je pense.
Bonne lecture, restez libres et soyez gentils.
Raspbéguy
]]>