La virtu pour les nuls : le stockage
Mise en garde : cet article va être très long, car j'ai pensé qu'il serait intéressant d'exposer ma démarche complète pour la conception de mon infrastructure, et de présenter aussi non seulement ce que j'ai mis en place, mais également ce que je n'ai pas retenu. En plus on va parler de plein de technos différentes donc vous n'êtes pas obligé de tout lire si vous voulez. D'un autre côté vous êtes toujours libre de faire ce que vous voulez donc je sais pas de quoi je me mêle.
L'introduction reste générale, objective, et pose les contraintes, la première partie expose la solution choisie, et la deuxième partie aborde la mise en œuvre.
Comme tout ingénieur système sain d'esprit, j'aime bien les infrastructures qui ont de la gueule. Par là, j'entends une infra qui soit à l'épreuve de trois fléaux :
- Le temps : Les pannes étant choses fréquentes dans le métier, les différents éléments de l'infrastructure, tant matériels que stratégiques, doivent pouvoir être facilement et indépendamment ajoutés, remplacés ou améliorés.
- L'incompétence : Les opérateurs étant des êtres humains plus ou moins aguerris, le fonctionnement de l'infrastructure doit être le plus simple possible et sa maintenance doit réduire au maximum les risques d'erreurs de couche 8.
- L'utilisation : Personne ne doit être en mesure d'utiliser l'infrastructure d'une façon ou dans un objectif non désiré par ses concepteurs. C'est valable pour certains utilisateurs finaux qui tenteraient d'exploiter votre œuvre dans un but malveillant, aussi bien que d'éventuels changements d'équipe qui ne comprend rien à rien (cf. les dangers de l'incompétence).

Risques de Corona
J'aurais pu aussi préciser que votre infrastructure doit également être à l'épreuve du coronavirus, mais pas grand risque de ce côté là, quoiqu'il ne faille pas confondre avec la bière Corona, qui, si renversée négligemment sur un serveur, peux infliger des dégâts regrettables.
Concrètement, dans le cadre d'un cluster de virtualisation, ça se traduit par quelques maximes de bon sens :
- On fait en sorte qu'une VM puisse être exécutée sur n'importe quel hyperviseur.
- N'importe quel opérateur doit être en mesure d'effectuer des opérations de base (et de comprendre ce qu'il fait) sans corrompre le schmilblick, à toute heure du jour ou de la nuit, à n'importe quel niveau de sobriété, et s'il est dans l'incapacité physique, il doit pouvoir les expliquer à quelqu'un qui a un clavier et qui tient debout.
- La symphonie technologique (terme pompeux de mon cru pour désigner les différentes technos qui collaborent, s'imbriquent et virevoltent avec grâce au grand bal des services) doit s'articuler autour de technos et protocoles indépendants, remplaçables, robustes et s'appuyant les uns sur les autres.
Que de belles résolutions en ce début d'année, c'est touchant. Alors pour retomber sur terre, on va parler du problème épineux de l'unicité des instances de VM.
Et bien oui, le problème se pose, car dans un cluster, on partage un certain nombre de ressources, ça tombe sous le sens. Dans notre cas, il s'agit du système de stockage. Comme on l'a déjà évoqué, chaque nœud du cluster doit pouvoir exécuter n'importe quelle VM. Mais le danger est grand, car si on ne met pas en place un certain nombre de mécanismes de régulation, on risque d'exécuter une VM à plusieurs endroit à la fois, et c'est extrêmement fâcheux. On risque de corrompre d'une part les systèmes de fichiers de la VM concernée, ce qui est déjà pénible, mais en plus, si on effectue des modifications de la structure de stockage partagé à tort et à travers, on risque d'anéantir l’ensemble du stockage du cluster, ce qui impactera l'ensemble du service. C'est bien plus que pénible.
La solution de stockage
La virtualisation
L'outil de gestion de machines invitées que je préfère est libvirt, développé par les excellents ingénieurs de Redhat. À mon sens c'est le seul gestionnaire de virtualisation qui a su proposer des fonctionnalités très pratiques sans se mettre en travers de la volonté de l'utilisateur. Les commandes sont toujours implicites, on sait toujours ce qui est fait, la documentation est bien remplie, les développeurs sont ouverts, et surtout, libvirt est agnostique sur la gestion des ressources, c'est à dire qu'il manipule des concepts simples qui permettent à l'opérateur de le coupler à ses propres solutions avec une grande liberté.
Voici une liste d'autres solutions, qui ne me correspondent pas :
- Proxmox : Il s'agit d'une de ces solutions qui misent sur le tout-en-un, et donc contraire à l'approche KISS. Cela dit, son approche multi-utilisateurs est très intuitive surtout quand on a pas de compétences poussées en virtualisation, du fait de la présence d'une interface web intuitive. Il s'agit d'une solution satisfaisante lorsqu'on souhaite utiliser un unique nœud mais dès lors qu'on construit un cluster, Proxmox fait intervenir des élément très compliqués qui peuvent vite se retourner contre vous lors de fausses manipulations qui peuvent vous sembler bénignes. De ce fait, sa difficulté d'utilisation et de maintenance augmente de façon spectaculaire, et c'est ce contraste que je lui reproche.
- oVirt : Il s'agit d'une solution également développée par Redhat, avec interface web conne proxmox et beaucoup (peut-être trop) de fonctionnalités, et qui utilise libvirt pour faire ses opérations. Cependant, comme j'ai du mal à voir ce qui est fait sous le capot, j'ai décidé de ne pas l'utiliser.
- Virtualbox : Du fait de l'omniprésence et de la disponibilité des tutoriels sur Virtualbox, cela aurait semblé être une bonne solution. Mais il y a plusieurs problèmes : en premier lieu cette solution a été conçue principalement autour de son interface graphique, et son interface en ligne de commande est assez pauvre. Ensuite, par Virtualbox on parle d'une part de l'outil de gestion de VM, mais également du moteur d'exécution lui même. Ce moteur nécessite l'installation d'un module tiers dans le noyau du système, et je préfère éviter cette pratique.
- VMware : Non là je trolle. #Sapucépalibre
Sous linux, la solution la plus logique pour faire de la virtualisation est QEMU + KVM. Comme je l'ai évoqué, il existe aussi le moteur Virtualbox que j'ai exclu pour les raisons que vous connaissez. On aurait pu aussi s'éloigner de la virtualisation au sens propre et se tourner vers des solutions plus légères, par exemple la mise en conteneurs de type LXC ou Docker.
Les conteneurs sont de petits animaux très gentils avec un petit chapeau sur la tête pour pouvoir se dire bonjour. Et ils sont très, très intelligents.
Les conteneurs sont très utiles lorsqu'il s'agit de lancer des programmes rapidement et d'avoir des ressources élastiques en fonction de l'utilisation. L'avantage des conteneurs est qu'ils sont très réactifs en début et en fin de vie, pour la simple raison qu'ils ne possèdent pas de noyau à lancer et donc ses processus sont directement lancés par l'hôte. En revanche, je compte lancer des machines virtuelles complètes, dotées de fonctions propres, parfaitement isolées de l'hôte, et qui vont durer pendant de longues périodes. Pour des services qui doivent durer, les conteneurs n'apportent rien d'autre que des failles de sécurité. Mais bon, c'est à la mode, vous comprenez...
Bon c'est entendu, partons sur libvirt ne demande pas grand chose pour lier une machine virtuelle à son stockage, ce qui fait qu'il est compatible avec beaucoup de façons de faire. En particulier, si votre stockage se présente sous la forme d'un périphérique en mode block dans votre /dev, libvirt saura en faire bon usage.
Le partitionnement
Au plus haut niveau pour le stockage des VM, je me suis tourné naturellement vers LVM. C'est la solution par excellence quand on cherche à gérer beaucoup de volumes modulables et élastiques, avec de très bonnes performances. Besoin d'un nouveau volume ? Hop, c'est fait en une commande. Le volume est trop petit ? Pas de problème, LVM peut modifier la taille de ses partitions sans avoir à s'inquiéter de la présence d'autres partitions avant ou après, LVM se débrouille comme un chef.
LVM s'articule autour de trois notions :
- Les LV (logical volumes) : Les partitions haut niveau qui seront utilisées par les VM.
- Les VG (volumes groups) : un VG est une capacité de stockage sur laquelle on va créer des LV.
- Les PV (physical volumes) : Les volumes qui sont utilisés pour créer des VG. Un VG peut utiliser plusieurs PV, en addition ou en réplication, de façon similaire au RAID.
Par défaut, un VG est local, c'est à dire conçu pour n'être utilisé que sur une seule machine. Ce n'est pas ce qu'on souhaite. On souhaite un VG commun à tous les nœuds, sur lequel se trouvent des LV qui, on le rappelle, ne sont utilisés que par un seul nœud à la fois. LVM nous permet de créer un tel VG partagé, en ajoutant un système de gestion de verrous.
Là encore, il y a beaucoup de façons de faire. Moi, je cherchais un moyen qui ne m'impose pas de mettre en place des technos qui sont très mises en valeur dans la littérature mais sur lesquelles je me suis cassé les dents, à l'installation comme au dépannage. Typiquement, je refusais catégoriquement de donner dans du Corosync/Pacemaker. J'ai déjà joué, j'ai perdu, merci, au revoir. Un jour peut-être vous vanterai-je dans un article les bienfaits de Corosync lorsque j'aurai compris le sens de la vie et obtenu mon prix Nobel de la paix. Ou bien depuis l'au-delà lors du jugement dernier lorsque les bons admins monterons au ciel et les mauvais descendront dans des caves obscures pour faire du Powershell ou se faire dévorer par les singes mutants qui alimentent en entropie les algorithmes de Google. En attendant, j'y touche pas même avec un bâton.
Une technique qui m'a attiré par sa simplicité et son bon sens fait intervenir la notion de sanlock : plutôt que de mettre en place une énième liaison réseau entre les différents nœuds et de paniquer au moindre cahot, on part du principe que de toute façon, quelle que soit la techno de stockage partagé utilisé, les nœuds ont tous en commun de pouvoir lire et écrire au mème endroit. Donc on va demander à LVM de réserver une infime portion du média pour y écrire quelles ressources sont utilisées, et avec quelles restrictions. Ainsi, les nœuds ne se marchent pas sur les câbles. Moi ça m'allait bien.

Une photo de groupe de l'équipe admin de mon ancien travail. On venait de changer de locaux.
D'ailleurs, à ce niveau de l'histoire, je dois dire que je ne suis pas peu fier. En effet, pour mettre au point cette infrastructure, j'ai été inspiré en grande partie par l'infrastructure utilisée dans une de mes anciennes entreprises, dans laquelle j'avais la fonction de singe savant, et je ne comprenais pas (et ne cherchais pas à comprendre) le fonctionnement de mon outil de travail. Après mon départ, quand j'ai cherché à comprendre, j'ai entretenu une correspondance courriel avec un de mes anciens référents techniques, qui a conçu cette infra et pour qui j'ai toujours eu beaucoup de respect.
Je lui avais demandé des infos sur le sanlocking, ce à quoi il m'a répondu :
Quand j'ai testé le sanlocking ça avait fonctionné, mais je suis pas allé plus loin. Mais ici on gère vraiment le locking à la main.
En effet, les VG de stockages étaient de simples VG locaux. Les métadonnées étaient individuellement verrouillées localement sur chaque nœud, et dès lors qu'on voulait provisionner une nouvelle VM, on devait lancer un script qui déverouillait les métadonnées sur le nœud de travail. Du coup, rien n'empêchait un autre nœud de faire la même chose, au risque d'avoir des modifications concurrentes et la corruption de l'univers. Donc, on était obligé de hurler à la cantonade dans l'open space dès qu'on touchait à quoi que ce soit. Si on avait de l'esprit, on aurait pu parler de screamlock à défaut de sanlock. De la même façon, on risquait à tout moment de lancer des VM à deux endroits à la fois !
En fait on passe petit à petit sur oVirt pour gérer ce cas là. Aujourd'hui sur notre cluster KVM "maison", rien ne nous empêche de démarrer x fois la même machine sur plusieurs hôtes et de corrompre son système de fichiers 😕️ C'est une des raisons de la bascule progressive vers oVirt.
Donc je suis fier de ne pas avoir eu à passer à oVirt pour faire ça. Libvirt est suffisamment simple et ouvert pour nous laisser faire ce qu'on veut et c'est ce que j'aime.
Le partage
Quel PV doit-on choisir pour notre cluster ? Il nous faut un machin partagé, d'une manière ou d'une autre. J'ai envisagé au moins trois solutions :
- Un LUN iSCSI depuis un SAN (aka. la solution optimale) : Un SAN est un serveur de stockage mettant à disposition des volumes (appelés LUN). Le stockage est donc géré par des appareils dédiés, qui se fichent complètement de la façon dont on utilise ses volumes ni sur combien de nœuds. Le SAN ne sait pas si ses volumes contiennent des systèmes de fichiers, et il ne bronchera pas du tout si vous corrompez leur contenu parce que vous êtes pas fichu de vous organiser. Le soucis avec les SAN, c'est leur coût qui fait souvent dans les cinq chiffres...
- Une réplication DRBD multimaster (aka. la solution du pauvre) : Si vous êtes comme moi et que les brousoufs ne surpopulent pas votre compte en banque, vous pouvez vous limiter à utiliser le stockage local de vos nœuds, que vous mettez en réplication multimater DRBD. De cette façon, chaque modification du volume sera instantanément répercuté sur l'autre nœud. L'avantage de cette solution est que le stockage est local, donc pour les accès en lecture on ne génère pas de trafic réseau. D'autre part, on a de facto une réplication de l'ensemble des données en cas de panne d'un nœud. Le soucis avec DRBD, c'est qu'il ne supporte, pour l'instant, que deux nœuds. D'un autre côté, comme on est pauvre, on a difficilement plus de deux nœuds de toute façon, mais cela empêche une mise à l'échelle horizontale dans l'immédiat. On peut se consoler en planifiant qu'on pourra passer sans trop d'efforts à la solution SAN quand les finances seront propices.
- D'autres protocoles plus lourds comme Ceph qui vous promettent la lune et des super fonctions haut niveau (aka. la mauvaise solution) : Attention danger, on rentre dans l'effroyable empire des machines à gaz : on sait pas trop ce que ça fait, ça bouffe des ressources sans qu'on sache pourquoi, et quand ça foire, si on a pas passé sa vie à en bouffer, on peut rien faire. Déjà, Ceph est une solution mise en avant par Proxmox, donc il y a déjà matière à se méfier. En plus, les fameuses fonctions haut niveau, comme le partitionnement, le modèle qu'on a choisit nous pousse à le gérer avec autre chose, ici LVM. Donc merci, mais non merci.
Notez que peu importe la solution que vous choisirez, comme il s'agit de stockage en réseau, il est fortement recommandé d'établir un réseau dédié au stockage, de préférence en 10 Gbps. Et malheureusement, les cartes réseau et les switchs 10 Gbps, c'est pas encore donné.
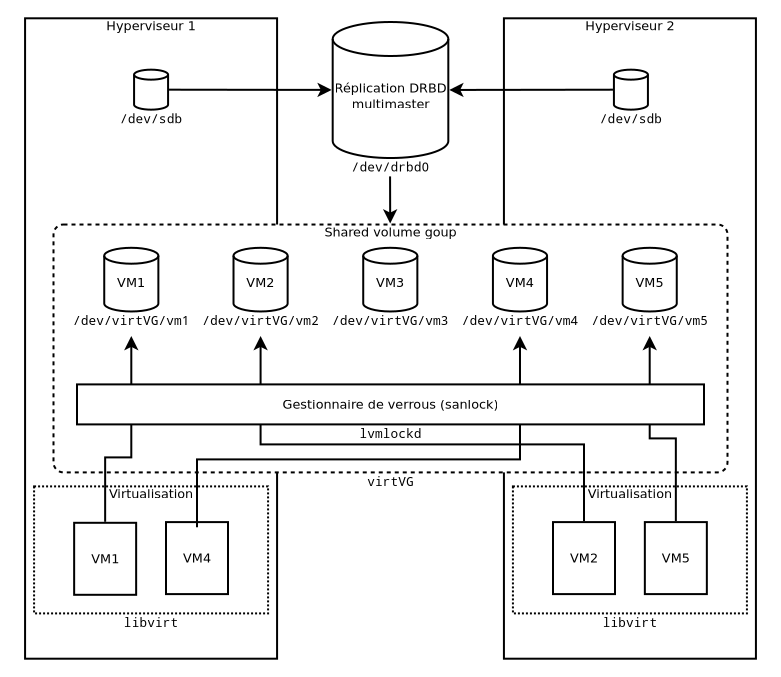
Schéma récapitulatif
La mise en œuvre
Lors de la phase de conception, on est parti du besoin haut niveau pour descendre au contraintes matérielles. Pour la mise en œuvre, on va cheminer dans l'autre sens.
DRBD
Comme je vous l'ai avoué, d'un point de vue budget infrastructure, j'appartiens à la catégorie des pauvres. J'ai donc du me rabattre sur la solution DRBD.
Sur chacun de mes deux nœuds, je dispose de volumes de capacité identique, répondant au nom de /dev/sdb.
Après avoir installé DRBD, il faut créer sur chacun des nœuds la ressource associés à la réplication, qu'on va nommer r0.
# /etc/drbd.d/r0.res
resource r0 {
meta-disk internal;
device /dev/drbd0;
disk /dev/sdb;
syncer { rate 1000M; }
net {
allow-two-primaries;
after-sb-0pri discard-zero-changes;
after-sb-1pri discard-secondary;
after-sb-2pri disconnect;
}
startup { become-primary-on both; }
on node1.mondomaine.net { address 10.0.128.1:7789; }
on node2.mondomaine.net { address 10.0.128.2:7789; }
}Quelques explications :
/dev/sdbest le périphérique de stockage qui va supporter DRBD./dev/drbd0sera le volume construit par DRBD- Les noms des nœuds doivent correspondre au nom complet de l'hôte (défini dans
/etc/hostname) et ne pointe pas obligatoirement vers l'adresse IP précisée, qui est souvent dans un réseau privé dédié au stockage.
Une fois que c'est fait, on peut passer à la création de la ressource sur les deux machines :
drbdadm create-md r0
systemctl enable --now drbdDRBD va ensuite initier une synchronisation initiale qui va prendre pas mal de temps. L'avancement est consultable en affichant le fichier /proc/drbd. À l'issue de cette synchronisation, vous constaterez que l'un des nœuds est secondaires. On arrange ça par la commande drbdadm primary r0 sur les deux hôtes (normalement uniquement sur l'hôte secondaire mais ça mange pas de pain de le faire sur les deux).
LVM
On a besoin d'installer le paquet de base de LVM ainsi que les outils pour gérer les verrous.
apt install lvm2 lvm2-lockd sanlockLa page du manuel de lvmlockd est extrêmement bien ficelée mais je sens que je vais quand même devoir détailler sinon ce serait céder à la paresse. On va donc reprendre les étapes de la même façon que la documentation.
On prends conscience que c'est bien le type sanlock qu'on veut utiliser. L'autre (dlm) est presque aussi nocive que Corosync.
Dans le fichier /etc/lvm.conf on modifie :
use_lvmlockd = 1
locking_type = 1Sur la version de LVM de la Debian actuelle (Buster), le paramètre locking_type est obsolète et n'a pas besoin d'être précisé.
Ne pas oublier de donner un numéro différent à chaque hôte dans le fichier /etc/lvm/lvmlocal.conf dans la rubrique local dans le paramètre host_id.
On active sur chaque hôte les services qui vont bien :
systemctl enable --now wdmd sanlock lvmlockdOn crée le VG partagé virtVG (sur un seul nœud) :
vgcreate --shared virtVG /dev/drbd0Puis enfin on active le VG sur tous les hôtes :
vgchange --lock-startVous pouvez dès à présent créer des LV. Pour vérifier que votre VG est bien de type partagé, vous pouvez taper la commande vgs -o+locktype,lockargs. Normalement vous aurez un résultat de ce genre :
VG #PV #LV #SN Attr VSize VFree LockType VLockArgs
virtVG 1 2 0 wz--ns 521,91g 505,66g sanlock 1.0.0:lvmlockDans la colonne Attr, le s final signifie shared, et vous pouvez voir dans la colonne LockType qu'il s'agit bien d'un sanlock.
Pour créer un LV de 8 Go qui s'appelle tintin :
node1:~# lvcreate -L 8g virtVG -n tintin
Logical volume "tintin" created.
node1:~# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
prout virtVG -wi------- 8,00g
test virtVG -wi------- 8,00g
tintin virtVG -wi-a----- 8,00gLe a de la commande Attr indique que le volume est activé. C'est sur cette notion d'activation qu'on va pouvoir exploiter le verrou. Pour en faire la démonstration, rendez-vous sur un autre hôte (on n'a qu'un seul autre hôte comme on est pauvre).
node2:~# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
prout virtVG -wi------- 8,00g
test virtVG -wi------- 8,00g
tintin virtVG -wi------- 8,00gNotez que tintin n'est pas activé ici, et on a d'ailleurs tout fait pour que l'activation n'ait lieu que sur un seul nœud à la fois. Voyons ce qui se passe si on essaye de l'activer :
node2:~# lvchange -ay virtVG/tintin
LV locked by other host: virtVG/tintin
Failed to lock logical volume virtVG/tintin.Cessez les applaudissements, ça m'embarrasse. Donc, pour l'utiliser sur le deuxième nœud il faut et il suffit de le désactiver sur le premier.
node1:~# lvchange -an virtVG/tintin
node1:~# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
prout virtVG -wi------- 8,00g
test virtVG -wi------- 8,00g
tintin virtVG -wi------- 8,00gEt sur le deuxième on retente :
node2:~# lvchange -ay virtVG/tintin
node2:~# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
prout virtVG -wi------- 8,00g
test virtVG -wi------- 8,00g
tintin virtVG -wi-a----- 8,00gMagie. Quand un volume est activé, libre à vous d'en faire un système de fichier, de le monter, de faire un dd dessus... Tous ce dont vous aurez besoin c'est du chemin du périphérique /dev/virtVG/tintin. Le plus probable dans le cadre de la virtualisation est qu'il va y être déployé une table de partition MBR ou GPT, auquel cas il faudra, si un jour vous souhaitez explorer ce LV autrement que depuis la VM, lire sa table de partition avec kpartx.
Virtualisation
On arrive presque à l'issue de la chaîne des technos. En fait, dès maintenant, libvirt est capable de créer des VM. Mais par contre, en l'état, vous devrez vous charger manuellement de l'activation des LV. C'est un peu fastidieux, surtout dans un milieu industriel.
D'un point de vue conceptuel, deux possibilités s'offrent à nous :
- On définit toutes les VM sur tous les hôtes (et bien sûr on ne démarre des VM que sur un seul hôte à la fois).
- On définit sur un hôte uniquement les VM que cet hôte a le droit d'exécuter pour l'instant
J'ai choisi la deuxième option pour des raisons de clarté, mais je n'exclue pas de passer à la première option dans le futur pour une raison ou une autre.
Il faut ensuite adopter une stratégie d'activation des LV. On peut en choisir entre ces deux là :
- Un hôte active les LV de toutes les VM qui sont définies sur lui.
- Un hôte active uniquement les LV des VM en cours d'exécution sur lui.
J'ai choisi la deuxième stratégie, car la première est incompatible avec l'option de définir toutes les VM sur tous les hôtes.
Selon cette deuxième stratégie, il y a trois opérations de base sur les VM qui nécessitent d'intervenir sur l'activation des LV :
- La mise en service
- L'arrêt
- La migration (le transfert d'une VM d'un hôte à un autre)
Pour la mise en service, il faut activer le volume (et donc poser un verrou) avant que la machine ait commencé à s'en servir. Pour l'arrêt, il faut désactiver le volume (et donc libérer le verrou) après que la machine ait fini de s'en servir. Pour la migration... c'est plus compliqué.
Pour la migration à froid, c'est à dire pendant que la machine est à l'arrêt, c'est facile : il faut activer le volume sur la machine cible avant la migration et le désactiver après. Pour la migration à chaud, c'est à dire pendant que la VM est en marche, je vous propose d'étudier la suite des états de la VM et du LV, avec en gras les événements et en italique les périodes :
- Avant l'instruction de migration : la VM est en marche sur l'hôte source, donc le LV associé doit être activé sur l'hôte source.
- Instruction de migration
- Entre l'instruction de migration et la migration effective : la VM est en marche sur l'hôte source, donc le LV associé doit être activé sur l'hôte source ; l'hôte cible vérifie qu'il peut accéder au LV, donc le LV doit être activé sur l'hôte cible.
- Migration effective
- Après la migration effective : la VM est en marche sur l'hôte cible, donc le LV associé doit être activé sur l'hôte cible.
Vous le voyez bien : à l'étape 3, il est nécessaire que le LV de la VM soit activé à la fois sur la source et sur la cible. Et là, ce pour quoi on s'est battu depuis le début de cet article vole en éclat, et notre beau château de carte est désintégré par une bourrasque de vent.
Mais non, il reste de l'espoir, car je ne vous ai pas encore tout dit.
En fait, par défaut, les verrous des LV sont exclusifs, mais il est aussi possible de poser un verrou partagé :
lvchange -asy virtVG/tintinLorsqu'un LV est activé avec un verrou partagé, n'importe quel autre hôte a la possibilité d'activer le même LV avec un verrou partagé. Il faudra attendre que tous les hôtes aient désactivé le LV (et donc libéré leurs verrous partagés) pour que le LV puisse à nouveau être activé avec un verrou exclusif.
Bien entendu, si on laisse un verrou partagé sur plusieurs hôtes pendant une longue période, il est probable qu'un opérateur négligeant finisse par commettre l'irréparable en lançant la VM en question alors qu'elle est déjà en marche ailleurs...
C'est pourquoi il faut absolument que les périodes d'usage des verrous partagés soient réduites au nécessaire, c'est à dire pendant la migration.
Heureusement, libvirt vous donne la possibilité de mettre en place des crochets, c'est à dire des scripts qui vont être automatiquement appelés par libvirt au moment où il lance ces opérations. L'emplacement du crochet dont on a besoin est /etc/libvirt/hooks/qemu.
Nouveau problème : en l'état actuel, en ce qui concerne la migration, libvirt invoque le crochet uniquement sur l'hôte cible, et uniquement avant la migration effective. Nous avons besoin qu'il invoque le crochet à trois autres reprises :
- Avant la migration effective, sur l'hôte source, pour permettre de muter le verrou exclusif en verrou partagé
- Après la migration effective, sur l'hôte source et l'hôte, pour permettre de libérer les deux verroux partagés, dans le cas d'une migration à froid
Dans le cas d'une migration à chaud, libvirt notifie de toute façon, à la source, l'arrêt de la VM et donc la libération du verrou quel qu'il soit, et sur la cible, le démarrage de la VM et donc la pose d'un verrou exclusif qui écraserait un éventuel verrou partagé.
J'ai remonté le problème aux ingénieurs de Redhat en charge de libvirt, ils sont en train de développer la solution (suivez le fil sur la mailing list). Je publierai mon script dès que ce problème sera réglé.
À propos de la configuration de libvirt, j'ai un dernier conseil qui me vient à l'esprit. Il ne sert pas à grand chose de configurer le VG en temps que pool de volume, au sens de libvirt. En vérité, on peut très bien démarrer une VM même si son volume est en dehors de tout pool défini dans libvirt. En plus, si le pool est en démarrage automatique, libvirt va activer tous les LV quand il va démarrer, ce qui va provoquer une erreur dans le cas d'un redémarrage d'un hôte dans un cluster en service.
Le seul avantage de définir un pool auquel je peux penser est que libvirt peut créer des LV sans commande LVM auxiliaire au moment de la création d'une VM. La belle affaire. Personnellement je provisionne déjà mes VM avec un outil auxiliaire qui s'appelle virt-builder, faisant partie de la très utile suite utilitaire libguestfs. Je vous la recommande, elle fera peut être l'objet d'un futur article.
J'ai déjà beaucoup trop parlé et ça m'a saoulé, alors maintenant je vais la fermer et dormir un peu.