Du dev et du monitoring : YaPLog
Bonjour à tous !
Aujourd'hui on va parler boulot, mais n'ayez pas peur, on parle du mien. Petite balade réseau et dev.
Ce que j'aime le plus avec mon stage courant, c'est les défis. J'ai 6 semaines pour réaliser un prototype et sa documentation, et je peux vous dire que c'est serré. À près de trois quarts du projet, faisons un point sur son avancement, ce qu'il reste à faire, les technos, etc.
Le cahier des charges
Le monitoring réseau c'est tout sauf un sujet original. Hyper intéressant, sa mise en pratique évolue au fur et à mesure que les outils, les pratiques, et les protocoles évoluent.
Vous vous demandez sûrement pourquoi je parle de développement dans ce cas. Il y a certes de nombreux programmes permettant de faire pas mal de choses. Voici pourquoi.
- La meilleure raison : je n'ai pas accès (question de contrat avec l'opérateur réseau) aux routeurs, et il faudrait que j'aie la main sur une centaine de routeurs ;
- la deuxième meilleure raison : on m'a demandé une tâche spécifique (du reporting quotidien, entre autres). Je ne dis pas que ce n'est pas possible avec un Nagios-Cacti ou un Munin, mais je n'aurais pas commencé ce qu'on m'a demandé (voir ce qui suit) dans le temps imparti ;
- une raison pratique : on ne change pas la configuration d'une centaine de routeurs à travers le monde en 40 jours. C'est à peine suffisant pour traverser un désert.
Que veut-on savoir ? La question initiale est "quand est-ce que ma ligne est saturée" ce qui est déjà visible sur les logs du FAI (Nagios-Cacti, exporté en petites images JPG) mais n'est pas suffisant pour plusieurs raisons :
- on n'a pas de système d'alerte (facile à mettre en œuvre) ;
- on n'a pas de données exploitables plus avant (l'image JPG, c'est pas beaucoup) ;
On veut donc savoir quand est-ce que la ligne est saturée. C'est-à-dire, a priori, quand est-ce que la ligne atteint sont débit maximal.
Le but suivant est de déterminer si une saturation est gênante. Cela comprend plusieurs facteurs :
- l'heure : une saturation entre 2h et 4h du mat' parce qu'on fait des backup, ça ne gêne personne (ça pourrait, mais pas dans ce cas) ;
- une saturation d'une seconde dans la journée n'est pas grave. De même, 250 saturations quasi-instantanées, réparties de 8h à 20h ne gênent pas le travail ;
Une fois qu'on a déterminé si une saturation est gênante, on veut savoir qui elle gêne et pourquoi, afin de voir si on peut faire quelque chose pour améliorer l'utilisation des ressources.
- Par exemple, lorsqu'un site est saturé, cela gêne-t-il 1 ou 50 personnes ? Dans le premier cas, la personne est peut-être trop gourmande en ressources, dans le second, le lien est peut-être mal dimensionné.
- Certains processus peuvent être automatisés la nuit, certaines pratiques changées : backup du travail pendant la pause de midi et la nuit, passer de FTP à rsync pour les backup, ou au moins un système incrémental plutôt que full
Implémentation
Comme je sens que vous êtes des warriors,

Un warrior, probablement.
je vous propose de rentrer dans le vif du sujet avec les détails techniques.
Unzip
Je pars avec une archive zip, gentiment déposée par mon FAI, dans laquelle il y a des logs au format nfcapd, défini par Cisco.
Nfdump
Nfcapd est un fichier binaire, pas très comestible pour l'œil humain. J'ai donc trouvé nfdump, un programme qui permet de transformer les logs binaires en texte ASCII. ça ressemble à peu près à ça :
2016-09-21 21:47:42.360 0.000 TCP 192.168.5.3:445 -> 192.168.5.249:56011 1 52 1csvify
C'est mieux, mais c'est toujours pas optimal. Il y a notamment trois problèmes :
- la taille du fichier ASCII par rapport au binaire nfcapd est importante, environ 9.5 fois plus ;
- le texte ASCII est très irrégulier, le nombre d'espaces est très variable ;
- sont inutiles :
- la flèche ;
- le protocole aussi dans la majorité des cas (si on fait des calculs de poids en octets) ;
- les ports, sauf éventuellement dans le cas d'un téléchargement, le port source pour déterminer le type de trafic (HTTP : 80, POP/IMAP, IRC : 6667/6697...) ;
- le "1" à la toute fin, qui désigne le nombre de flow, toujours à 1 dans mon cas, vu les options passées à nfdump.
J'ai donc créé un préparser en C (il s'agit en fait d'une spécification flex, puis flex génère le code C correspondant, à l'aide d'automates) (il y en a deux, l'un d'entre eux affiche des couleurs, utile pour visualiser, interdit pour l'utilisation en production, parce qu'il génère bien trop de caractères d'échappement).
En moyenne, mon préparser sort un fichier au format CSV qui fait 70% de la taille du fichier d'entrée, et est beaucoup plus normalisé. Il ne supprime cependant pas beaucoup d'informations (la flèche seulement).
Parse/Somme et plus si affinités
Maintenant qu'on s'est facilité la tâche, il ne reste plus qu'à analyser le tout.
C'est le but du programme C++ suivant, qui va itérer sur les entrées du CSV qu'on a produit, et ranger les paquets aux bons endroits.
Enfin, en théorie. Parce qu'on se retrouve devant quelques petits problèmes :
- Il y a des paquets qui on une durée de passage au travers du réseau nulle, et pour faire des graphs, c'est pas top. Il faut donc gérer cela.
- Même si le C/C++ est rapide, la partie lecture du fichier sur disque est très rapide, la partie traitement est lente, la partie écriture des résultats sur disque est rapide.
- On adopte donc l'architecture suivante pour le programme C++ :
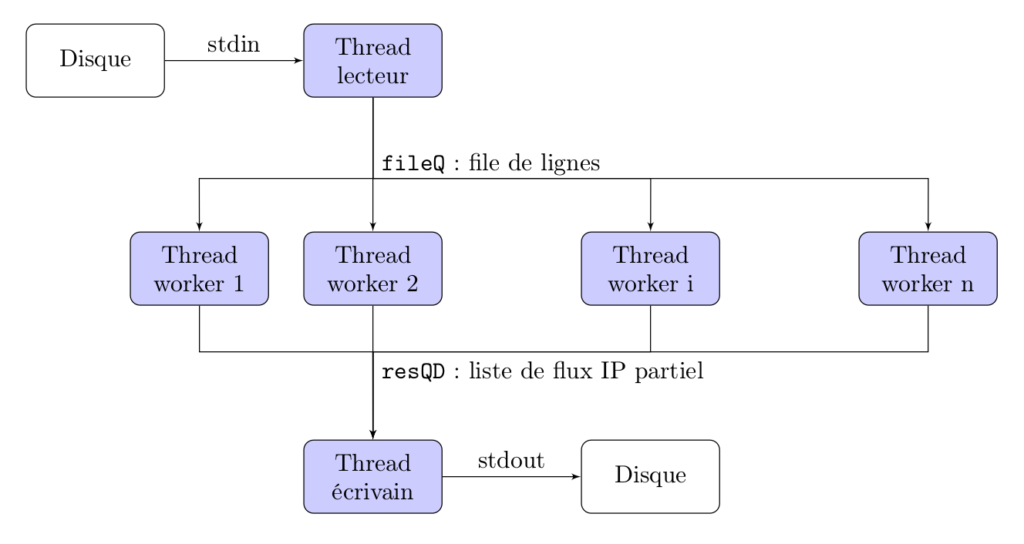
Architecture du programme C++
Le thread lecteur en haut lit depuis le disque à gauche, range les éléments dans la std::queue fileQ protégée par un mutex (fileQmutex, je suis d'une originalité à toute épreuve), tandis que les n threads workers vont travailler à générer la donnée, puis vont passer leur résultat à la liste de résultats resQD. Finalement le thread écrivain va réunir la liste de résultats, et l'écrire sur disque (à droite).
Comme vous le voyez, beaucoup de choses ont été faites, beaucoup de choix, et j'en passe de très nombreux (j'en mettrai en PS), et il reste beaucoup à accomplir, notamment :
- la doc : pour la contiuation du projet ;
- le manuel d'uilisation pour l'exploitation ;
- un How-to pour installer/améliorer le bidule ;
- utiliser la classe
Traffic()du programme C++ pour effectivement ranger les paquets dans des types deTraffic(par port pour le protocole, par IP source pour les utilisateurs les plus gourmands, par IP destination pour les serveurs les plus consultés/les plus consommateurs de ressource, et pour déterminer combien d'utilisateurs sont effectivement gênés lors d'une saturation).
Des graphs. For free.
Une fois que l'on a écrit le CSV, il ne reste qu'à faire le graph. le programme gnuplot peut faire ça très bien.
Un chef d'orchestre
Tout cela est opéré depuis un script bash.
Voilà, j'espère que ça vous a plu, si ça vous amuse, le projet est libre, disponible ici. Comme d'habitude n'hésitez pas à commenter et à bientôt !
Motius
PS : j'ai appris plein de choses, mais qui sont de l'ordre du détail pour ce projet, alors je vais en lister quelques unes ici :
- mes CPU aiment travailler de manière symétrique. quand je mets n workers, je gagne plus en pourcentage de vitesse en passant d'un nombre impair à un nombre pair. Les chiffres :
- de 1 à 2 CPU : 3.37 fois plus rapide (le programme n-multithread est plus lent que ne l'était le programme monothread équivalent si l'on ne met qu'un seul thread worker, n=1) ;
- de 2 à 3 CPU : 1.12 fois ;
- de 3 à 4 CPU : 1.67 fois ;
- les regex sont assez lentes, il y a potentiellement une bonne optimisation possible en bidouillant des C-strings au lieu des
std::stringdu C++ (le pré-parser C est beaucoup beaucoup plus rapide que le programme C++, aussi parce que son travail ne consiste qu'en des substitutions/suppressions), mais le temps de développement serait plus long, et le risque d'overflow/segfault possible.